
Une fois que vous avez migré vos données depuis Access vers SQL Server, vous disposez désormais d’une base de données client/serveur qui peut être une solution Azure locale ou Cloud hybride. Dans les deux cas, Access est désormais la couche présentation et SQL Server est la couche de données. À présent, c’est le moment idéal pour repenser les aspects de votre solution, notamment les performances de requête, la sécurité et la continuité d’activité. Vous pourrez ainsi améliorer et faire évoluer votre solution de base de données.
Pour un utilisateur Access, il peut sembler difficile de se familiariser pour la première fois avec la documentation SQL Server et Azure. Cela nécessite une visite guidée préalable qui abordera les aspects que vous jugez importants. Une fois que vous aurez terminé cette excursion, vous serez prêt à explorer les progrès en matière de technologie de base de données et serez ainsi paré pour un plus long voyage.
Contenu de cet article
|
Gestion des bases de données Soutien de la continuité d’activité Gestion des problèmes de confidentialité |
Requêtes et thématiques associées |
Types de données |
Divers |
Soutien de la continuité d’activité
Vous souhaitez que votre solution Access fonctionne de manière optimale, c’est-à-dire avec le minimum d’interruptions, mais vos options avec une base de données principale Access sont limitées. La sauvegarde de votre base de données Access est essentielle pour la protection de vos données, mais nécessite la déconnexion de vos utilisateurs. Cependant, des temps d’arrêt non planifiés peuvent survenir à cause de mises à niveau de maintenance matérielles/logicielles, de pannes de réseau ou de courant, de défaillances matérielles, de violations de la sécurité ou même de cyber-attaques. Pour réduire le temps d’arrêt et minimiser l’impact sur votre activité, vous pouvez sauvegarder une base de données SQL Server pendant son utilisation. De plus, SQL Server offre également des stratégies de haute disponibilité (HA) et de récupération d’urgence (DR). Ces deux technologies combinées sont appelées HADR. Pour plus d’informations, voir Continuité d’activité et récupération de base de données et Drive business continuity with SQL Server (e-book, en anglais).
Sauvegarde pendant l’utilisation
SQL Server utilise un processus de sauvegarde en ligne pouvant être exécuté pendant l’exécution de la base de données. Vous pouvez effectuer une sauvegarde complète, une sauvegarde partielle ou une sauvegarde de fichier. Une sauvegarde copie les données et journaux de transaction pour garantir une opération de restauration complète. En particulier dans une solution locale, tenez compte des différences entre les options de récupération simple et complète et la manière dont elles affectent la croissance du journal des transactions. Pour plus d’informations, voir Modèles de récupération.
La plupart des opérations de sauvegarde sont effectuées immédiatement, à l’exception de la gestion des fichiers et de la réduction des opérations de base de données. À l’inverse, si vous tentez de créer ou de supprimer un fichier de base de données alors qu’une opération de sauvegarde est en cours, l’opération échoue. Pour plus d’informations, voir Présentation de la sauvegarde.
HADR
Les deux techniques les plus courantes pour assurer une haute disponibilité et une continuité d’activité sont la mise en miroir et le regroupement. SQL Server intègre les technologies de mise en miroir et de regroupement avec des "Instances de cluster de basculement Always On" et des "Groupes de disponibilité Always On".
La mise en miroir est une solution de continuité au niveau de la base de données qui prend en charge le basculement quasi instantané en maintenant une base de données de secours, une copie complète ou un miroir de la base de données active sur un autre matériel. Elle peut fonctionner en mode synchrone (haute sécurité), dans lequel une transaction entrante est validée sur tous les serveurs en même temps, ou en mode asynchrone (haute performance), dans lequel une transaction entrante est validée dans la base de données active, puis, à un point prédéterminé, copiée sur le miroir. La mise en miroir est une solution au niveau de la base de données et fonctionne uniquement avec des bases de données qui utilisent le modèle de récupération complet.
Le regroupement est une solution au niveau du serveur qui combine les serveurs en un seul stockage de données qui recherche l’utilisateur comme une seule instance. Les utilisateurs se connectent à l’instance et n’ont jamais besoin de savoir quel serveur est actuellement actif dans l’instance. Si un serveur échoue ou doit être mis hors connexion à des fins de maintenance, l’expérience utilisateur ne change pas. Chaque serveur du cluster est contrôlé par le gestionnaire de cluster à l’aide d’une pulsation, de sorte qu’il détecte quand le serveur actif dans le cluster se déconnecte et tente de basculer vers le serveur suivant dans le cluster, même si un délai variable s’écoule pendant le changement.
Pour plus d’informations, voir Instances de cluster de basculement Always On et Groupes de disponibilité Always On : une solution de haute disponibilité et de récupération d’urgence.
Sécurité de SQL Server
Bien qu’il soit possible de protéger votre base de données Access à l’aide du Centre de gestion de la confidentialité et du chiffrement de la base de données, SQL Server dispose de fonctionnalités de sécurité plus avancées. Examinons les trois fonctionnalités qui sont présentées à l’utilisateur Access. Pour plus d’informations, voir Sécurisation de SQL Server.
Authentification de base de données
Il existe quatre méthodes d’authentification de base de données dans SQL Server, chacune pouvant être spécifiée dans une chaîne de connexion ODBC. Pour plus d’information, voir Créer un lien vers une base de données Azure SQL Server Database ou importer des données à partir de celle-ci. Chaque méthode présente ses avantages.
Authentification Windows intégrée Utilisez les informations d’identification Windows pour la validation par l’utilisateur, les rôles de sécurité et la limitation des utilisateurs aux fonctionnalités et données. Vous pouvez utiliser les informations d’identification de domaine et gérer facilement les droits d’utilisateur dans votre application. Si vous le souhaitez, entrez un Nom de principal du service (SPN). Pour plus d’informations, voir Choisir un mode d’authentification.
Authentification SQL Server Lors de leur premier accès à la base de données dans une session, les utilisateurs doivent se connecter avec des informations d'identification qui ont été paramétrées dans la base de données en entrant l’ID de connexion et le mot de passe. Pour plus d’informations, voir Choisir un mode d’authentification.
Authentification intégrée Azure Active Directory : connectez-vous à la base de données Azure SQL Server à l’aide d’Azure Active Directory. Lorsque vous avez configuré l’authentification Azure Active Directory, aucune connexion supplémentaire et le mot de passe n’est nécessaire. Pour en savoir plus sur ce sujet, consultez Utiliser l’authentification Azure Active Directory pour l’authentification auprès de SQL Database.
Authentification par mot de passe Active Directory : connectez-vous en utilisant les informations d’identification définies dans Azure Active Directory en entrant un nom d’utilisateur et un mot de passe. Pour en savoir plus sur ce sujet, consultez Utiliser l’authentification Azure Active Directory pour l’authentification auprès de SQL Database.
Conseil Utilisez la Détection de menaces pour recevoir des alertes sur l’activité anormale d’une base de données qui indique des menaces de sécurité potentielles sur une base de données Azure SQL Server. Pour plus d’informations, voir Détection de menaces de base de données SQL.
Sécurité de l’application
SQL Server dispose de deux fonctionnalités de sécurité au niveau de l’application desquelles vous pouvez profiter avec Access.
Masquage de données dynamiques Dissimulez les informations sensibles en les masquant à partir d’utilisateurs non privilégiés. Par exemple, vous pouvez masquer les numéros de sécurité sociale, partiellement ou en totalité.
 Un masque de données partiel |
 Un masque de données complet |
Plusieurs méthodes s’offrent à vous pour définir un masque de données que vous pouvez appliquer à différents types de données. Le masquage des données est piloté par les stratégies au niveau des tables et des colonnes pour un ensemble d’utilisateurs défini et est appliqué en temps réel pour les requêtes. Pour plus d’informations, voir Masquage de données dynamiques.
Sécurité de niveau ligne Vous pouvez contrôler l’accès à des lignes de base de données spécifiques contenant des informations sensibles basées sur les caractéristiques des utilisateurs à l’aide de la sécurité de niveau ligne. Le système de base de données applique ces restrictions d’accès et rend ainsi le système de sécurité plus fiable et robuste.

Il existe deux types de prédicats de sécurité :
-
Un prédicat de filtre filtre les lignes d’une requête. Le filtre est transparent, et l’utilisateur final n’est pas conscient du filtrage.
-
Un prédicat de bloc empêche toute action non autorisée et lève une exception si l’action ne peut pas être effectuée.
Pour plus d’informations, voir Sécurité de niveau ligne.
Protection des données avec chiffrement
Protégez les données au repos, en transit et en cours d’utilisation sans affecter les performances de la base de données. Pour plus d’informations, voir Chiffrement de SQL Server.
Chiffrement au repos Pour sécuriser les données personnelles contre les attaques de support hors connexion au niveau de la couche de stockage physique, utilisez le chiffrement au repos, également appelé chiffrement de données transparent (TDE). Cela signifie que vos données sont protégées, même si le support physique est volé ou mal supprimé. Le TDE effectue le chiffrement et le déchiffrement en temps réel des bases de données, sauvegardes et journaux des transactions sans qu’il soit nécessaire de modifier vos applications.
Chiffrement en transit Pour vous protéger contre l’espionnage et les attaques de type “Man-in-the-Middle“ – ou attaques de l’intercepteur –, vous pouvez chiffrer les données transmises sur le réseau. SQL Server prend en charge le protocole TLS (Transport Layer Security) 1.2 pour les communications hautement sécurisées. Le protocole TDS (Tabular Data Stream) est également utilisé pour protéger les communications sur les réseaux non approuvés.
Chiffrement utilisé sur le client Pour protéger les données personnelles en cours d’utilisation, “Toujours chiffré“ est la fonctionnalité recherchée. Les données personnelles sont chiffrées et décryptées par un pilote sur l’ordinateur client sans révéler les clés de chiffrement au moteur de base de données. Par conséquent, les données chiffrées sont visibles uniquement par les personnes responsables de la gestion de ces données, et non par d’autres utilisateurs hautement privilégiés qui ne doivent pas y accéder. En fonction du type de chiffrement sélectionné, l’option Toujours chiffré peut limiter certaines fonctionnalités de base de données, telles que la recherche, le regroupement et l’indexation de colonnes chiffrées.
Gestion des problèmes de confidentialité
Les problèmes de confidentialité sont si répandus que l’Union Européenne a défini des exigences légales par le biais du Règlement Général sur la Protection des Données (RGPD). Heureusement, un serveur SQL Server principal convient parfaitement pour répondre à ces exigences. Considérez l’implémentation du RGPD dans un Framework en trois étapes.

Étape 1 : Évaluer et gérer les risques de conformité
Le RGPD nécessite que vous identifiiez et inventoriez les informations personnelles que vous avez dans des tableaux et des fichiers. Il peut s’agir d’un nom, d’une photo, d’une adresse e-mail, d’informations bancaires, de publications sur les réseaux sociaux, d’informations médicales, voire d’une adresse IP.
Un nouvel outil, Découverte et Classification des Données SQL, intégré à SQL Server Management Studio, vous permet de découvrir, de classifier, d’étiqueter et de créer des rapports sur des données sensibles en appliquant deux métadonnées attributs aux colonnes :
-
Étiquettes Pour définir le niveau de confidentialité des données.
-
Types d’informations Pour fournir une granularité supplémentaire sur les types de données stockés dans une colonne.
Vous pouvez également utiliser la recherche en texte intégral, qui inclut l’utilisation des prédicats CONTAINS et FREETEXT, ainsi que des fonctions évaluées par l’ensemble de lignes telles que CONTAINSTABLE et FREETEXTTABLE, à utiliser avec l’instruction SELECT. La recherche en texte intégral vous permet de rechercher des mots, des combinaisons de mots ou des variantes d’un mot, tels que des synonymes ou des formes fléchies, dans des tableaux. Pour plus d’informations, voir Recherche en texte intégral.
Étape 2 : Protéger les informations personnelles
Le RGPD nécessite de sécuriser les informations personnelles et de limiter l’accès à celles-ci. En plus de suivre les étapes de base pour gérer l’accès à votre réseau et à vos ressources, telles que les paramètres de pare-feu, vous pouvez utiliser les fonctionnalités de sécurité de SQL Server pour contrôler l’accès aux données :
-
L’authentification SQL Server permet de gérer l’identité des utilisateurs et d’empêcher tout accès non autorisé.
-
Sécurité de niveau ligne pour limiter l’accès aux lignes d’une table en fonction de la relation entre l’utilisateur et ces données.
-
Masquage de données dynamiques pour limiter l’exposition aux données personnelles en les masquant à des utilisateurs non privilégiés.
-
Chiffrement pour assurer la protection des données personnelles pendant la transmission et le stockage et éviter la compromission des données, y compris côté serveur.
Pour plus d’informations, voir Sécurité de SQL Server.
Étape 3 : Répondre efficacement aux demandes
Le RGPD vous impose de conserver les enregistrements du traitement des données personnelles et de les rendre accessibles aux autorités de surveillance sur demande. Si des problèmes tels que la publication de données accidentelles se produisent, les contrôles de protection vous permettent de répondre rapidement. Les données doivent être disponibles rapidement lorsque la création de rapports est nécessaire. Par exemple, le RGPD nécessite qu’une violation de données personnelles soit signalée à l’autorité de surveillance "au plus tard 72 heures après en avoir eu connaissance."
SQL Server 2017 vous guide dans les tâches de création de rapports de plusieurs façons :
-
L’audit SQL Server vous permet de vous assurer qu’il existe des enregistrements permanents d’activités d’accès aux bases de données et de traitement. Il procède à un audit précis qui effectue le suivi des activités de base de données pour vous aider à comprendre et identifier les menaces potentielles, les abus présumés ou les violations de sécurité. Vous pouvez rapidement effectuer des analyses de données.
-
Les tables temporelles SQL Server sont des tables utilisateur à version de système conçues pour conserver un historique complet des modifications apportées aux données. Vous pouvez les utiliser pour créer des rapports et effectuer des analyses ponctuelles facilement.
-
L’évaluation de la vulnérabilité de SQL vous permet de détecter les problèmes de sécurité et d’autorisations. Lorsqu’un problème est détecté, vous pouvez également explorer les rapports d’analyse de la base de données pour trouver des actions à résoudre.
Pour plus d’informations, voir Create a platform of trust (livre électronique, en anglais) et Journey to GDPR Compliance (en anglais).
Création de captures instantanées de base de données
Un instantané de base de données est un affichage statique en lecture seule d’une base de données SQL Server à un moment donné. Bien que vous puissiez copier un fichier de base de données Access pour créer une capture instantanée de base de données, Access ne possède pas de méthodologie intégrée comme SQL Server. Vous pouvez utiliser un instantané de base de données pour écrire des rapports basés sur les données au moment de la création de l’instantané de base de données. Vous pouvez également utiliser un instantané de base de données pour conserver un historique de données. Utilisez par exemple un instantané pour chaque trimestre financier afin de garder une trace de vos rapports de fin de période. Nous vous recommandons les bonnes pratiques suivantes :
-
Nommer l’instantané Chaque instantané de base de données requiert un nom de base de données unique. Ajoutez au nom l’objet et la période en question pour faciliter l’identification. Par exemple, pour faire un instantané de la base de données AdventureWorks trois fois par jour à intervalles de 6 heures entre 6 heures et 18 heures sur la base d’une horloge de 24 heures, nommez-le AdventureWorks_instantané_0600, AdventureWorks_instantané_1200 et AdventureWorks_instantané_1800.
-
Limiter le nombre d’instantanés Chaque instantané de base de données est conservé jusqu’à sa suppression explicite. Comme chaque capture instantanée continuera à croître, vous devriez peut-être économiser de l’espace disque en supprimant l’ancien instantané après avoir créé un nouvel instantané. Par exemple, si vous créez des rapports quotidiens, conservez l’instantané de base de données pendant 24 heures, puis supprimez-le et remplacez-le par un nouveau.
-
Connectez-vous au bon instantané Pour utiliser une capture instantanée de base de données, le serveur frontal d’Access doit déterminer l’emplacement correct. Lorsque vous remplacez une capture instantanée par une nouvelle, vous devez rediriger Access vers la nouvelle capture instantanée. Ajoutez une logique au serveur frontal Access pour vérifier que vous vous connectez au bon instantané de base de données.
Pour créer un instantané de base de données, procédez comme suit :
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Pour plus d’informations, voir Instantanés de base de données (SQL Server).
Contrôle d’accès concurrentiel
Lorsque plusieurs personnes essaient de modifier les données d’une base de données en même temps, un système de contrôles est nécessaire afin que les modifications apportées par une personne ne perturbent pas celles d’une autre personne. Ce mécanisme est appelé contrôle d’accès concurrentiel et il existe deux stratégies de verrouillage de base : pessimistes et optimistes. Le verrouillage peut empêcher les utilisateurs de modifier les données d’une manière qui affecte les autres utilisateurs. Le verrouillage permet également d’assurer l’intégrité des bases de données, en particulier avec des requêtes qui pourraient produire des résultats inattendus. Il existe des différences importantes dans la façon dont Access et SQL Server implémentent ces stratégies de contrôle d’accès concurrentiel.
Dans Access, la stratégie de verrouillage par défaut est optimiste et autorise la propriété du verrouillage à la première personne qui essaye d’écrire dans un enregistrement. Access affiche la boîte de dialogue Conflit d’écriture à l’autre personne qui essaie d’écrire dans le même enregistrement en même temps. Pour résoudre le conflit, l’autre utilisateur peut enregistrer l’enregistrement, le copier dans le presse-papiers ou abandonner les modifications.
Vous pouvez également utiliser la propriété RecordLocks pour modifier la stratégie de contrôle d’accès concurrentiel. Cette propriété affecte les formulaires, les rapports et les requêtes et offre trois paramètres :
-
Aucun Dans un formulaire, les utilisateurs peuvent essayer de modifier simultanément le même enregistrement, mais la boîte de dialogue Conflit d’écriture peut s’afficher. Dans un rapport, les enregistrements ne sont pas verrouillés lorsque le rapport est en cours d’affichage en tant qu’aperçu ou en cours d’impression. Dans une requête, les enregistrements ne sont pas verrouillés lorsque la requête est en cours d’exécution. Il s’agit de la méthode Access pour implémenter le verrouillage optimiste.
-
Général Tous les enregistrements dans la table ou requête sous-jacentes sont verrouillés quand le formulaire est ouvert en mode Formulaire ou en mode Feuille de données, lorsque le rapport est en cours d’affichage en tant qu’aperçu ou en cours d’impression, ou pendant l’exécution de la requête. Les utilisateurs peuvent lire les enregistrements pendant le verrouillage.
-
Enr modifié Pour les formulaires et les requêtes, une page d’enregistrements est verrouillée dès qu’un utilisateur commence à modifier un champ dans l’enregistrement, et reste verrouillée jusqu’à ce que l’utilisateur passe à un autre enregistrement. Par conséquent, un enregistrement ne peut être modifié que par un seul utilisateur à la fois. Il s’agit de la méthode Access pour implémenter le verrouillage pessimiste.
Pour plus d’informations, voir Boîte de dialogue Conflit d’écriture et Propriété RecordLocks.
Dans SQL Server, le contrôle d’accès concurrentiel fonctionne de la manière suivante :
-
Pessimiste Une fois qu’un utilisateur a effectué une action qui provoque l’application d’un verrou, les autres utilisateurs ne peuvent pas effectuer d’actions qui pourraient entrer en conflit avec le verrouillage tant que le propriétaire ne l’a pas désactivé. Ce contrôle d’accès concurrentiel est principalement utilisé dans les environnements où les données sont souvent soumises à des conflits.
-
Optimiste Dans le cas du contrôle d’accès concurrentiel optimiste, les utilisateurs ne verrouillent pas les données lorsqu’ils les lisent. Lorsqu’un utilisateur met à jour des données, le système vérifie si un autre utilisateur a modifié les données après leur lecture. Si un autre utilisateur a mis à jour les données, une erreur est générée. En règle générale, l’utilisateur qui reçoit l’erreur annule la transaction et redémarre. Ce contrôle d’accès concurrentiel est principalement utilisé dans les environnements où les données sont peu soumises à des conflits.
Vous pouvez spécifier le type de contrôle d’accès concurrentiel en sélectionnant plusieurs niveaux d’isolation des transactions, qui définissent le niveau de protection de la transaction contre les modifications apportées par d’autres transactions à l’aide de l’instruction SET TRANSACTION :
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Niveau d’isolation |
Description |
|
Lecture non validée |
Les transactions sont isolées uniquement pour s’assurer que les données physiquement endommagées ne sont pas lues. |
|
Lecture validée |
Les transactions peuvent lire les données déjà lues par une autre transaction sans attendre la fin de la première transaction. |
|
Lecture renouvelée |
Des verrous de lecture et d’écriture se produisent sur les données sélectionnées jusqu’à la fin de la transaction, mais des lectures fantômes peuvent se produire. |
|
Capture instantanée |
Utilise la version de ligne pour fournir une cohérence de lecture au niveau des transactions. |
|
Sérialisable |
Les transactions sont complètement isolées les unes des autres. |
Pour plus d’informations, voir Guide de verrouillage des transactions et de contrôle de version de ligne.
Amélioration de la performance des requêtes
Une fois que vous disposez d’une requête de transfert Access opérationnelle, tirez parti des méthodes sophistiquées utilisées par SQL Server pour optimiser l’exécution de la requête.
Contrairement à une base de données Access, SQL Server fournit des requêtes parallèles pour optimiser l’exécution de la requête et les opérations d’indexation pour les ordinateurs qui ont plusieurs microprocesseurs (CPU). Étant donné que SQL Server peut effectuer une opération de requête ou d’indexation en parallèle à l’aide de plusieurs threads de travail système, l’opération peut être effectuée de façon rapide et efficace.
Les requêtes constituent un élément essentiel pour améliorer les performances globales de votre solution de base de données. Les requêtes incorrectes s’exécutent indéfiniment et expirent, et utilisent des ressources telles que les processeurs, la mémoire et la bande-passante. Cela entrave la disponibilité des informations d’activité importantes. Même une seule requête incorrecte peut occasionner des problèmes de performances graves pour votre base de données.
Pour plus d’informations, voir Faster querying with SQL Server (e-book, en anglais).
Optimisation des requêtes
Plusieurs outils fonctionnent ensemble pour vous aider à analyser les performances d’une requête et l’améliorer : Optimiseur de requête, plans d’exécution et magasin de requête.
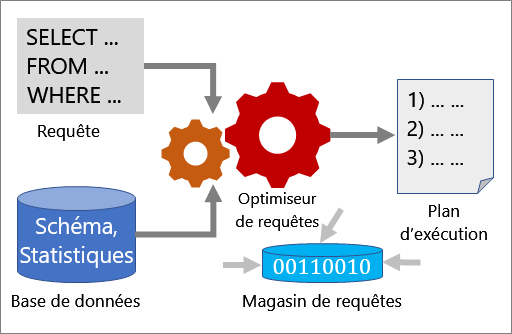
Optimiseur de requêtes
L’optimiseur de requête est l’un des composants les plus importants de SQL Server. Utilisez l’optimiseur de requête pour analyser une requête et déterminer la méthode la plus efficace pour accéder aux données souhaitées. L’entrée de l’optimiseur de requête se compose de la requête, du schéma de base de données (définitions de tables et d’index) et de statistiques de base de données. La sortie de l’optimiseur de requête est un plan d’exécution.
Pour plus d’informations, voir L’optimiseur de requêtes de SQL Server.
Plan d’exécution
Un plan d’exécution est une définition qui séquence les tables sources pour accéder aux données de chaque table et séquence les méthodes utilisées pour extraire ces données. L’optimisation est le processus de sélection d’un plan d’exécution parmi de nombreux autres plans possibles. Chaque plan d’exécution possible dispose d’un coût associé à la quantité de ressources de calcul utilisées et l’optimiseur de requête choisit celui dont le coût estimé est le plus faible.
SQL Server doit également s’adapter dynamiquement aux conditions variables de la base de données. Les régressions dans les plans d’exécution de requête peuvent considérablement affecter les performances. Certaines modifications apportées à une base de données peuvent entraîner un plan d’exécution inefficace ou non valide, en fonction du nouvel état de la base de données. SQL Server détecte les modifications qui invalident un plan d’exécution et marque le plan comme non valide.
Un nouveau plan doit ensuite être recompilé pour la prochaine connexion qui exécute la requête. Les conditions qui invalident un plan sont les suivantes :
-
Les modifications apportées à une table ou à une vue référencée par la requête (ALTER TABLE et ALTER VIEW).
-
Les modifications apportées aux index utilisés par le plan d’exécution.
-
Les mises à jour sur les statistiques utilisées par le plan d’exécution, générées de manière explicite à partir d’une instruction comme UPDATE STATISTICS, ou automatiquement.
Pour plus d’informations, voir Plans d’exécution.
Magasin de requêtes
Le magasin de requêtes offre un aperçu du choix du plan d’exécution et des performances. Il simplifie la résolution des problèmes de performance en vous aidant à trouver rapidement les différences de performances provoquées par les modifications du plan d’exécution. Le magasin de requêtes collecte des données de télémétrie, telles que l’historique des requêtes, plans, statistiques d’exécution et statistiques d’attente. Utilisez l’instruction ALTER DATABASE pour implémenter le Magasin de requêtes :
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Pour plus d’informations, voir Surveillance des performances à l’aide du Magasin de requêtes.
Correction automatique du plan
La méthode la plus simple pour améliorer les performances de requête consiste peut-être à utiliser la Correction automatique du plan, une fonctionnalité disponible avec Azure SQL Database. Il vous suffit de l’activer et de la laisser s’exécuter. Elle effectue une surveillance et une analyse continues du plan d’exécution, détecte les plans d’exécution problématiques et résout automatiquement les problèmes de performances. En coulisses, la Correction automatique du plan utilise une stratégie en quatre étapes d’apprentissage, d’adaptation, de vérification et de répétition.
Pour plus d’informations, voir Paramétrage automatique.
Traitement adaptatif des requêtes
Vous pouvez également obtenir des requêtes plus rapides en effectuant la mise à niveau vers SQL Server 2017, qui inclut une nouvelle fonctionnalité appelée traitement adaptatif des requêtes. SQL Server ajuste les choix de plan de requête en fonction des caractéristiques d’exécution.
L’estimation de la cardinalité représente approximativement le nombre de lignes traitées à chaque étape d’un plan d’exécution. Les estimations incorrectes peuvent entraîner un ralentissement du temps de réponse aux requêtes, une utilisation inutile des ressources (mémoire, processeur et E/S), ainsi qu’une réduction du débit et de l’accès concurrentiel. Trois techniques sont utilisées pour s’adapter aux caractéristiques de la charge de travail des applications :
-
Commentaires d’allocation de mémoire en Mode Batch Les estimations de cardinalité médiocres peuvent entraîner la “propagation vers le disque“ des requêtes ou utiliser une trop grande quantité de mémoire. SQL Server 2017 ajuste les allocations de mémoire sur la base des commentaires d’exécution, supprime les propagations vers le disque et améliore l’accès concurrentiel pour les requêtes répétées.
-
Jointures adaptatives en Mode Batch Les jointures adaptatives sélectionnent dynamiquement un type de jointure interne plus performant (jointures de boucles imbriquées, jointures fusionnées ou jointures de hachage) au moment de l’exécution, sur la base de lignes d’entrée réelles. Par conséquent, un plan peut basculer dynamiquement vers une meilleure stratégie de jointure pendant l’exécution.
-
Exécution imbriquée Les fonctions table de plusieurs instructions sont traditionnellement considérées comme une boîte noire par le traitement des requêtes. SQL Server 2017 peut mieux estimer le nombre de lignes pour améliorer les opérations en aval.
Vous pouvez faire en sorte que les charges de travail soient automatiquement éligibles au traitement de requête adaptatif en activant un niveau de compatibilité de 140 pour la base de données :
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Pour plus d’informations, voir Traitement intelligent des requêtes dans les bases de données SQL.
Méthodes de requêtes
Dans SQL Server, plusieurs méthodes s’offrent à vous pour effectuer des requêtes, et chacune présente ses avantages. Pour choisir la meilleure pour votre solution Access, vous devez connaître chacune d’entre elles. La meilleure façon de créer vos requêtes TSQL est de les modifier et de les tester de façon interactive à l’aide de l'éditeur Transact-SQL SQL Server Management Studio (SSMS) qui contient des informations IntelliSense qui vous aideront à sélectionner les mots clés appropriés et à vérifier les erreurs de syntaxe.
Vues
Dans SQL Server, une vue est semblable à une table virtuelle dans laquelle les données d’affichage proviennent d’une ou plusieurs tables ou d’autres vues. Toutefois, les vues sont référencées comme des tables dans les requêtes. Les vues peuvent masquer la complexité des requêtes et contribuer à la protection des données en limitant l’ensemble de lignes et de colonnes. Voici un exemple de vue simple :
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Pour des performances optimales et modifier les résultats de vues, créez une vue indexée qui est conservée dans la base de données comme une table et de la même manière, dispose d’un espace de stockage alloué et peut être interrogée comme n’importe quelle table. Pour l’utiliser dans Access, créez un lien vers la vue de la même façon que vous créez un lien vers une table. Voici un exemple de vue indexée :
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Toutefois, il existe des restrictions. Vous ne pouvez pas mettre à jour les données si plusieurs tables de base sont affectées ou si la vue contient des fonctions d’agrégation ou une clause DISTINCT. Si SQL Server renvoie un message d’erreur indiquant qu’il ne sait pas quel enregistrement supprimer, vous devrez peut-être ajouter un déclencheur de suppression dans la vue. Enfin, vous ne pouvez pas utiliser la clause ORDER BY comme vous pouvez le faire avec une requête Access.
Pour plus d’informations, voir Vues et Créer des vues indexées.
Procédures stockées
Une procédure stockée est un groupe d’une ou plusieurs instructions TSQL qui acceptent des paramètres d’entrée, renvoient des paramètres de sortie et indiquent la réussite ou l’échec d’une valeur d’état. Ils agissent comme une couche intermédiaire entre le serveur frontal Access et le serveur SQL Server principal. Une procédure stockée peut être aussi simple qu’une instruction SELECT ou aussi complexe qu’un programme. Voici un exemple :
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Lorsque vous utilisez une procédure stockée dans Access, elle renvoie généralement un jeu de résultats à un formulaire ou à un rapport. Elle peut toutefois effectuer d’autres actions qui ne renvoient pas de résultats, telles que des instructions DDL ou DML. Lorsque vous utilisez une requête directe, assurez-vous d’avoir correctement défini la propriété Renvoie des enregistrements.
Pour plus d’informations, voir Procédures stockées.
Expressions de tables communes
Une expression CTE (Common table expression) s’apparente à une table temporaire qui génère un jeu de résultats nommé. Elle existe uniquement pour l’exécution d’une seule requête ou instruction DML. Une CTE est construite dans la même ligne de code que l’instruction SELECT ou l’instruction DML qui l’utilise, tandis que la création et l’utilisation d’une table ou d’une vue temporaire sont généralement un processus en deux étapes. Voici un exemple :
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Une CTE présente plusieurs avantages, dont les suivants :
-
Étant donné que les CTE sont transitoires, vous n’êtes pas obligé de les créer en tant qu’objets de base de données permanents de la même façon que les vues.
-
Vous pouvez référencer la même CTE plusieurs fois dans une requête ou une instruction DML, ce qui simplifie la gestion de votre code.
-
Vous pouvez utiliser des requêtes qui font référence à une CTE pour définir un curseur.
Pour plus d’informations, voir WITH common_table_expression.
Fonctions définies par l’utilisateur
Une fonction définie par l’utilisateur (FDU) permet d’effectuer des requêtes et des calculs, et de renvoyer des valeurs scalaires ou des jeux de résultats de données. Il s’agit de fonctions similaires à celles des langages de programmation et acceptent des paramètres, effectuent une action telle qu’un calcul complexe et renvoient le résultat de cette action sous la forme d’une valeur. Voici un exemple :
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Une FDU présente certaines limites. Par exemple, elle ne peut pas utiliser certaines fonctions système non déterministes, effectuer des instructions DML ou DDL, ou effectuer des requêtes SQL dynamiques.
Pour plus d’informations, voir Fonctions Définies par l’Utilisateur.
Ajout de clés et d’index
Quel que soit le système de base de données que vous utilisez, les clés et index vont de pair.
Clés
Dans SQL Server, veillez à créer des clés primaires pour chaque table et des clés étrangères pour chaque table liée. La fonctionnalité équivalente de SQL Server au type de données Access NuméroAuto est la propriété IDENTITY, qui peut être utilisée pour créer des valeurs de clé. Une fois que vous avez appliqué cette propriété à une colonne numérique, elle se transforme en lecture seule et est gérée par le système de base de données. Lorsque vous insérez un enregistrement dans une table qui contient une colonne IDENTITY, le système incrémente automatiquement la valeur de la colonne identité de 1 en partant de 1, mais vous pouvez contrôler ces valeurs avec des arguments.
Pour plus d’informations, voir CREATE TABLE (Transact-SQL) IDENTITY (propriété).
Index
Comme toujours, la sélection d’index est un acte d’équilibrage entre la vitesse de requête et le coût de mise à jour. Dans Access, vous avez un type d’index, mais dans SQL Server, vous en avez douze. Heureusement, vous pouvez utiliser l’optimiseur de requête pour choisir la version d’index la plus efficace. Dans Azure SQL, vous pouvez utiliser la gestion automatique des index (fonctionnalité de réglage automatique) qui recommande l’ajout ou la suppression d’index. Contrairement à Access, vous devez créer vos propres index pour les clés étrangères dans SQL Server. Vous pouvez également créer des index sur une vue indexée afin d’améliorer les performances de la requête. L’inconvénient d’une vue indexée est un traitement accru lorsque vous modifiez des données dans les tables de base de la vue, car la vue doit également être mise à jour. Pour plus d’informations, voir Guide de conception et d’architecture d’index SQL Server et Index.
Réalisation de transactions
L’exécution d’un processus de transaction en ligne (OLTP) est difficile dans Access, mais est relativement facile avec SQL Server. Une transaction est une unité de travail unique qui valide toutes les modifications apportées aux données en cas d’aboutissement, mais annule les modifications en cas d’échec. Une transaction doit avoir quatre propriétés, souvent appelées ACID :
-
Atomicité Une transaction doit être une unité de travail atomique ; toutes ses modifications de données sont effectuées ou aucune n’est effectuée.
-
Cohérence Lorsque vous avez terminé, une transaction doit laisser toutes les données dans un état cohérent. Cela signifie que toutes les règles d’intégrité des données sont appliquées.
-
Isolation Les modifications apportées par les transactions concurrentes sont isolées de la transaction actuelle.
-
Durabilité Une fois qu’une transaction est terminée, les modifications sont permanentes même en cas de panne système.
Une transaction permet d’assurer l’intégrité des données (par exemple, retrait d’espèces à un guichet automatique ou dépôt automatique d’un salaire). Vous pouvez effectuer des transactions de portée explicite, implicite ou de série. Voici deux exemples TSQL :
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Pour plus d'informations, voir Transactions.
Utilisation de contraintes et de déclencheurs
Toutes les bases de données disposent de moyens pour maintenir l’intégrité des données.
Contraintes
Dans Access, l’intégrité référentielle est appliquée dans une relation de table via une clé étrangère (paire de clés primaires, mises à jour et suppressions en cascade) et des règles de validation. Pour plus d’informations, voir Guide sur les relations entre les tables et Restreindre l’entrée de données à l’aide de règles de validation.
Dans SQL Server, vous utilisez les contraintes UNIQUE et CHECK, qui sont des objets de base de données qui appliquent l’intégrité des données dans les tables SQL Server. Pour vérifier qu’une valeur est valide dans une autre table, utilisez une contrainte de clé étrangère. Pour vérifier qu’une valeur de colonne se trouve dans une plage spécifique, utilisez une contrainte de validation. Ces objets constituent votre première ligne de défense et sont conçus pour fonctionner de manière efficace. Pour plus d’informations, voir Contraintes uniques et contraintes de validation.
Déclencheurs
Access ne possède pas de déclencheur de base de données. Dans SQL Server, vous pouvez utiliser des déclencheurs pour appliquer des règles d’intégrité des données complexes et exécuter cette logique métier sur le serveur. Un déclencheur de base de données est une procédure stockée qui s’exécute lorsque des actions spécifiques se produisent dans une base de données. Le déclencheur est un événement, tel que l’ajout ou la suppression d’un enregistrement dans une table, qui déclenche, puis exécute la procédure stockée. Bien qu’une base de données Access puisse garantir l’intégrité référentielle lorsqu’un utilisateur tente de mettre à jour ou de supprimer des données, SQL Server dispose d’un groupe de déclencheurs sophistiqués. Par exemple, vous pouvez programmer un déclencheur pour supprimer des enregistrements en bloc et assurer l’intégrité des données. Vous pouvez même ajouter des déclencheurs à des tables et des vues.
Pour plus d’informations, voir Déclencheurs DML, Déclencheurs DDL et Designing a T-SQL trigger (en anglais).
Utilisation des colonnes calculées
Dans Access, vous créez une colonne calculée en l’ajoutant à une requête et en créant une expression, comme par exemple :
Extended Price: [Quantity] * [Unit Price]
Dans SQL Server, la fonctionnalité équivalente est appelée colonne calculée. Il s’agit d’une colonne virtuelle qui n’est pas stockée physiquement dans la table, sauf si la colonne est marquée comme PERSISTED. À l’instar d’une colonne calculée, une colonne calculée utilise des données d’autres colonnes dans une expression. Pour créer une colonne calculée, ajoutez-la à une table. Par exemple :
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Pour plus d’informations, voir Spécifier les colonnes calculées dans une table.
Horodatage de vos données
Vous pouvez parfois ajouter un champ de table pour enregistrer un horodatage lors de la création d’un enregistrement afin de consigner l’entrée de données. Dans Access, vous pouvez simplement créer une colonne de date avec la valeur =Now() par défaut. Pour enregistrer une date ou une heure dans SQL Server, utilisez le type de données datetime2 avec la valeur SYSDATETIME() par défaut.
Remarque Évitez la confusion de « rowversion» en ajoutant un horodatage ou « timestamp » à vos données. Le mot clé timestamp est synonyme de rowversion dans SQL Server, mais vous devez utiliser le mot clé rowversion. Dans SQL Server, rowversion est un type de données qui présente automatiquement des nombres binaires uniques générés automatiquement dans une base de données, et est généralement utilisé comme mécanisme d’horodatage des lignes d’une table. Toutefois, le type de données rowversion n’est qu’un nombre incrémentiel, il ne conserve pas de date ou d’heure et n’est pas conçu pour l’horodatage d’une ligne.
Pour plus d’informations, voir rowversion. Pour plus d’informations sur l’utilisation de rowversion pour minimiser les conflits d’enregistrements, voir Migrer une base de données Access vers SQL Server.
Gestion des objets de grande taille
Dans Access, vous gérez des données non structurées, telles que des fichiers, des photos et des images, en utilisant le Type de données Pièce jointe. Dans la terminologie SQL Server, les données non structurées sont appelées BLOB (objet binaire volumineux) et plusieurs méthodes s’offrent à vous pour les utiliser :
FILESTREAM Utilise le type de données varbinary(max) pour stocker les données non structurées sur le système de fichiers plutôt que la base de données. Pour plus d’informations, voir Accéder aux données FILESTREAM avec Transact-SQL.
FileTable Stocke les blobs dans les tables spéciales nommées FileTables et offre une compatibilité avec les applications Windows comme si elles étaient stockées dans le système de fichiers et sans apporter de modifications à vos applications clientes. FileTable nécessite l’utilisation de FILESTREAM. Pour plus d’informations, voir FileTables.
Magasin d’objets BLOB distant (RBS) Stocke les objets BLOB dans des solutions de stockage de marchandises plutôt que directement sur le serveur. Cela permet de gagner de l’espace et de réduire les ressources matérielles. Pour plus d’informations, voir Données blob (Binary Large Object).
Travailler avec des données hiérarchiques
Bien que les bases de données relationnelles telles qu’Access soient très flexibles, l’utilisation de relations hiérarchiques constitue une exception et nécessite souvent des instructions SQL ou du code complexes. Voici quelques exemples de données hiérarchiques : une structure organisationnelle, un système de fichiers, une taxonomie de termes linguistiques et un graphique de liens entre pages Web. SQL Server dispose d’un type de données intégré hierarchyid et d’un groupe de fonctions hiérarchiques permettant de stocker, interroger et gérer facilement des données hiérarchiques.
Pour plus d’informations, voir Données hiérarchiques et Didacticiel : Utiliser le type de données hierarchyid.
Manipuler du texte JSON
Le format JSON (JavaScript Object Notation) est un service Web qui utilise du texte lisible pour transmettre des données sous forme de paires attribut-valeur dans le navigateur asynchrone (communication serveur). Par exemple :
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access ne dispose pas de méthodes intégrées de gestion des données JSON, mais dans SQL Server, vous pouvez stocker, indexer, interroger et extraire des données JSON facilement. Vous pouvez convertir et stocker du texte JSON dans une table ou mettre en forme des données en tant que texte JSON. Par exemple, vous pouvez choisir de mettre en forme les résultats de la requête au format JSON pour une application Web ou d’ajouter des structures de données JSON dans des lignes et des colonnes.
Remarque JSON n’est pas pris en charge dans VBA. Vous pouvez également utiliser XML dans VBA à l’aide de la bibliothèque MSXML.
Pour plus d’informations, voir Données JSON dans SQL Server.
Ressources
C’est le moment idéal pour en apprendre davantage sur SQL Server et Transact SQL (TSQL). Comme vous l’avez vu, de nombreuses fonctionnalités sont similaires à Access, mais il y a également tout un potentiel qu’Access n’a pas. Pour passer à l’étape suivante, voici quelques ressources d’apprentissage :
|
Ressource |
Description |
|
Cours vidéo, en anglais |
|
|
Didacticiels sur SQL Server 2017 |
|
|
Exercices pratiques sur Azure |
|
|
Devenez expert |
|
|
Page d’accueil principale |
|
|
Obtenir de l’aide |
|
|
Obtenir de l’aide |
|
|
Le guide essentiel des données dans le cloud (livre électronique) |
Vue d’ensemble du cloud |
|
Récapitulatif visuel des nouvelles fonctionnalités |
|
|
Synthèse des fonctionnalités par version |
|
|
Télécharger SQL Server Express 2017 |
|
|
Télécharger des exemples de base de données |









