
Questo articolo descrive la sintassi della formula e l'uso della funzione REGR.LIN in Microsoft Excel. Per altre informazioni sulla creazione di grafici e l'esecuzione di un'analisi della regressione, usare i collegamenti nella sezione Vedere anche.
Descrizione
La funzione REGR.LIN calcola le statistiche per una linea utilizzando il metodo dei minimi quadrati per calcolare la retta che meglio rappresenta i dati e restituisce una matrice che descrive la retta. È inoltre possibile combinare REGR.LIN con altre funzioni per calcolare le statistiche per altri tipi di modelli con parametri sconosciuti lineari, come le serie polinomiali, logaritmiche, esponenziali e di potenze. Dal momento che questa funzione restituisce una matrice di valori, deve essere immessa come formula in forma di matrice. Le istruzioni sono riportate dopo gli esempi di questo articolo.
L'equazione della retta è:
y = mx + b
–oppure–
y = m1x1 + m2x2 + ... + b
in presenza di più intervalli di valori di x, dove i valori della variabile dipendente y sono una funzione dei valori della variabile indipendente x. I valori m sono coefficienti che corrispondono a ogni valore di x, mentre b è una costante. Si noti che y, x e m possono essere vettori. Il tipo di matrice restituito dalla funzione REGR.LIN è {mn;mn-1;...;m1;b}. REGR.LIN può inoltre restituire statistiche aggiuntive di regressione.
Sintassi
REGR.LIN(y_nota; [x_nota]; [cost]; [stat])
Gli argomenti della sintassi della funzione REGR.LIN sono i seguenti:
Sintassi
-
y_nota Obbligatorio. Insieme dei valori y già noti nella relazione y = mx + b.
-
Se l'intervallo di y_nota è in una singola colonna, ogni colonna di x_nota verrà interpretata come una variabile distinta.
-
Se l'intervallo di y_nota è in una singola riga, ogni riga di x_nota verrà interpretata come una variabile distinta.
-
-
x_nota Facoltativo. Insieme dei valori x che possono essere già noti nella relazione y = mx + b.
-
L'intervallo di x_nota può includere uno o più insiemi di variabili. Se viene utilizzata una sola variabile, y_nota e x_nota potranno essere intervalli di forma qualsiasi, purché con dimensioni uguali. Se vengono utilizzate più variabili, y_nota dovrà essere un vettore, ovvero un intervallo con altezza di una riga o larghezza di una colonna.
-
Se x_nota è omesso, verrà considerato uguale alla matrice {1;2;3;...} che ha le stesse dimensioni di y_nota.
-
-
cost Facoltativo. Valore logico che specifica se la costante b deve essere uguale a 0.
-
Se cost è VERO o è omesso, b verrà calcolata secondo la normale procedura.
-
Se cost è FALSO, b verrà impostata su 0 e i valori m verranno corretti in modo che y = mx.
-
-
stat Facoltativo. Valore logico che specifica se restituire statistiche aggiuntive di regressione.
-
Se stat è VERO, REGR.LIN restituirà le statistiche aggiuntive di regressione; di conseguenza, la matrice restituita è {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2, sey; F;gdl; ssreg,ssresid}.
-
Se stat è FALSO o è omesso, REGR.LIN restituirà solo i coefficienti m e la costante b.
Le statistiche aggiuntive di regressione sono le seguenti:
-
|
Statistica |
Descrizione |
|---|---|
|
s1;s2;...;sn |
I valori di errore standard per i coefficienti m1;m2;...;mn |
|
sb |
Il valore di errore standard per la costante b (sb = #N/D quando cost è FALSO). |
|
r2 |
Il coefficiente di determinazione. Confronta i valori y stimati con quelli effettivi e può avere un valore compreso tra 0 e 1. Se è uguale a 1, significa che esiste una correlazione perfetta nel campione, ovvero non sussiste alcuna differenza tra il valore stimato e il valore effettivo di y. Se invece il coefficiente di determinazione è uguale a 0, l'equazione di regressione non sarà di alcun aiuto nella previsione di un valore y. Per informazioni sulla modalità di calcolo di2 , vedere "Osservazioni" più avanti in questo argomento. |
|
sy |
L'errore standard per la stima di y |
|
F |
Statistica F o valore osservato di F. Utilizzare la statistica F per determinare se la relazione osservata tra le variabili dipendenti e indipendenti si verifica per caso. |
|
gdl |
I gradi di libertà. Utilizzare i gradi di libertà per trovare i valori critici di F in una tabella statistica. Confrontare i valori trovati nella tabella con la statistica F restituita dalla funzione REGR.LIN per stabilire un livello di confidenza per il modello. Per informazioni sulla modalità di calcolo dei gradi di libertà, vedere la sezione "Osservazioni" più avanti in questo argomento. Nell'esempio 4 viene illustrato l'utilizzo di F e dei gradi di libertà. |
|
sqreg |
La somma della regressione dei quadrati. |
|
sqres |
La somma residua dei quadrati. Per informazioni sulla modalità di calcolo di sqreg e sqres, vedere la sezione "Osservazioni" più avanti in questo argomento. |
Nell'illustrazione seguente viene mostrato l'ordine in cui vengono restituite le statistiche aggiuntive di regressione.

Osservazioni
-
È possibile descrivere una qualsiasi retta tramite i valori di pendenza e di intercetta di y:
Pendenza (m):
Per trovare la pendenza di una retta, spesso scritta come m, prendere due punti sulla retta (x1,y1) e (x2,y2); la pendenza è uguale a (y2 - y1)/(x2 - x1).Intercetta di Y (b):
L'intercetta y di una retta, spesso scritta come b, è il valore di y nel punto in cui la retta interseca l'asse y.L'equazione di una retta è y = mx + b. Se sono noti i valori di m e di b, è possibile calcolare qualsiasi punto sulla retta inserendo il valore di y o di x nell'equazione. È inoltre possibile utilizzare la funzione TENDENZA.
-
Quando è disponibile solo una variabile indipendente x, è possibile ricavare direttamente i valori di pendenza e di intercetta di y utilizzando le seguenti formule:
Pendenza:
=INDICE(REGR.LIN(known_y;known_x);1)Intercetta di Y:
=INDICE(REGR.LIN(known_y;known_x);2) -
La precisione della retta calcolata dalla funzione REGR.LIN dipende dal grado di dispersione nei dati. Più i dati sono lineari, più il modello di REGR.LIN risulterà accurato. REGR.LIN utilizza il metodo dei minimi quadrati per determinare la retta che meglio rappresenti i dati. Quando si dispone solo di una variabile indipendente x, i calcoli per m e b vengono basati sulle formule seguenti:
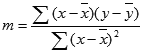
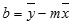
dove x e y sono medie campione, ovvero x = MEDIA(x_nota) e y = MEDIA(y_nota).
-
Le funzioni di adattamento a linee e curve REGR.LIN e REGR.LOG consentono di calcolare la migliore retta o curva esponenziale adatta ai dati. Tuttavia, è necessario decidere quale dei due risultati meglio si adatta ai dati. È possibile calcolare TENDENZA(known_y;known_x) per una retta oppure CRESCITA(known_y, known_x) per una curva esponenziale. Queste funzioni, senza l'argomento della new_x , restituiscono una matrice di valori y previsti lungo la linea o la curva in corrispondenza dei punti dati effettivi. È quindi possibile confrontare i valori previsti con i valori effettivi. È consigliabile creare un grafico per entrambi per un confronto visivo.
-
Nell'analisi della regressione, per ogni punto viene calcolato il quadrato della differenza tra il valore di y stimato per quel punto e il valore effettivo di y corrispondente. La somma dei quadrati delle differenze viene denominata somma residua dei quadrati, sqres. Viene quindi calcolata la somma totale dei quadrati, sqtot. Se cost = VERO o è omesso, la somma totale dei quadrati è la somma del quadrato delle differenze tra i valori effettivi di y e la media dei valori y. Se cost = FALSO, la somma totale dei quadrati è la somma dei quadrati dei valori effettivi di y senza la sottrazione della media dei valori y da ogni valore y. La somma della regressione dei quadrati, sqreg, si ottiene da sqreg = sqtot - sqres. Più piccola è la somma residua dei quadrati, confrontata con la somma totale dei quadrati, maggiore è il valore del coefficiente di determinazione, r2, che è un indicatore di quanto bene l'equazione derivante dall'analisi di regressione spiega la relazione tra le variabili. Il valore di r2 è uguale a sreg/sstotale.
-
In alcuni casi, una o più colonne X (si supponga che Y e X siano in colonne) potrebbero non avere alcun valore predittivo aggiuntivo in presenza delle altre colonne X. In altre parole, l'eliminazione di una o più colonne X potrebbe portare a valori Y previsti altrettanto accurati. In questo caso queste colonne X ridondanti devono essere omesse dal modello di regressione. Questo fenomeno è chiamato "collinearità" perché qualsiasi colonna X ridondante può essere espressa come somma di multipli delle colonne X non ridondanti. La funzione REGR.LIN verifica la collinearità e rimuove tutte le colonne X ridondanti dal modello di regressione quando le identifica. Le colonne X rimosse possono essere riconosciute nell'output REGR.LIN come con coefficienti 0 oltre ai valori 0 se. Se una o più colonne vengono rimosse come ridondanti, la funzione ddl dipende dal numero di colonne X effettivamente utilizzate per scopi predittivi. Per informazioni dettagliate sul calcolo del formato df, vedere l'esempio 4. Se il formato df viene modificato perché vengono rimosse colonne X ridondanti, vengono interessati anche i valori sey e F. La collinearità dovrebbe essere relativamente rara nella pratica. Tuttavia, un caso in cui è più probabile che si verifichi è quando alcune colonne X contengono solo valori 0 e 1 come indicatori del fatto che un soggetto in un esperimento sia o meno membro di un particolare gruppo. Se cost = VERO o viene omesso, la funzione REGR.LIN inserisce di fatto una colonna X aggiuntiva di tutti gli 1 valori per modellare l'intercetta. Se si ha una colonna con 1 per ogni argomento se maschile o 0 in caso contrario, e si ha anche una colonna con 1 per ogni argomento se femminile o 0 se non, quest'ultima colonna è ridondante perché le voci in essa contenute possono essere ottenute sottraendo la voce nella colonna "indicatore maschile" dalla voce nella colonna aggiuntiva di tutti gli 1 valori aggiunti dalla funzione REGR.LIN .
-
Il valore di gdl viene calcolato nel modo seguente, quando nessuna colonna X viene rimossa dal modello a causa della collinearità: se sono presenti k colonne di known_x e cost = VERO o viene omesso, gdl = n – k – 1. Se cost = FALSO, gdl = n - k. In entrambi i casi, ogni colonna X rimossa a causa della collinearità aumenta il valore di df di 1.
-
Quando si immette come argomento una costante di matrice, ad esempio x_nota, utilizzare il punto e virgola (;) per separare i valori nella stessa riga e la barra rovesciata (\) per separare le righe. I caratteri separatori possono variare in base alle impostazioni internazionali.
-
Si noti che i valori y stimati dall'equazione di regressione possono non essere validi qualora siano al di fuori dell'intervallo dei valori y utilizzati per determinare l'equazione.
-
L'algoritmo sottostante utilizzato nella funzione REGR.LIN è diverso da quello utilizzato nelle funzioni PENDENZA e INTERCETTA. La differenza tra questi algoritmi può generare risultati diversi quando i dati sono indeterminati e collineari. Se ad esempio le coordinate dell'argomento y_nota sono 0 e le coordinate dell'argomento x_nota sono 1:
-
REGR.LIN restituisce il valore 0. L'algoritmo di tale funzione è stato progettato per restituire risultati accettabili per i dati collineari e in questo caso è possibile trovare almeno una risposta.
-
PENDENZA e INTERCETTA restituiscono un #DIV/0! . L'algoritmo delle funzioni PENDENZA e INTERCETTA è progettato per cercare una sola risposta e in questo caso possono esserci più risposte.
-
-
Oltre a utilizzare REGR.LOG per calcolare le statistiche per altri tipi di regressione, è possibile utilizzare REGR.LIN per calcolare un intervallo di altri tipi di regressione immettendo funzioni delle variabili x e y come serie x e y di REGR.LIN. La formula seguente ad esempio:
=REGR.LIN(valoriy, valorix^RIF.COLONNA($A:$C))
funziona quando si dispone di una sola colonna di valori y e di una sola colonna di valori x per calcolare l'approssimazione cubica (polinomiale di ordine 3) della forma:
y = m1*x + m2*x^2 + m3*x^3 + b
È possibile modificare questa formula per creare altri tipi di regressione, ma in alcuni casi sarà necessario modificare i valori di output e altre statistiche.
-
Il valore test F restituito dalla funzione REGR.LIN è diverso dal valore test F restituito dalla funzione TEST.F. REGR.LIN restituisce la statistica F, mentre TEST.F restituisce la probabilità.
Esempi
Esempio 1 - Pendenza e Intercetta di Y
Copiare i dati di esempio nella tabella seguente e incollarli nella cella A1 di un nuovo foglio di lavoro di Excel. Per visualizzare i risultati delle formule, selezionarle, premere F2 e quindi premere INVIO. Se necessario, è possibile regolare la larghezza delle colonne per visualizzare tutti i dati.
|
y nota |
x nota |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Risultato (pendenza) |
Risultato (intercetta y) |
|
2 |
1 |
|
Formula (formula di matrice nelle celle A7:B7) |
|
|
=REGR.LIN(A2:A5;B2:B5;;FALSO) |
Esempio 2 - Regressione lineare semplice
Copiare i dati di esempio contenuti nella tabella seguente e incollarli nella cella A1 di un nuovo foglio di lavoro Excel. Per visualizzare i risultati delle formule, selezionarle, premere F2 e quindi premere INVIO. Se necessario, è possibile regolare la larghezza delle colonne per visualizzare tutti i dati.
|
Mese |
Vendite |
|---|---|
|
1 |
$3.100 |
|
2 |
$4.500 |
|
3 |
$4.400 |
|
4 |
$5.400 |
|
5 |
$7.500 |
|
6 |
$8.100 |
|
Formula |
Risultato |
|
=SOMMA(REGR.LIN(B1:B6; A1:A6)*{9;1}) |
€ 11.000 |
|
Calcola il valore stimato delle vendite per il nono mese, in base alle vendite dei mesi da 1 a 6. |
Esempio 3 - Regressione lineare multipla
Copiare i dati di esempio nella tabella seguente e incollarli nella cella A1 di un nuovo foglio di lavoro di Excel. Per visualizzare i risultati delle formule, selezionarle, premere F2 e quindi premere INVIO. Se necessario, è possibile adattare la larghezza delle colonne in modo da vedere i dati per intero.
|
Superficie (x1) |
Uffici (x2) |
Ingressi (x3) |
Età (x4) |
Valore stimato (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
€ 142.000 |
|
2333 |
2 |
2 |
12 |
€ 144,000 |
|
2356 |
3 |
1,5 |
33 |
€ 151.000 |
|
2379 |
3 |
2 |
43 |
€ 150.000 |
|
2402 |
2 |
3 |
53 |
€ 139.000 |
|
2425 |
4 |
2 |
23 |
€ 169.000 |
|
2448 |
2 |
1,5 |
99 |
€ 126.000 |
|
2471 |
2 |
2 |
34 |
€ 142.900 |
|
2494 |
3 |
3 |
23 |
€ 163.000 |
|
2517 |
4 |
4 |
55 |
€ 169.000 |
|
2540 |
2 |
3 |
22 |
€ 149.000 |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formula (formula di matrice dinamica immessa in A19) |
||||
|
=REGR.LIN(E2:E12;A2:D12;VERO;VERO) |
Esempio 4 - Utilizzo delle statistiche F e r2
Nell'esempio precedente, il coefficiente di determinazione, o r2, è 0,99675 (vedere la cella A17 nell'output per REGR.LIN), che indicherebbe una forte relazione tra le variabili indipendenti e il prezzo di vendita. È possibile utilizzare la statistica F per determinare se questi risultati, con un valore r2 così alto, si sono verificati per caso.
Si supponga infatti che non esista alcuna relazione tra le variabili, ma che sia stato scelto un raro campione di 11 palazzine con il quale l'analisi statistica dimostra una forte relazione. Il termine "Alfa" viene utilizzato nella probabilità che si giunga erroneamente alla conclusione che esista una relazione.
Nell'output della funzione REGR.LIN i valori F e gdl possono essere utilizzati per valutare la probabilità di un valore F più alto casuale. F può essere confrontato con i valori critici delle tabelle di distribuzione F pubblicate oppure è possibile utilizzare la funzione DISTRIB.F di Excel per calcolare la probabilità di tale valore. La distribuzione F appropriata è associata ai gradi di libertà v1 e v2. Se n è il numero delle coordinate e cost = VERO o è omesso, allora v1 = n – gdl – 1 e v2 = gdl. Se cost = FALSO, allora v1 = n – gdl e v2 = gdl. La funzione DISTRIB.F con la sintassi DISTRIB.F(F;v1;v2) restituirà la probabilità di un valore F più alto casuale. In questo esempio gdl = 6 (cella B18) e F = 459,753674 (cella A18).
Dato un valore alfa pari a 0,05, v1 = 11 – 6 – 1 = 4 e v2 = 6, il livello critico di F è 4,53. Dal momento che F = 459,753674 è di gran lunga superiore a 4,53, è estremamente improbabile che tale valore F sia casuale. Se alfa = 0,05, l'ipotesi che non esista alcuna relazione tra y_nota e x_nota deve essere scartata quando F supera il livello critico, ovvero 4,53. Utilizzando la funzione DISTRIB.F di Excel, è possibile ottenere la probabilità relativa alla casualità di un valore F così alto. Ad esempio, DISTRIB.F(459,753674; 4; 6) = 1,37E-7, probabilità minima. È possibile concludere che, sia cercando il livello critico di F in una tabella sia utilizzando la funzione DISTRIB.F, l'equazione di regressione consente di prevedere il valore stimato delle palazzine a uso ufficio in questa zona. È importante utilizzare i valori corretti di v1 e v2 calcolati nel paragrafo precedente.
Esempio 5 - Calcolo della statistica T
Un altro test ipotetico determinerà se ogni coefficiente di pendenza è utile nel calcolo del valore stimato di una palazzina a uso ufficio nell'esempio 3. Per verificare ad esempio il coefficiente di età a fini statistici, dividere il valore -234,24 (il coefficiente di pendenza dell'età) per il valore 13,268 (l'errore standard stimato dei coefficienti di età nella cella A15). Il valore osservato di t è il seguente:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Se il valore assoluto di t è sufficientemente alto, è possibile concludere che il coefficiente di pendenza consente di calcolare il valore stimato di una palazzina a uso ufficio nell'esempio 3. Nella tabella seguente vengono illustrati i valori assoluti dei quattro valori osservati di t.
Se si consulta una tabella di un manuale di statistica, si noterà che il valore critico di t, a due code, con 6 gradi di libertà e Alfa = 0,05 è pari a 2,447. Questo valore critico può essere trovato anche utilizzando la funzione INV.T di Excel. INV.T(0,05;6) = 2,447. Dal momento che 17,7, il valore assoluto di t, è maggiore di 2,447, l'età è una variabile importante nel calcolo del valore stimato di una palazzina a uso ufficio. Ognuna delle altre variabili indipendenti può essere verificata a fini statistici in maniera analoga. Di seguito sono riportati i valori osservati di t per ognuna delle variabili indipendenti.
|
Variabile |
Valore osservato di t |
|---|---|
|
Superficie |
5,1 |
|
Numero di uffici |
31,3 |
|
Numero di ingressi |
4,8 |
|
Età |
17,7 |
Tutti questi valori hanno un valore assoluto maggiore di 2,447. Ne consegue che tutte le variabili utilizzate nell'equazione di regressione sono utili nella stima del valore accertato delle palazzine a uso ufficio della zona.









