
Access から SQL Server へのデータの移行が完了するとクライアント/サーバー データベースが構築され、これはオンプレミス ソリューションとハイブリッド Azure クラウド ソリューションのいずれでも可能です。 いずれの方法でも、Access はプレゼンテーション層になり、SQL Server はデータ層になります。 データベース ソリューションを改善して拡張することが可能になるよう、お客様のソリューションについて、特にクエリのパフォーマンス、セキュリティ、事業の継続性などの側面について、今の時点で再検討することをお勧めします。
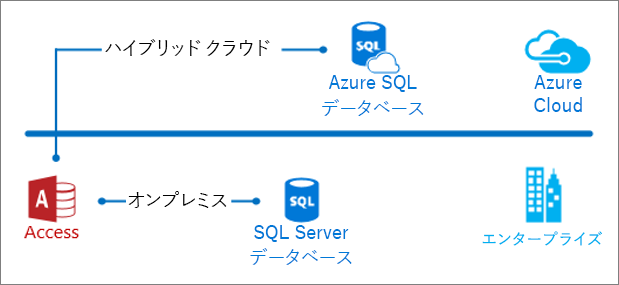
Access のユーザーが SQL Server および Azure のドキュメントを初めて目にした際は、わかりにくいと感じるかもしれません。 このため、重要部分のハイライトを紹介するガイドを用意しました。 このガイドを読み終えると、進化したデータベース テクノロジのさまざまな機能の詳細情報を理解するための準備が完了します。
この記事の内容
|
データベースの管理 |
クエリ関連 |
データ型 |
その他 |
事業継続性の実現
Access ソリューションにおいては、サービス中断を最小限に抑えて稼働状態を維持することに務める必要がありますが、Access のバックエンド データベースでのオプションは限られています。 Access データベースのバックアップはデータ保護に不可欠な作業ですが、実行するにはユーザーをオフラインにする必要があります。 また、ハードウェア/ソフトウェア保守のためのアップグレード、ネットワーク停止や停電、ハードウェアの故障、セキュリティ侵害、さらにはサイバー攻撃など、予期しないダウンタイムも発生します。 SQL Server データベースでは、ダウンタイムと業務への影響を最小限に抑えるため、稼働状態を維持したままバックアップを実行することができます。 さらに、SQL Server では高可用性 (HA) および障害復旧 (DR) 戦略も提供されます。 これら 2 つのテクノロジが組み合わさったものを、HADR と呼びます。 詳細については、「事業継続性とデータベースの復旧」および「SQL Server を使用した事業継続性の実現 (電子ブック)」 を参照してください。
稼働中のバックアップ
SQL Server では、データベースの稼働中に実行可能なオンライン バックアップ処理を使用します。 完全なバックアップ、部分的バックアップ、またはファイル バックアップを実行できます。 完全な復元操作が行えるよう、バックアップ処理ではデータおよびトランザクション ログがコピーされます。 オンプレミスのソリューションの場合、単純復旧と完全復旧のオプションの違いとそれぞれのトランザクション ログの増大への影響について特に注意してください。 詳細については、「回復モデル」を参照してください。
ファイル管理やデータベースの圧縮処理を除き、ほとんどのバックアップ操作は即座に実行されます。 これに対して、バックアップ操作中にデータベース ファイルを作成または削除しようとすると、操作は失敗します。 詳細については、「Backup Overview (バックアップの概要)」を参照してください。
HADR
高可用性と事業継続性を実現するための最も一般的な手法には、ミラーリングとクラスタリングの 2 つの手法があります。 SQL Server では、ミラーリングとクラスタリングは "Always On フェールオーバー クラスター インスタンス" と "AlwaysOn 可用性グループ" と統合されています。
ミラーリングは、スタンバイ データベース (異なるハードウェア上の、アクティブなデータベースの完全コピーまたはミラー) を維持することによる、ほぼ瞬時のフェールオーバーをサポートするデータベース レベルの継続性ソリューションです。 ミラーリングは、同期 (高安全性) モード (受信するトランザクションがすべてのサーバーに同時にコミットされる) または非同期モード (受信するトランザクションがアクティブなデータベースにコミットされ、その後、事前に設定された任意の時点でミラーにコピーされる) で実行できます。 ミラーリングはデータベース レベルのソリューションで、完全復旧モデルを使用しているデータベースでのみ動作します。
クラスタリングはサーバー レベルのソリューションで、複数のサーバーを、ユーザーからは 1 つのインスタンスに見える単一のデータ ストレージに結合します。 ユーザーが接続するのはインスタンスであるため、インスタンス内のどのサーバーが現在アクティブであるかをユーザーが知る必要はありません。 ある特定のサーバーに障害が発生した場合、または保守のためにオフラインにする必要がある場合でも、ユーザー エクスペリエンスへの影響はありません。 クラスター マネージャーはハートビートを使用してクラスター内の各サーバーを監視しており、クラスター内のアクティブなサーバーがオフライン状態になった場合はそれを検出し、クラスター内の次のサーバーへのシームレスな切り替えを試みます。ただし、切り替えには長さの異なる遅延が生じます。
詳細については、「常にオンのフェールオーバー クラスター インスタンス」および「常にオンの可用性グループ: 高可用性とディザスター リカバリーのソリューション」を参照してください。
SQL Server セキュリティ
Access データベースはセキュリティ センターを使用したりデータベースを暗号化したりする方法で保護できますが、SQL Server にはより高度なセキュリティ機能が備わっています。 Access ユーザーにとって特に重要な 3 つの機能を紹介します。 詳細については、「SQL Server の保護」を参照してください。
データベースの認証
SQL Server には 4 つのデータベース認証方法があり、各方法は ODBC 接続文字列により指定できます。 詳細については、「Azure SQL Server データベースにリンク、または Azure SQL Server データベースからデータをインポートする」を参照してください。 各方法にはそれぞれ利点があります。
統合 Windows 認証 ユーザーの検証、セキュリティ ロール、機能やデータでのユーザーの制限になどに、Windows の資格情報を使用します。 ドメインの資格情報を活用して、アプリケーションでのユーザー権限を簡単に管理できます。 必要に応じて、サービス プリンシパル名 (SPN) を入力します。 詳細については、「認証モードの選択」を参照してください。
SQL Server 認証 データベースで設定した資格情報で接続する必要があります。セッション中にデータベースにユーザーが最初にアクセスするときは、ログイン ID とパスワードを入力します。 詳細については、「認証モードの選択」を参照してください。
Active Directory 統合認証 Azure Active Directory を使用して Azure SQL Server データベースに接続します。 Azure Active Directory を構成すると、追加のログインおよびパスワードは必要ありません。 詳細については、「Azure Active Directory 認証を使用して SQL Database または SQL Data Warehouse を認証する」を参照してください。
Active Directory パスワード認証 Azure Active Directory で設定した資格情報で接続します。ログイン名とパスワードを入力します。 詳細については、「Azure Active Directory 認証を使用して SQL Database または SQL Data Warehouse を認証する」を参照してください。
ヒント 脅威の検出を使用して、Azure SQL Server データベースに対する潜在的なセキュリティの脅威を示す異常なデータベース アクティビティに関する通知を受信します。 詳細については、「SQL データベースの脅威検出」を参照してください。
アプリケーションのセキュリティ
SQL Server には、Access で利用できるアプリケーション レベルのセキュリティ機能が 2 つあります。
動的なデータ マスキング アクセス権限を持たないユーザーからマスクすることにより機密情報を隠します。 たとえば、社会保障番号の一部または全部をマスクできます。
 部分的なデータ マスク |
 完全なデータ マスク |
データ マスクを定義するにはいくつかの方法があり、それらを異なるデータ型に適用できます。 データ マスキングは、定義された一連のユーザーについてテーブルと列レベルでポリシーに準拠し、リアルタイムでクエリに適用されます。 詳細については、「動的なデータ マスキング」を参照してください。
行レベルのセキュリティ 行レベルのセキュリティを使用して、ユーザーの特性に基づいて、データベースの特定の行へのアクセスを制御できます。 このアクセス制限はデータベースシステムによって適用されるため、セキュリティ システムの信頼性と堅牢性が向上します。

2 種類のセキュリティ述語があります。
-
フィルター述語は、クエリから行をフィルター処理します。 フィルターは透明で、エンド ユーザーはフィルター処理に気づきません。
-
ブロック述語は不正なアクションを防止し、操作が実行できない場合は例外をスローします。
詳細については、「行レベルのセキュリティ」を参照してください。
暗号化を使用してデータを保護する
保存中、送信中、および使用中のデータを、データベースのパフォーマンスに影響を与えずに保護します。 詳細については、「SQL Server の暗号化」を参照してください。
保存中の暗号化 物理的なストレージ層でのオフライン メディア攻撃から個人データを保護するには、透過的なデータ暗号化 (TDE) とも呼ばれる、保存時の暗号化を使用します。 これにより、物理的なメディアが盗難にあった場合や不適切に廃棄された場合でも、データが保護されます。 TDE は、データベース、バックアップ、トランザクション ログの暗号化と解読をリアルタイムで実行します。アプリケーションを変更する必要はありません。
送信中の暗号化 スヌーピングや "中間者攻撃" を防ぐために、ネットワーク内で送信されるデータを暗号化できます。 SQL Server では、安全性の高いコミュニケーションのためにトランスポート層セキュリティ (TLS) 1.2 をサポートしています。 信頼できないネットワーク上でのコミュニケーションの保護には、表形式データ ストリーム (TDS) プロトコルも使用されます。
クライアントで使用中の暗号化 使用中の個人データを保護するために、"常に暗号化" 機能を使用することをお勧めします。 個人データは、暗号化キーをデータベース エンジンに公開することなくクライアント コンピューター上のドライバーによって暗号化および解除が行われます。 これにより、暗号化されたデータはそのデータを管理する担当者にしか表示されず、高い権限を持つもののアクセスの対象外の他のユーザーには表示されません。 "常に暗号化" を使用した場合、選択した暗号化の種類によっては、暗号化された列の検索、グループ化、インデックス作成などの一部のデータベース機能が制限されることがあります。
プライバシーに関する懸念への対処
プライバシーの問題は大きな問題であるため、欧州連合では一般データ保護規則 (GDPR) を通して法的要件を定義しています。 幸いなことに、SQL Server のバックエンドにはこの要求に対応する能力が備わっています。 GDPR 対策の実装には、3 つの手順からなるフレームワークを使用します。

手順 1:コンプライアンス リスクを評価して管理する
GDPR では、テーブルおよびファイルに保存されている個人データを特定し、一覧を作成することが要求されています。 この情報には、名前、写真、メールアドレス、銀行口座情報、ソーシャルネットワーク Web サイトへの投稿、医療情報、さらには IP アドレスなど、さまざまな情報が該当します。
SQL Server Management Studio に組み込まれている新しいツールである SQL データの検出と分類は、次の 2 つのメタデータ属性を列に適用することで、機密性の高いデータの検出、分類、ラベル付け、およびレポートに役立ちます。
-
ラベル データの秘密度を定義します。
-
情報の種類 列に格納されるデータの種類をさらに細分化します。
使用できるもう 1 つの検出の仕組みとして、フルテキスト検索があります。これには、CONTAINS 述語や FREETEXT 述語や、SELECT ステートメントで使用するための、CONTAINSTABLE や FREETEXTTABLE のような行セット値関数の使用が含まれます。 フルテキスト検索を使用すると、テーブルを検索して単語、単語の組み合わせ、または単語のバリエーション (同義語や語尾変化した形など) を検出できます。 詳しくは、「フルテキスト検索」を参照してください。
手順 2:個人データを保護する
GDPR では、個人データの保護とアクセスの制限が要求されています。 ファイアウォールの設定などの、ネットワークやリソースへのアクセスを管理するために実行する標準的な手順に加え、SQL Server のセキュリティ機能を使用してデータへのアクセスを制御できます。
-
SQL Server の認証による、ユーザー ID の管理および不正アクセスの防止。
-
行レベルセキュリティによる、ユーザーとデータの関係に基づいたテーブル内の行へのアクセスの制限。
-
動的なデータ マスキングを使用した、権限のないユーザーに対して個人データをマスクすることによる個人データの漏洩の防止。
-
暗号化による、サーバー側での侵害からの保護を含む、送信中や保存中における個人データの保護の確保。
詳細については、「SQL Server の保護」を参照してください。
手順 3:要求に効率的に対応する
GDPR では、個人データ処理の記録を維持し、監督機関から要請された場合にはそれらの記録を開示することが要求されています。 偶発的なデータの公開を含む問題が発生した場合、保護制御により迅速に対応することができます。 レポートが必要な場合は、データを素早く利用可能にする必要があります。 たとえば、GDPR では、個人データの侵害があった場合、「侵害に気がついてから 72 時間以内に」監督機関に報告することが要求されています。
SQL Server 2017 では、いくつかの方法で報告タスクを支援します。
-
SQL Server 監査 は、データベースへのアクセスおよび処理に関するアクティビティの永続的な記録の維持を確保します。 データベースのアクティビティを追跡するきめ細かな監査が実行され、潜在的な脅威、疑わしい不正使用、またはセキュリティ違反の把握と特定を支援します。 データ フォレンジックを速やかに実行できます。
-
SQL Server のテンポラル テーブルは、データ変更の履歴を完全に維持するように作られた、システム バージョン管理されたユーザー テーブルです。 テンポラル テーブルを使用すると、報告と特定の時点の分析を簡単に行えるようになります。
-
SQL 脆弱性評価 は、セキュリティおよびアクセス許可の問題を検出するのに役立ちます。 問題が検出された場合は、データベース スキャンレポートを精査することによっても、解決のためのアクションを見つけることができます。
詳細については、「Create a platform of trust (信頼のプラットフォームを構築する) (電子ブック)」 および 「Journey to GDPR Compliance (GDPR 準拠に向けた取り組み)」を参照してください。
データベース スナップショットを作成する
データベース スナップショットは、ある時点での SQL Server データベースの読み取り専用の静的ビューです。 Access データベース ファイルをコピーすることで実質的にはデータベース スナップショットを作成できますが、Access には SQL Server のような組み込みの方法がありません。 データベース スナップショットを使用して、データベース スナップショットの作成時点のデータに基づいてレポートを作成できます。 また、データベース スナップショットを使用して、各財務四半期の期末報告書の準備に使用できる履歴データなどを管理することもできます。 Microsoft がお勧めするベスト プラクティスは次の通りです。
-
スナップショットに名前を付ける データベースの各スナップショットには、一意のデータベース名が必要です。 識別しやすいように、名前に目的と期間を含めます。 たとえば、AdventureWorks データベースのスナップショットを午前 6 時から午後 6 時の間に 6 時間間隔で 1 日に 3 回作成するには、スナップショットに AdventureWorks_snapshot_0600、AdventureWorks_snapshot_1200、AdventureWorks_snapshot_1800 という 24 時間制に基づく名前を付けます。
-
スナップショットの数を制限する それぞれのデータベース スナップショットは、明示的に削除されるまで保持されます。 各スナップショットの容量は大きくなり続けるため、新しいスナップショットを作成した後に古いスナップショットを削除することで、ディスク領域を節約できます。 たとえば、日次レポートを作成している場合は、データベース スナップショットを 24 時間保持した後に削除し、新しいスナップショットに置き換えます。
-
正しいスナップショットに接続する データベース スナップショットを使用するには、Access フロントエンドが正しい保管場所を把握している必要があります。 既存のスナップショットを新しいスナップショットで置き換える場合は、Access を新しいスナップショットにリダイレクトする必要があります。 Access フロントエンドにロジックを追加して、正しいデータベース スナップショットに接続できるようにします。
データベース スナップショットを作成する方法は通りです。
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
詳細については、「データベース スナップショット (SQL Server)」を参照してください。
同時実行制御
多数のユーザーがデータベースのデータを同時に変更しようとする場合は、あるユーザーが行った変更が別のユーザーが行った変更に悪影響を与えないようにするための制御システムが必要です。 これは、同時実行制御と呼ばれ、悲観ロックと楽観ロックという 2 つの基本的なロック方法があります。 ロックは、他のユーザーに影響を与えるようなデータの変更をユーザーが行うことを防止できます。 ロックは、データベースの整合性 (特に、ロックされていない場合に予期しない結果を生成する可能性があるクエリ) の確保にも役立ちます。 Access と SQL Server がこれらの同時実行制御の方法を実装する方法には、重要な違いがあります。
Access での既定のロック方法は楽観ロックで、最初にレコードへの書き込みを試みるユーザーにロックの所有権が付与されます。 Access では、同じレコードへの書き込みを同時に試みる他のユーザーに対して、[書き込みの競合] ダイアログ ボックスが表示されます。 競合を解決するには、他のユーザーはレコードを保存するか、クリップボードにコピーするか、または変更を削除するかできます。
また、RecordLocks プロパティを使用して、同時実行制御の方法を変更することもできます。 このプロパティには 3 つの設定があり、フォーム、レポート、およびクエリに影響を与えます。
-
ロックなし フォームでは、同じレコードの編集を複数のユーザーが同時に試みることができますが、[書き込みの競合] ダイアログ ボックスが表示される場合があります。 レポートでは、レポートがプレビューまたは印刷されている間、レコードはロックされません。 クエリの場合、クエリの実行中、レコードはロックされません。 Access はこのようにして楽観ロックを実装します。
-
すべてのレコード フォームがフォーム ビューまたはデータシート ビューで開かれている間、レポートがプレビューまたは印刷されている間、またはクエリの実行中、それらの基となるテーブルまたはクエリのすべてのレコードがロックされます。 ロック中でもユーザーはレコードを読み取ることができます。
-
編集済みのレコード フォームとクエリの場合、ユーザーがレコード内のフィールドの編集を始めるとレコードのページがロックされ、ユーザーが別のレコードに移るまでロック状態が維持されます。 結果的に、レコードを編集できるのは一度に 1 ユーザーに限られます。 Access はこのようにして悲観ロックを実装します。
詳細については、「[書き込みの競合] ダイアログボックス」および「RecordLocks プロパティ」を参照してください。
SQL Server では、同時実行制御は次のように動作します。
-
悲観 ロックを引き起こすアクションをユーザーが実行すると、所有者がロックを解放するまでは、他のユーザーはこのロックと競合するアクションを実行できません。 このような同時実行制御は、データの競合が多く発生する環境で主に使用されます。
-
楽観 楽観的同時実行制御では、ユーザーがデータを読み取るときにロックを行いません。 ユーザーがデータを更新すると、読み取り後に別のユーザーがデータを変更したかどうかが確認されます。 別のユーザーがデータを更新していた場合は、エラーが発生します。 通常、エラーを受信したユーザーはトランザクションをロールバックして、やり直します。 このような同時実行制御は、データの競合があまり発生しない環境で主に使用されます。
トランザクション分離レベル (トランザクションを他のトランザクションにより行われた変更から保護するレベルを SET TRANSACTION ステートメントを使用して定義します) を指定すると同時実行制御の種類を選ぶことができます。
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
分離レベル |
説明 |
|
非コミット読み取り |
トランザクションは、物理的に破損したデータが読み取られないようにする範囲でのみ分離されます。 |
|
コミット読み取り |
トランザクションは、別のトランザクションで既に読み取られたデータを読み取ることができ、これを行うのに最初のトランザクションの完了を待つ必要はありません。 |
|
反復可能読み取り |
選択したデータに対しては、トランザクションが終了するまでは読み取りと書き込みロックが発生しますが、ファントム読み取りが発生することがあります。 |
|
スナップショット |
行バージョンを使用して、トランザクション レベルの読み取りの一貫性を提供します。 |
|
シリアル化可能 |
トランザクションは、相互に完全に分離されます。 |
詳細については、「トランザクションのロックおよび行のバージョン管理ガイド」を参照してください。
クエリのパフォーマンスを向上させる
Access のパススルー クエリが正常に動作している場合は、SQL Server でより効率的にクエリを実行させるための高度な方法を利用できます。
Access データベースとは異なり、SQL Server では並列クエリが提供され、複数のマイクロプロセッサ (CPU) を搭載しているコンピューターでのクエリの実行およびインデックス操作が最適化されます。 SQL Server では、複数のシステム ワーカー スレッドを使用してクエリまたはインデックス操作を並行して実行できるため、操作を迅速かつ効率的に完了することができます。
クエリは、データベース ソリューションの全体的なパフォーマンスを向上させるための重要な構成要素です。 不良なクエリは無限に実行され、タイムアウトが発生し、CPU、メモリ、ネットワーク バンディットなどのリソースを消費します。 これは、重要なビジネス情報の可用性の障害となります。 不良なクエリが 1 つあっただけでも、データベースで深刻なパフォーマンスの問題を引き起こす可能性があります。
詳細については、「SQL Server を使用したクエリの高速化 (電子ブック)」を参照してください。
クエリの最適化
組み合わせて使用することによりクエリのパフォーマンスを分析して改善するのに役立つツールがいくつかあります。クエリ オプティマイザ、実行プラン、およびクエリ ストアです。
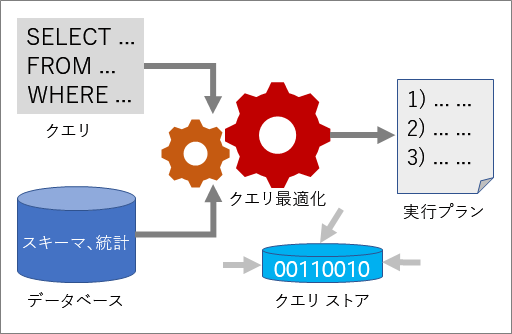
クエリ オプティマイザ
クエリ オプティマイザは、SQL Server の最も重要な構成要素の 1 つです。 クエリ オプティマイザを使用して、クエリを分析し、必要なデータにアクセスする最も効率的な方法を決定します。 クエリ オプティマイザへの入力は、クエリ、データベース スキーマ (テーブルとインデックス定義)、およびデータベース統計情報から構成されます。 クエリ オプティマイザの出力は実行プランです。
詳細については、「SQL Server のクエリ オプティマイザ」を参照してください。
実行プラン
実行プランは、ソース テーブルへのアクセスと各テーブルからデータを抽出するために使用する方法の順序を決める定義です。 最適化は、考えられるプランの中から実行プランを 1 つ選択するプロセスです。 考えられる各実行プランには、コンピューティング リソースの使用量の面でコストが付随し、クエリ オプティマイザはコストの見積もりが最も低いプランを選択します。
また、SQL Server は、データベースの状態の変化に動的に合わせる必要があります。 クエリ実行プランの回帰はパフォーマンスに大きく影響します。 データベースの変更内容によっては、データベースの新しい状態に基づいて実行プランの効率性が低下したり無効になったりする場合があります。 実行プランを無効にする変更が SQL Server で検出されると、そのプランは無効であるとマークされます。
クエリを実行する次の接続のために新しいプランを再コンパイルする必要があります。 プランを無効にする条件には、次が含まれます。
-
クエリによって参照されているテーブルまたはビューで行われる変更 (ALTER TABLE および ALTER VIEW)。
-
実行プランで使用されるインデックスの変更。
-
実行プラン画が使用している統計情報に対する更新。これは、UPDATE STATISTICS などのステートメントから明示的に生成される更新、または自動的に生成される更新です。
詳細については、「実行プラン」を参照してください。
クエリ ストア
クエリ ストアは、実行プランの選択およびパフォーマンスに関する分析を提供します。 実行プランの変更によるパフォーマンスの変化を素早く見つけることができるため、パフォーマンスのトラブルシューティングが簡素化されます。 クエリ ストアは、クエリの履歴、プラン、実行時の統計情報、待機の統計情報などのテレメトリ データを収集します。 クエリ ストアを実装するには、ALTER DATABASE ステートメントを使用します。
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
詳細については、「クエリのストアを使用した、パフォーマンスの監視」を参照してください。
自動プラン修正
おそらく、クエリのパフォーマンスを向上させる最も簡単な方法は、Azure SQL Database で提供される機能である、自動プラン修正です。 有効にするだけで、機能は自動で動作します。 この機能は実行プランの監視と分析を継続的に実行し、問題のある実行プランを検出し、パフォーマンスの問題を自動的に修正します。 バックグラウンドでは、自動プラン修正は学習、適応、検証、反復という 4 つの手順を使用しています。
詳細については、「自動チューニング」を参照してください。
適応型クエリ処理
適応型クエリ処理という新機能を備えた SQL Server 2017 にアップグレードするだけでもクエリの高速化を図れます。 SQL Server では、実行時の特性に基づいて、クエリ プランの選択肢が調整されます。
基数見積もりは、実行プランの各ステップで処理される行数を概算します。 不正確な見積もりは、クエリ応答時間の遅延、リソースの不要な使用 (メモリ、CPU、IO)、スループットや同時実行性の低下などを招く可能性があります。 アプリケーションのワークロード特性に適合させるために、3 つの方法が使用されます。
-
バッチ モード メモリ許可フィードバック 基数見積もりが不適切な場合、クエリにより "ディスクへの書き込み" または大量のメモリ消費が引き起こされる可能性があります。 SQL Server 2017 では、実行フィードバックに基づいてメモリ許可を調整し、ディスクへの書き込みを排除し、反復クエリの同時実行性を向上させます。
-
バッチ モード適応型結合 適応型結合は、より適切な内部結合の種類 (入れ子ループ結合、マージ結合、またはハッシュ結合) を実際の入力行に基づき実行中に動的に選択します。 したがって、プランはより適した結合方法に実行中に動的に切り替えることができます。
-
インターリーブ実行 従来、クエリ処理では、複数ステートメント テーブル値関数は、ブラックボックスとして扱われてきました。 SQL Server 2017 ではより正確に行数を見積もることができるため、ダウンストリーム操作が向上します。
データベースで互換性レベル 140 を有効にすると、自動的にワークロードを適応型クエリの対象にできます。
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
詳細については、「SQL データベースでのインテリジェントなクエリ処理」を参照してください。
クエリの実行方法
SQL Server では複数の方法でクエリを実行することができ、それぞれの方法には固有のメリットがあります。 Access ソリューションについて適正な選択ができるよう、これらについて把握しておくことが大切です。 TSQL クエリを作成する最適な方法は、正しいキーワードの選択と構文エラーの確認に役立つ Intellisense を持つ SQL Server Management Studio (SSMS) Transact-SQL エディターを使用して TSQL クエリを対話的に編集してテストするという方法です。
ビュー
SQL Server でのビューは、ビューのデータが 1 つまたは複数のテーブルや他のビューから取得される、仮想テーブルと似ています。 ただし、クエリでは、ビューはテーブルと全く同じように参照されます。 ビューはクエリの複雑性を隠し、行と列のセットを制限することでデータを保護できます。 単純なビューの例を次に示します。
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
最適なパフォーマンスを実現し、ビューの結果を編集するには、インデックス付きビューを作成します。このビューはテーブルのようにデータベースで維持され、割り当てられた記憶域を持ち、テーブルと同様に簡単にクエリを実行できます。 Access でこれを使用するには、テーブルにリンクする場合と同じ方法でビューにリンクします。 インデックス付きビューの例を次に示します。
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
ただし、制限があります。 複数のベーステーブルが影響を受ける場合や、ビューに集計関数または DISTINCT 句が含まれる場合は、データを更新することはできません。 削除するレコードが不明であるというエラー メッセージが表示される場合は、ビューに DELETE トリガーを追加する必要がある可能性があります。 最後に、Access クエリとは異なり、ORDER BY 句を使用することはできません。
詳細については、「ビュー」および「インデックス付きビューの作成」を参照してください。
ストアド プロシージャ
ストアド プロシージャは、入力パラメーターを受け取り、出力パラメーターを返す 1 つまたは複数の TSQL ステートメントのグループで、状態値を使用して成功または失敗を示します。 Access のフロントエンドと SQL Server のバックエンド間の中間層として機能します。 ストアド プロシージャは、SELECT ステートメントのように単純な場合も、プログラムのように複雑な場合もあります。 次に例を示します。
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Access でストアド プロシージャを使用すると、通常は結果セットをフォームまたはレポートに返します。 ただし、DDL ステートメントや DML ステートメントなど、結果を返さない他の操作を実行する場合があります。 パススルー クエリを使用する場合は、ReturnsRecords プロパティが適切に設定されていることを確認します。
詳細については、「ストアド プロシージャ」を参照してください。
共通テーブル式
共通テーブル式 (CTE) は、名前付き結果セットを生成する一時的なテーブルに似ています。 単一のクエリまたは DML ステートメントを実行するためのみに存在します。 CTE は、SELECT ステートメントや、それを使用する DML ステートメントと同じコード行に作成されますが、一時テーブルまたはビューの作成と使用は通常、2 段階のプロセスです。 次に例を示します。
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
CTE には、次を含むいくつかの利点があります。
-
CTE は一時的なものなので、ビューのような永続的なデータベースオブジェクトとして作成する必要はありません。
-
クエリ ステートメントまたは DML ステートメントで同じ CTE を複数回参照することができるため、コードの管理が簡単になります。
-
CTE を参照するクエリを使用して、カーソルを定義できます。
詳細については、「共通テーブル式」を参照してください。
ユーザー定義関数
ユーザー定義関数 (UDF) は、クエリや計算を実行してスカラー値またはデータ結果セットを返すことができます。 パラメーターを受け取り、複雑な計算などの操作を実行し、その操作の結果を値として返す、プログラミング言語の関数と似ています。 次に例を示します。
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
UDF にはいくつかの制限があります。 たとえば、特定の非決定的なシステム関数の使用、DML や DDL ステートメントの実行、または動的な SQL クエリの実行はできません。
詳細については、「ユーザー定義関数」を参照してください。
キーとインデックスを追加する
使用しているデータベース システムに関わらず、キーとインデックスは連携して動作します。
キー
SQL Server では、各テーブルに主キーを作成し、関連する各テーブルにと外部キーを作成するようにします。 SQL Server には、IDENTITY プロパティという、Access AutoNumber データ型に相当する機能があり、キー値の作成に使用できます。 このプロパティを数値の列に適用すると、その列は読み取り専用になり、データベース システムにより管理されるようになります。 IDENTITY 列を含むテーブルにレコードを挿入すると、IDENTITY 列の値がシステムにより (1 から開始して) 自動的に 1 ずつ増やされますが、これらの値は引数を使って制御できます。
詳細については、「CREATE TABLE、IDENTITY (プロパティ)」を参照してください。
インデックス
従来と同じく、インデックスの選択ではクエリの速度と更新のコストのバランスをうまく取ることが求められます。 Access でのインデックスの種類は 1 つですが、SQL Server の場合は 12 種類あります。 幸いなことに、クエリ オプティマイザを使用して最も効果的なインデックスを確実に選択することができます。 Azure SQL では、自動チューニング機能の 1 つである、インデックスの追加や削除の提案を行う自動インデックス管理を使用できます。 Access とは異なり、SQL Server では外部キーに独自のインデックスを作成する必要があります。 インデックス付きのビューにインデックスを作成して、クエリのパフォーマンスを向上させることもできます。 インデックス付きビューの短所として、ビューのベース テーブル内のデータを変更する際のオーバーヘッドの増加が挙げられ、これは、ビューも更新する必要があることが原因です。 詳細については、「SQL Server のインデックスのアーキテクチャとデザイン ガイド」および「インデックス」を参照してください。
トランザクションを実行する
Access を使用している場合は、オンライン トランザクション プロセス (OLTP) を使用するのは簡単ではありませんが、SQL Server では比較的簡単に使用できます。 トランザクションは、成功した場合にすべてのデータ変更をコミットし、失敗した場合は変更をロールバックする 1 つの作業単位です。 トランザクションには、通常 ACID と呼ばれる次の 4 つのプロパティが必要です。
-
原子性 トランザクションは、作業単位が原子的 (不可分) である必要があります。つまり、すべてのデータ変更が実行されるか、何も実行されないかのいずれかである必要があります。
-
一貫性 トランザクションの完了時、トランザクションによりすべてのデータが一貫性のある状態に維持されている必要があります。 つまり、すべてのデータ整合性ルールが適用されます。
-
分離性 並行トランザクションによる変更は、現在のトランザクションから分離されます。
-
耐久性 トランザクションが完了すると、システム障害が発生した場合でも、変更は永続的なものになります。
ATM での現金引き出しや給与の自動振り込みなど、データの整合性保証を確保する際にトランザクションを使用します。 明示的、暗黙的、またはバッチスコープのトランザクションを実行できます。 TSQL の例を 2 つ紹介します。
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
詳細については、「トランザクション」を参照してください。
制約とトリガーの使用
すべてのデータベースには、データの整合性を維持する方法が備わっています。
制約
Access では、外部キーと主キーの組み合わせ、連鎖更新と連鎖削除、および検証ルールを使用してテーブルのリレーションシップに参照整合性を適用します。 詳細については、「テーブルのリレーションシップの概要」および「入力規則を使ってデータ入力を制限する」を参照してください。
SQL Server では、UNIQUE および CHECK 制約を使用します。これらは、SQL Server テーブルでのデータ整合性を適用するデータベース オブジェクトです。 ある値が別のテーブルで有効であることを検証するには、外部キー制約を使用します。 列内の値が特定の範囲内にあることを検証するには、CHECK 制約を使用します。 これらのオブジェクトは最初の防衛戦で、効率的に動作するように設計されています。 詳細については、「UNIQUE 制約と CHECK 制約」を参照してください。
トリガー
Access には、データベース トリガーはありません。 SQL Server では、複雑なデータ整合性ルールを適用し、サーバー上でこのビジネス ロジックを実行するのにトリガーを使用できます。 データベース トリガーは、データベース内で特定のアクションが発生したときに実行されるストアド プロシージャです。 トリガーはテーブルへのレコードの追加や削除などのイベントで、ストアド プロシージャをトリガーして実行します。 ユーザーがデータを更新または削除しようとした際の参照整合性は Access データベースでも確保できますが、SQL Server には高度なトリガーが備わっています。 たとえば、レコードを一括削除してデータの整合性を確保するためのトリガーをプログラムできます。 トリガーをテーブルやビューに追加することもできます。
詳細については、「DML トリガー」、「DDL トリガー」、および「T-SQL トリガーの設計」を参照してください。
計算列を使用する
Access では、集計列をクエリに追加して、次のような式を構築して作成します。
Extended Price: [Quantity] * [Unit Price]
SQL Server では、それに相当する機能は計算列と呼ばれています。これは、列が PERSISTED とマークされている場合を除いてはテーブルに物理的には保存されていない仮想列です。 集計列と同様に、計算列は他の列のデータを式内で使用します。 計算列を作成するには、それをテーブルに追加します。 次に例を示します。
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); 詳細については、「テーブルの計算列の指定」を参照してください。
データのタイム スタンプ
データ入力を記録できるようにするために、レコードが作成されたときにタイムス タンプを記録するテーブル フィールドを追加することがあります。 Access では、既定値の =Now() を使用して、日付列を簡単に作成できます。 SQL Server で日付や時刻を記録するには datetime2 データ型を使用し、規定値として SYSDATETIME() を使用します。
注 ROWVERSION とデータへの TIMESTAMP の追加とを混同しないようにします。 キーワードの TIMESTAMP は、SQL Server の ROWVERSION のシノニムですが、キーワードの ROWVERSION を使用する必要があります。 SQL Server では、ROWVERSION は自動的に生成された固有のバイナリ番号をデータベース内で公開するデータ型で、一般的には、テーブル行にバージョンをスタンプするための仕組みとして使用されます。 ただし、ROWVERSION データ型は増分値であり、日付や時刻を保持せず、行にタイムスタンプを追加する目的には設計されていません。
詳細については、「rowversion」参照してください。 レコードの競合を最小限に抑えるための ROWVERSION の使用の詳細については、「Access データベースを SQL Server に移行する」を参照してください。
大規模なオブジェクトを管理する
Access では、Attachment データ型を使用して、ファイル、写真、画像などの非構造化データを管理します。 SQL Server の用語では、非構造化データは Blob (バイナリ ラージ オブジェクト) と呼ばれ、操作する方法がいくつかあります。
FILESTREAM Varbinary (max) データ型を使用して、非構造化データをデータベースではなくファイル システムに格納します。 詳細については、「Transact-SQL による FILESTREAM データへのアクセス」を参照してください。
FileTable Blob を FileTables という特殊なテーブルに格納します。クライアント アプリケーションに変更を加えることなく、ファイル システムに格納されているかのような Windows アプリケーションとの互換性を提供します。 FileTable は、FILESTREAM を使用する必要があります。 詳細については、「FileTables」を参照してください。
リモート BLOB ストア (RBS) サーバーではなく、コモディティ ストレージ ソリューションにバイナリ ラージ オブジェクト (BLOB) を格納します。 保存領域の節約とハードウェア リソースの軽減につながります。 詳細については、「バイナリ ラージ オブジェクト (Blob) データ」を参照してください。
階層データでの作業
Access などのリレーショナル データベースは高い柔軟性を持ちますが、これは階層関係の作業には当てはまらず、多くの場合複雑な SQL ステートメントやコードが必要になります。 階層データの例としては、組織構造、ファイル システム、言語用語の分類、Web ページ間のリンク図などがあります。 SQL Server には、階層データの格納、クエリ、および管理を簡単に実行できるようにする、組み込みの hierarchyid データ型および階層関数のセットが備わっています。
詳細については、「階層データ」および「チュートリアル: hierarchyid データ型の使用」を参照してください。
JSON テキストを操作する
JavaScript オブジェクト表記 (JSON) は、ブラウザーとサーバー間の非同期通信でデータを属性値のペアとして送信するのに、人間が判読できるテキストを使用する Web サービスです。 次に例を示します。
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
JSON データを管理するための方法は Access には組み込まれていませんが、SQL Server では、JSON データの格納、インデックス作成、クエリ、抽出をスムーズに実行できます。 テーブル内の JSON テキストは変換したり保存したりでき、データを JSON テキストとして書式設定することもできます。 たとえば、Web アプリでのクエリ結果を JSON として書式設定したり、JSON データ構造を行や列に追加したりすることができます。
注 JSON は VBA でサポートされていません。 代替方法として、MSXML ライブラリを使用して VBA で XML を使用することができます。
詳細については、「SQL Server の JSON データ」を参照してください。
参照資料
SQL Server と Transact SQL (TSQL) についてより深く理解するための良い機会です。 これまでの説明にある通り、Access に似た機能が多数提供されていますが、Access では全く提供されていない機能もあります。 より深く理解していただけるよう、学習リソースを以下に紹介します。
|
リソース |
説明 |
|
ビデオ コース |
|
|
SQL Server 2017 に関するチュートリアル |
|
|
Azure に関する体験学習 |
|
|
エキスパートになる |
|
|
メインのランディングページ |
|
|
ヘルプ情報 |
|
|
ヘルプ情報 |
|
|
クラウドの概要 |
|
|
新機能の視覚的な概要 |
|
|
バージョンごとの機能の概要 |
|
|
SQL Server Express 2017 のダウンロード |
|
|
サンプル データベースのダウンロード |









