
이 문서는 Wayne L. Winston의 Microsoft Excel 데이터 분석 및 비즈니스 모델링 에서 수정되었습니다.
-
누가 몬테카를로 시뮬레이션을 사용합니까?
-
셀에 =RAND() 를 입력하면 어떻게 되나요?
-
불연속 임의 변수의 값을 시뮬레이션하려면 어떻게 할까요?
-
일반 임의 변수의 값을 시뮬레이션하려면 어떻게 할까요?
-
인사말 카드 회사에서 생성할 카드 수를 어떻게 결정할 수 있나요?
불확실한 이벤트의 확률을 정확하게 예측하려고 합니다. 예를 들어 새 제품의 현금 흐름이 NPV(양의 순 현재 가치)를 가질 확률은 무엇인가요? 투자 포트폴리오의 위험 요소는 무엇인가요? 몬테카를로 시뮬레이션을 통해 불확실성을 제시하는 상황을 모델링한 다음 컴퓨터에서 수천 번 재생할 수 있습니다.
참고: 몬테카를로 시뮬레이션이라는 이름은 원자 폭탄이 폭발하는 데 필요한 연쇄 반응이 성공적으로 작동할 확률을 추정하기 위해 1930년대와 1940년대에 수행된 컴퓨터 시뮬레이션에서 비롯되었습니다. 이 작품에 참여한 물리학자들은 도박의 열렬한 팬이었기 때문에 시뮬레이션에 몬테 카를로라는 코드 이름을 지정했습니다.
다음 5장에서는 Excel을 사용하여 몬테카를로 시뮬레이션을 수행하는 방법에 대한 예제를 볼 수 있습니다.
많은 회사에서 몬테카를로 시뮬레이션을 의사 결정 프로세스의 중요한 부분으로 사용합니다. 다음은 몇 가지 예입니다.
-
제너럴 모터스, 프록터 앤 갬블, 화이자, Bristol-Myers 스퀴브, 엘리 릴리는 시뮬레이션을 사용하여 신제품의 평균 수익률과 위험 요소를 모두 추정합니다. GM에서 이 정보는 CEO가 시장에 출시되는 제품을 결정하는 데 사용됩니다.
-
GM은 기업의 순이익 예측, 구조 및 구매 비용 예측, 다양한 종류의 위험(예: 금리 변동 및 환율 변동)에 대한 취약성 결정과 같은 활동에 시뮬레이션을 사용합니다.
-
Lilly는 시뮬레이션을 사용하여 각 약물에 대한 최적의 식물 용량을 결정합니다.
-
프록터와 갬블은 시뮬레이션을 사용하여 외환 위험을 모델링하고 최적으로 헤지합니다.
-
Sears는 시뮬레이션을 사용하여 공급업체에서 주문해야 하는 각 제품 라인의 단위 수를 결정합니다(예: 올해 주문해야 하는 Dockers 바지 쌍 수).
-
석유 및 제약 회사는 시뮬레이션을 사용하여 프로젝트를 확장, 계약 또는 연기할 수 있는 옵션의 가치와 같은 "실제 옵션"을 소중히 여립니다.
-
재무 플래너는 몬테카를로 시뮬레이션을 사용하여 고객의 은퇴에 대한 최적의 투자 전략을 결정합니다.
셀에 =RAND() 수식을 입력하면 0에서 1 사이의 값을 가정할 가능성이 같은 숫자가 표시됩니다. 따라서 시간의 약 25%는 0.25보다 작거나 같은 숫자를 가져와야 합니다. 시간의 약 10%는 0.90 이상인 숫자를 가져와야 합니다. RAND 함수의 작동 방식을 보여 주려면 그림 60-1에 표시된 파일 Randdemo.xlsx 살펴보십시오.
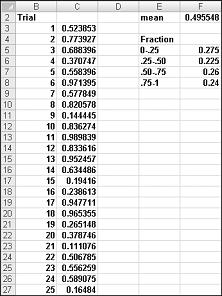
참고: Randdemo.xlsx 파일을 열면 그림 60-1에 표시된 것과 동일한 난수가 표시되지 않습니다. RAND 함수는 워크시트를 열거나 워크시트에 새 정보를 입력할 때 생성하는 숫자를 항상 자동으로 다시 계산합니다.
먼저 셀 C3에서 C4:C402로 수식 =RAND()를 복사합니다. 그런 다음 범위 이름을 C3:C402 데이터로 지정 합니다. 그런 다음 F열에서 400개의 난수(셀 F2)의 평균을 추적하고 COUNTIF 함수를 사용하여 0과 0.25, 0.25 및 0.50, 0.50 및 0.75, 0.75 및 0.75 사이의 분수를 확인할 수 있습니다. F9 키를 누르면 난수가 다시 계산됩니다. 400개 숫자의 평균은 항상 약 0.5이며 결과의 약 25%는 0.25 간격입니다. 이러한 결과는 난수의 정의와 일치합니다. 또한 다른 셀에서 RAND에 의해 생성된 값은 독립적입니다. 예를 들어 C3 셀에서 생성된 난수가 큰 숫자(예: 0.99)인 경우 생성된 다른 난수의 값에 대해서는 아무 것도 알려주지 않습니다.
일정에 대한 수요는 다음과 같은 불연속 임의 변수에 의해 제어됩니다.
|
수요 |
probability |
|
10,000 |
0.10 |
|
20,000,000 |
0.35 |
|
40,000 |
0.3 |
|
60,000 |
0.25 |
일정에 대한 이러한 요구를 여러 번 Excel에서 재생하거나 시뮬레이션하려면 어떻게 해야 할까요? 트릭은 RAND 함수의 가능한 각 값을 일정에 대한 가능한 수요와 연결하는 것입니다. 다음 할당은 10,000의 수요가 시간의 10% 정도 발생하도록 합니다.
|
수요 |
난수 할당됨 |
|
10,000 |
0.10 미만 |
|
20,000,000 |
0.10보다 크거나 같고 0.45보다 작음 |
|
40,000 |
0.45보다 크거나 같고 0.75보다 작음 |
|
60,000 |
0.75보다 크거나 같음 |
수요 시뮬레이션을 보여 주려면 다음 페이지의 그림 60-2에 표시된 파일 Discretesim.xlsx 확인합니다.
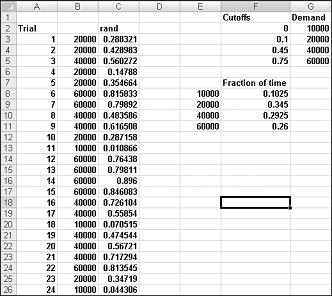
시뮬레이션의 핵심은 난수를 사용하여 테이블 범위 F2:G5(명명된 조회)에서 조회를 시작하는 것입니다. 0보다 크거나 같고 0.10보다 작은 난수는 10,000의 수요를 생성합니다. 0.10보다 크거나 같고 0.45보다 작은 난수는 20,000의 수요를 생성합니다. 0.45보다 크거나 같고 0.75보다 작은 난수는 40,000의 수요를 생성합니다. 0.75보다 크거나 같은 난수는 60,000의 수요를 생성합니다. 수식 RAND()를 C3에서 C4:C402로 복사하여 400개의 난수를 생성합니다. 그런 다음 수식 VLOOKUP(C3,lookup,2)을 B3에서 B4:B402로 복사하여 일정 수요의 400개 평가판 또는 반복을 생성합니다. 이 수식을 사용하면 0.10 미만의 난수가 10,000의 수요를 생성하고 0.10에서 0.45 사이의 난수는 20,000의 수요를 생성합니다. 셀 범위 F8:F11에서 COUNTIF 함수를 사용하여 각 수요를 산출하는 400회 반복의 비율을 확인합니다. F9 키를 눌러 난수를 다시 계산하면 시뮬레이션된 확률이 가정된 수요 확률에 가깝습니다.
NORMINV(rand(),mu,sigma) 수식을 셀에 입력하면 평균 mu 및 표준 편차 시그마를 갖는 일반 임의 변수의 시뮬레이션된 값을 생성합니다. 이 절차는 그림 60-3에 표시된 파일 Normalsim.xlsx 설명되어 있습니다.
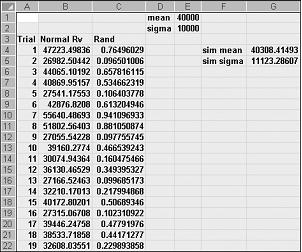
평균이 40,000이고 표준 편차가 10,000인 일반 임의 변수에 대해 400개의 평가판 또는 반복을 시뮬레이션한다고 가정해 보겠습니다. (E1 및 E2 셀에 이러한 값을 입력하고 이러한 셀의 이름을 각각 평균 및 시그마로 지정할 수 있습니다.) 수식 =RAND()를 C4에서 C5:C403으로 복사하면 400개의 다른 난수가 생성됩니다. B4에서 B5:B403으로 복사하는 수식 NORMINV(C4,mean,sigma) 는 평균이 40,000이고 표준 편차가 10,000인 일반 임의 변수에서 400개의 다른 평가판 값을 생성합니다. F9 키를 눌러 난수를 다시 계산하면 평균은 40,000에 가깝고 표준 편차는 10,000에 가깝습니다.
기본적으로 난수 x의 경우 NORMINV(p,mu,sigma) 수식은 평균 mu 및 표준 편차 시그마를 사용하여 일반 임의 변수의 pth 백분위수를 생성합니다. 예를 들어 C4 셀의 난수 0.77(그림 60-3 참조)은 평균이 40,000이고 표준 편차가 10,000인 일반 임의 변수의 약 77번째 백분위수 B4 셀에서 생성됩니다.
이 섹션에서는 몬테카를로 시뮬레이션을 의사 결정 도구로 사용하는 방법을 알아보세요. 발렌타인 데이 카드 대한 수요는 다음과 같은 불연속 임의 변수에 의해 제어됩니다.
|
수요 |
probability |
|
10,000 |
0.10 |
|
20,000,000 |
0.35 |
|
40,000 |
0.3 |
|
60,000 |
0.25 |
인사말 카드 판매 $4.00, 각 카드 생산의 가변 비용은 $1.50. 남은 카드는 카드당 $0.20의 비용으로 삭제해야 합니다. 인쇄해야 하는 카드는 몇 개입니까?
기본적으로 가능한 각 생산 수량(예: 10,000, 20,000, 40,000 또는 60,000)을 여러 번 시뮬레이션합니다(예: 1000회). 그런 다음, 1,000 반복에 대한 최대 평균 이익을 산출하는 주문 수량을 결정합니다. 그림 60-4에 표시된 파일 Valentine.xlsx 이 섹션의 데이터를 찾을 수 있습니다. 셀 B1:B11의 범위 이름을 C1:C11 셀에 할당합니다. 셀 범위 G3:H6에는 이름 조회가 할당됩니다. 판매 가격 및 비용 매개 변수는 C4:C6 셀에 입력됩니다.
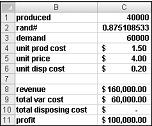
C1 셀에 평가판 생산 수량(이 예제에서는 40,000개)을 입력할 수 있습니다. 다음으로 셀 C2에 =RAND() 수식을 사용하여 난수를 만듭니다. 앞에서 설명한 대로 수식 VLOOKUP(rand,lookup,2)을 사용하여 C3 셀의 카드 대한 수요를 시뮬레이션합니다. (VLOOKUP 수식에서 rand는 RAND 함수가 아닌 C3 셀에 할당된 셀 이름입니다.)
판매 단위의 수는 우리의 생산 수량과 수요의 작은입니다. C8 셀에서는 MIN(produced,demand)*unit_price 수식을 사용하여 수익을 계산합니다. C9 셀에서 생성된 수식 *unit_prod_cost 사용하여 총 생산 비용을 계산합니다.
주문형보다 더 많은 카드를 생산하면 남은 단위 수가 프로덕션에서 수요를 뺀 값과 같습니다. 그렇지 않으면 남은 단위가 없습니다. C10 셀의 처리 비용은 수식 unit_disp_cost*IF(>수요, 생산된 수요,0)로 계산합니다. 마지막으로 C11 셀에서 수익을 수익(total_var_cost-total_disposing_cost)으로 계산합니다.
각 생산 수량에 대해 F9를 여러 번 누르고(예: 1000) 각 수량에 대한 예상 수익을 집계하는 효율적인 방법을 찾고 싶습니다. 이 상황은 양방향 데이터 테이블이 구조되는 상황입니다. (데이터 테이블에 대한 자세한 내용은 챕터 15, "데이터 테이블을 사용하여 민감도 분석"을 참조하세요.) 이 예제에 사용된 데이터 테이블은 그림 60-5에 나와 있습니다.
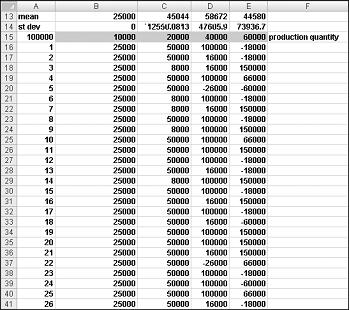
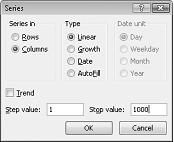
셀 범위 A16:A1015에서 숫자 1-1000(1000개 평가판에 해당)을 입력합니다. 이러한 값을 만드는 한 가지 쉬운 방법은 A16 셀에 1을 입력하는 것입니다. 셀을 선택한 다음 편집 그룹의 홈 탭에서 채우기를 클릭하고 계열을 선택하여 계열 대화 상자를 표시합니다. 그림 60-6에 표시된 계열 대화 상자에 1단계 값과 중지 값 1000을 입력합니다. 계열 영역의 열 옵션을 선택한 다음 확인을 클릭합니다. 숫자 1-1000은 셀 A16부터 A 열에 입력됩니다.
다음으로 B15:E15 셀에 가능한 생산 수량(10,000, 20,000, 40,000, 60,000)을 입력합니다. 각 평가판 수(1~1000) 및 각 생산 수량에 대한 수익을 계산하려고 합니다. =C11을 입력하여 데이터 테이블(A15)의 왼쪽 위 셀에 있는 수익 수식( C11 셀에서 계산)을 참조합니다.
이제 각 프로덕션 수량에 대해 1,000회 반복된 수요를 시뮬레이션하도록 Excel을 속일 준비가 되었습니다. 테이블 범위(A15:E1014)를 선택한 다음 데이터 탭의 데이터 도구 그룹에서 What If Analysis를 클릭한 다음 데이터 테이블을 선택합니다. 양방향 데이터 테이블을 설정하려면 프로덕션 수량(셀 C1)을 행 입력 셀로 선택하고 빈 셀(셀 I14 선택)을 열 입력 셀로 선택합니다. 확인을 클릭한 후 Excel은 각 주문 수량에 대해 1000개의 요청 값을 시뮬레이트합니다.
이것이 작동하는 이유를 이해하려면 셀 범위 C16:C1015의 데이터 테이블에 배치된 값을 고려합니다. 이러한 각 셀에 대해 Excel은 C1 셀에 20,000의 값을 사용합니다. C16에서 열 입력 셀 값 1은 빈 셀에 배치되고 셀 C2의 난수는 다시 계산됩니다. 그러면 해당 수익이 C16 셀에 기록됩니다. 그런 다음 열 셀 입력 값 2가 빈 셀에 배치되고 C2의 난수가 다시 계산됩니다. 해당 수익은 C17 셀에 입력됩니다.
셀 B13에서 C13:E13 수식 AVERAGE(B16:B1015)로 복사하여 각 프로덕션 수량에 대한 평균 시뮬레이션 수익을 계산합니다. 셀 B14에서 C14:E14 수식 STDEV(B16:B1015)로 복사하여 각 주문 수량에 대해 시뮬레이션된 수익의 표준 편차를 계산합니다. F9 키를 누를 때마다 각 주문 수량에 대해 1,000번의 요청 반복이 시뮬레이션됩니다. 40,000장의 카드를 생산하면 항상 가장 큰 예상 수익을 올릴 수 있습니다. 따라서 40,000장의 카드를 생산하는 것이 적절한 결정인 것으로 보입니다.
위험의 영향이 결정에 미치는 영향 카드 40,000장 대신 20,000장의 카드를 생산하면 예상 수익은 약 22% 감소하지만 위험(표준 이익 편차로 측정)은 거의 73% 감소합니다. 따라서 위험을 극도로 싫어한다면 20,000장의 카드를 생산하는 것이 올바른 결정일 수 있습니다. 덧붙여, 10,000장의 카드를 생산하는 경우 10,000장의 카드를 생산하면 항상 남은 카드 없이 모든 카드를 판매하기 때문에 항상 0장의 카드의 표준 편차가 있습니다.
참고: 이 통합 문서에서 계산 옵션은 테이블을 제외한 자동으로 설정됩니다. (수식 탭의 계산 그룹에서 계산 명령을 사용합니다.) 이 설정은 F9 키를 누르지 않는 한 데이터 테이블이 다시 계산되지 않도록 합니다. 이는 워크시트에 항목을 입력할 때마다 큰 데이터 테이블이 작업을 다시 계산하는 경우 작업 속도가 느려지기 때문입니다. 이 예제에서는 F9 키를 누를 때마다 평균 수익이 변경됩니다. F9 키를 누를 때마다 각 주문 수량에 대한 요구를 생성하는 데 1,000개의 난수 시퀀스가 사용되므로 발생합니다.
평균 수익에 대한 신뢰 간격 이 상황에서 물어 자연 질문은, 어떤 간격으로 우리는 95 % 진정한 평균 이익이 떨어질 것이라고 확신? 이 간격을 평균 이익의 95% 신뢰 구간이라고 합니다. 시뮬레이션 출력 평균에 대한 95% 신뢰 구간은 다음 수식으로 계산됩니다.
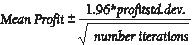
셀 J11에서는 수식 D13-1.96*D14/SQRT(1000)를 사용하여 40,000개의 달력이 생성될 때 평균 수익에 대한 95% 신뢰 구간에 대한 하한을 계산합니다. 셀 J12에서는 수식 D13+1.96*D14/SQRT(1000)를 사용하여 95% 신뢰 구간의 상한을 계산합니다. 이러한 계산은 그림 60-7에 나와 있습니다.
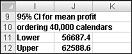
40,000개의 달력이 주문될 때 평균 수익이 $56,687에서 $62,589 사이임을 95% 확신합니다.
-
GMC 딜러는 2005 년 특사에 대한 수요가 일반적으로 평균 200 및 표준 편차 30으로 분산 될 것이라고 믿습니다. 특사를 받는 비용은 $25,000이며, 그는 특사를 $40,000에 판매합니다. 전체 가격으로 판매되지 않는 모든 특사의 절반은 $ 30,000에 판매 될 수 있습니다. 그는 200, 220, 240, 260, 280 또는 300 특사를 주문하는 것을 고려하고 있습니다. 그는 몇 을 주문해야합니까?
-
작은 슈퍼마켓은 매주 주문해야 사람 잡지의 얼마나 많은 사본을 결정하려고합니다. 사람 대한 요구는 다음과 같은 불연속 임의 변수에 의해 제어됩니다.
수요
probability
15
0.10
20
0.20
25
0.30
30
0.25
35
0.15
-
슈퍼마켓은 사람 각 사본에 대해 $ 1.00을 지불하고 $ 1.95에 판매합니다. 각 미분양 복사본은 $0.50에 반환될 수 있습니다. 스토어에서 주문해야 하는 사람 복사본은 몇 개입니까?
추가 지원
언제든지 Excel 기술 커뮤니티에서 전문가에게 문의하거나 커뮤니티에서 지원을 받을 수 있습니다.









