
이 문서에서는 Microsoft Excel의 LINEST 함수에 사용되는 수식 구문과 이 함수를 사용하는 방법을 설명합니다. 차트 작성 및 회귀 분석에 대한 자세한 내용을 보려면 참고 항목 섹션에서 해당 링크를 클릭하세요.
설명
LINEST 함수는 데이터에 가장 적합한 직선을 구하는 "최소 자승법"을 사용하여 선의 통계를 계산하고 선에 대한 배열을 구합니다. LINEST를 다른 함수와 결합하여 다항식, 로그, 지수, 멱급수 등 알 수 없는 매개 변수에서 다른 유형의 선형 모델에 대한 통계를 구할 수도 있습니다. 이 함수는 값을 배열로 반환하므로 배열 수식으로 입력해야 합니다. 지침은 이 문서의 예제를 참조하세요.
선의 방정식은 다음과 같습니다.
y = mx + b
또는
y = m1x1 + m2x2 + ... + b
x-값의 범위가 여러 개일 때 종속 y 값은 독립 x 값의 함수입니다. m값은 각 x값에 대응하는 계수이고 b는 상수 값입니다. x, y, m은 벡터가 될 수 있습니다. LINEST 함수가 반환하는 배열은 {mn,mn-1,...,m1,b}입니다. LINEST는 추가 회귀 통계를 반환할 수도 있습니다.
구문
LINEST(known_y's, [known_x's], [const], [stats])
LINEST 함수 구문에는 다음과 같은 인수가 사용됩니다.
구문
-
known_y's 필수 요소입니다. y = mx + b 식에서 이미 알고 있는 y 값의 집합입니다.
-
known_y's 범위가 한 개의 열에 있으면 known_x's의 각 열은 별도의 변수로 해석됩니다.
-
known_y's 범위가 한 개의 행에 있으면 known_x's의 각 행은 별도의 변수로 해석됩니다.
-
-
known_x's 선택 요소입니다. y = mx + b 식에서 이미 알고 있는 x 값의 집합입니다.
-
known_x's 범위에는 하나 이상의 변수 집합이 포함될 수 있습니다. 변수가 하나만 사용될 경우 known_y's 및 known_x's의 차원이 같으면 모든 형태의 범위를 사용할 수 있습니다. 둘 이상의 변수를 사용할 때 known_y's는 벡터(한 행의 높이 또는 한 열의 너비를 가진 범위)여야 합니다.
-
known_x's 를 생략하면 known_y's와 같은 크기의 배열 {1,2,3,...}으로 간주됩니다.
-
-
const 선택 요소입니다. 상수 b를 0으로 할지 여부를 지정하는 논리값입니다.
-
const 가 TRUE이거나 이를 생략하면 b는 정상적으로 계산됩니다.
-
const 가 FALSE이면 b는 0으로 설정되고 m 값은 y = mx에 맞게 조정됩니다.
-
-
stats 선택 요소입니다. 추가적인 회귀 통계 항목을 구할지 여부를 지정하는 논리값입니다.
-
stats 가 TRUE이면 LINEST는 추가 회귀 통계를 반환합니다. 결과적으로 반환된 배열은 {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey ;F,df;ssreg,ssresid}입니다
-
stats 가 FALSE이거나 생략되면 LINEST 함수는 m 계수와 상수 b만 반환합니다.
추가적인 회귀 통계량은 다음과 같습니다.
-
|
통계 |
설명 |
|---|---|
|
se1,se2,...,sen |
계수 m1,m2,...,mn에 대한 표준 오차값입니다. |
|
seb |
상수 b에 대한 표준 오차값(const가 FALSE이면 seb = #N/A)입니다. |
|
r2 |
결정 계수입니다. y 값의 추정값과 실제값을 비교하며 값의 범위는 0부터 1까지입니다. 계수가 1이면 표본에 완전한 상관 관계가 성립하고 y 값의 추정값과 실제값 사이에는 아무런 차이가 없습니다. 결정 계수가 0이면 해당 회귀 방정식은 y 값을 예측하는 데 아무 도움이 되지 않습니다. r2 계산 방법에 대한 자세한 내용은 이 항목의 뒷부분에 나오는 "비고"를 참조하세요. |
|
sey |
y 추정값에 대한 표준 오차입니다. |
|
F |
F 통계량 또는 F-관측값입니다. F 통계량을 사용하여 종속 변수와 독립 변수 사이에서 관측된 관계가 우연히 발생된 것인지 여부를 확인할 수 있습니다. |
|
df |
자유도. 자유도를 사용하면 통계표에서 F-임계 값을 찾는 데 도움이 됩니다. 표에서 찾은 값을 LINEST에서 반환한 F 통계와 비교하여 모델의 신뢰 수준을 결정합니다. df 계산 방법에 대한 자세한 내용은 이 항목 뒷부분의 "설명"을 참조하세요. 예 4는 F와 df의 사용을 보여줍니다. |
|
ssreg |
회귀 제곱의 합입니다. |
|
ssresid |
잔차 제곱의 합입니다. ssreg와 ssresid를 계산하는 방법에 대한 자세한 내용은 뒷부분의 "주의"를 참조하세요. |
다음 그림은 추가 회귀 통계를 구하는 순서를 보여 줍니다.

주의
-
모든 직선을 기울기와 y 절편으로 설명할 수 있습니다.
기울기(m):
직선의 기울기 m은 직선 위의 두 점 (x1,y1)과 (x2,y2)에서 (y2 - y1)/(x2 - x1)로 구합니다.y 절편(b):
직선의 y 절편 b는 직선이 y축과 교차하는 점의 y 값입니다.직선의 방정식은 y = mx + b입니다. m과 b의 값을 알고 있다면 x 값 또는 y 값을 방정식에 대입하여 직선의 모든 점을 계산할 수 있습니다. 또한 TREND 함수를 사용할 수도 있습니다.
-
독립 변수 x가 하나뿐인 경우 다음 수식을 사용하여 기울기와 y 절편을 직접 구할 수 있습니다.
기울기:
=INDEX(LINEST(known_y's,known_x's),1)y 절편:
=INDEX(LINEST(known_y's,known_x's),2) -
LINEST 함수에 의해 계산된 회귀 직선의 정확도는 데이터의 분산 정도에 따라 결정됩니다. 데이터가 선형일수록 LINEST 모델은 더 정확해 집니다. LINEST는 데이터에 가장 적합한 회귀 직선을 결정하기 위하여 최소 자승법을 사용합니다. 독립 변수 x의 값을 하나만 갖고 있다면 m과 b의 계산식은 다음과 같습니다.
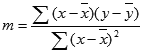
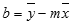
여기에서 x와 y는 표본 평균, 즉 x = AVERAGE(known x's), y = AVERAGE(known_y's)입니다.
-
선 및 곡선 맞춤 함수 LINEST 및 LOGEST는 데이터에 가장 적합한 직선 또는 지수 곡선을 계산할 수 있습니다. 그러나 두 결과 중 어느 것이 데이터에 가장 적합한지 결정해야 합니다. 직선의 경우 TREND(known_y's,known_x's)를 계산하거나 GROWTH(known_y's, 지수 곡선의 경우 known_x)입니다. 이러한 함수는 new_x 인수 없이 실제 데이터 포인트에서 해당 선 또는 곡선을 따라 예측된 y 값 배열을 반환합니다. 그런 다음 예측 값을 실제 값과 비교할 수 있습니다. 시각적 비교를 위해 둘 다 차트로 작성할 수 있습니다.
-
회귀 분석에서 Excel은 각 점에 대해 해당 점에 대해 추정된 y 값과 실제 y 값 사이의 제곱 차이를 계산합니다. 이러한 차이 제곱의 합을 잔차 제곱합 ssresid라고 합니다. 그러면 Excel에서 총 제곱합인 sstotal을 계산합니다. const 인수 = TRUE 또는 생략된 경우 총 제곱합은 실제 y 값과 y 값의 평균 간의 차이 제곱의 합입니다. const 인수 = FALSE인 경우 총 제곱합은 실제 y값의 제곱합입니다(각 개별 y값에서 평균 y값을 빼지 않음). 그런 다음 회귀 제곱합 ssreg는 ssreg = sstotal - ssresid에서 찾을 수 있습니다. 총 제곱합에 비해 잔차 제곱합이 작을수록 회귀분석 결과 방정식이 얼마나 잘 맞는지 나타내는 지표인 결정계수 r2의 값이 크다. 변수 간의 관계를 설명합니다. r2의 값은 ssreg/sstotal과 같습니다.
-
경우에 따라 하나 이상의 X 열(Y와 X가 열에 있다고 가정)은 다른 X 열이 있는 경우 추가 예측 값이 없을 수 있습니다. 즉, 하나 이상의 X 열을 제거하면 똑같이 정확한 Y 값을 예측할 수 있습니다. 이 경우 이러한 중복 X 열은 회귀 모델에서 생략되어야 합니다. 중복된 X 열은 중복되지 않은 X 열의 배수의 합으로 표현될 수 있기 때문에 이러한 현상을 "공선성"이라고 합니다. LINEST 함수는 공선성을 확인하고 중복 X 열을 식별하면 회귀 모델에서 제거합니다. 제거된 X 열은 LINEST 출력에서 0 se 값 외에 0 계수를 갖는 것으로 인식될 수 있습니다. 하나 이상의 열이 중복으로 제거되면 df는 예측 목적으로 실제로 사용되는 X 열 수에 따라 달라지므로 df에 영향을 미칩니다. df 계산에 대한 자세한 내용은 예 4를 참조하세요. 중복 X 열이 제거되어 df가 변경되면 sey 및 F 값도 영향을 받습니다. 공선성은 실제로는 상대적으로 드물어야 합니다. 그러나 발생할 가능성이 더 높은 한 가지 경우는 일부 X 열에 실험 대상이 특정 그룹의 구성원인지 여부를 나타내는 지표로 0과 1 값만 포함되어 있는 경우입니다. const = TRUE이거나 생략된 경우 LINEST 함수는 절편을 모델링하기 위해 모든 1개 값의 추가 X 열을 효과적으로 삽입합니다. 남성인 경우 각 주제에 대해 1, 그렇지 않은 경우 0인 열이 있고 여성인 경우 각 주제에 대해 1 또는 그렇지 않은 경우 0인 열이 있는 경우 후자의 열은 항목이 중복될 수 있으므로 중복됩니다. LINEST 함수에 의해 추가된 모든 1개 값의 추가 열 항목에서 '남성 지표' 열 항목을 빼서 얻습니다.
-
공선성으로 인해 모델에서 제거되는 X 열이 하나도 없을 때 df의 값은 다음과 같이 계산됩니다. const = FALSE이면 df = n - k입니다. 두 경우 모두 공선성으로 인해 제거된 X 열 하나에 대해 df가 1씩 증가합니다.
-
known_x's 와 같은 배열 상수를 인수로 입력할 때는 쉼표를 사용하여 같은 행에 있는 값을 구분하고 세미콜론을 사용하여 행을 구분합니다. 구분 기호는 국가별 설정에 따라 다를 수 있습니다.
-
회귀 방정식으로 예측한 y 값이 방정식 결정에 사용한 범위 밖에 있을 때는 그 값이 유효하지 않을 수도 있습니다.
-
LINEST 함수에 사용되는 기본 알고리즘은 SLOPE 및 INTERCEPT 함수에 사용되는 기본 알고리즘과 다릅니다. 이러한 알고리즘의 차이로 인해 데이터가 확정적이지 않고 동일한 선 위에 있는 경우 서로 다른 결과가 반환될 수 있습니다. 예를 들어 known_y's 인수의 데이터 요소가 0이고 known_x's 인수의 데이터 요소가 1인 경우
-
LINEST가 값 0을 반환합니다. LINEST 함수의 알고리즘은 공선 데이터에 대해 적당한 결과를 반환하도록 디자인되었으므로 이 경우 답을 하나 이상 찾을 수 있습니다.
-
SLOPE 및 INTERCEPT가 #DIV/0! 오류를 반환합니다. SLOPE 및 INTERCEPT 함수 알고리즘은 오직 하나의 답만 찾도록 디자인되어 있지만 이 경우 답이 여러 개일 수 있기 때문입니다.
-
-
LOGEST를 사용하여 다른 회귀 유형에 대한 통계를 구하는 것 외에도 LINEST를 통해 x 및 y 변수의 함수를 LINEST에 대한 x 및 y 계열로 입력하여 다른 회귀 유형의 범위를 계산할 수 있습니다. 예를 들어 다음과 같은 수식이 있다고 가정해 봅니다.
=LINEST(y 값, x 값^COLUMN($A:$C))
위의 수식은 다음 3차식(차수가 3인 다항식) 근사값을 구할 y 값으로 된 열과 x 값으로 된 열이 하나씩 있을 때 올바르게 계산됩니다.
y = m1*x + m2*x^2 + m3*x^3 + b
이 수식을 조정하여 다른 유형의 회귀를 계산할 수 있지만 경우에 따라 출력 값과 다른 통계를 조정해야 할 수도 있습니다.
-
LINEST 함수에서 반환되는 F-검정 값은 FTEST 함수에서 반환되는 F-검정 값과 다릅니다. LINEST는 F 통계량을 반환하고, FTEST는 확률을 반환합니다.
예제
예제 1 - 기울기와 y 절편
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
알려진 y |
알려진 x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
결과(기울기) |
결과(y 절편) |
|
2 |
1 |
|
수식(셀 A7:B7의 배열 수식) |
|
|
=LINEST(A2:A5,B2:B5,,FALSE) |
예제 2 - 단순 선형 회귀
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
월 |
판매액 |
|---|---|
|
1 |
\3,100,000 |
|
2 |
\4,500,000 |
|
3 |
\4,400,000 |
|
4 |
\5,400,000 |
|
5 |
\7,500,000 |
|
6 |
\8,100,000 |
|
수식 |
결과 |
|
=SUM(LINEST(B1:B6, A1:A6)*{9,1}) |
\11,000,000 |
|
1월부터 6월까지의 판매액을 기준으로 아홉 번째 달의 예상 판매액을 계산합니다. |
예제 3 - 다중 선형 회귀
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
사무실 면적(x1) |
사무실 수(x2) |
출입구 수(x3) |
건축 연수(x4) |
평가액(y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
\142,000,000 |
|
2333 |
2 |
2 |
12 |
\144,000,000 |
|
2356 |
3 |
1.5 |
33 |
\151,000,000 |
|
2379 |
3 |
2 |
43 |
\150,000,000 |
|
2402 |
2 |
3 |
53 |
\139,000,000 |
|
2425 |
4 |
2 |
23 |
\169,000,000 |
|
2448 |
2 |
1.5 |
99 |
\126,000,000 |
|
2471 |
2 |
2 |
34 |
\142,900,000 |
|
2494 |
3 |
3 |
23 |
\163,000,000 |
|
2517 |
4 |
4 |
55 |
\169,000,000 |
|
2540 |
2 |
3 |
22 |
\149,000,000 |
|
-234.2371645 |
||||
|
13.26801148 |
||||
|
0.996747993 |
||||
|
459.7536742 |
||||
|
1732393319 |
||||
|
수식(A19에 입력된 동적 배열 수식) |
||||
|
=LINEST(E2:E12,A2:D12,TRUE,TRUE) |
예 4 - F 및 r2 통계 사용
앞의 예에서 결정 계수 또는 r2는 0.99675입니다(LINEST에 대한 출력의 셀 A17 참조). 이는 독립 변수와 판매 가격. 높은 r2 값의 결과가 우연한 것인지 판단하기 위하여 F 통계를 사용할 수 있습니다.
사실은 변수 사이에 아무런 관계가 없지만, 겨우 11개 사무실 건물을 표본으로 채택했기 때문에 통계적 분석 결과는 강한 상관 관계를 나타낸 것이라고 가정해 보세요. 상관 관계가 있다는 잘못된 결론을 내릴 확률을 고려하여 조건 "Alpha"를 사용합니다.
LINEST 함수 결과의 F와 df 값을 사용하여 더 높은 F 값이 발생할 가능성을 평가할 수 있습니다. 게시된 F 분포표의 임계값과 F를 비교하거나 Excel의 FDIST 함수를 사용하여 더 큰 F 값이 발생할 확률을 계산할 수 있습니다. 적당한 F 분포의 자유도는 v1과 v2입니다. n이 데이터 요소의 개수이고 const가 TRUE이거나 생략되면 v1 = n - df - 1, v2 = df입니다. const가 FALSE이면 v1 = n - df, v2 = df입니다. FDIST(F,v1,v2) 구문이 있는 FDIST 함수는 더 높은 F 값이 발생할 확률을 계산합니다. 이 예제에서 df는 6(B18 셀)이고 F는 459.753674(A18 셀)입니다.
Alpha 값이 0.05, v1 = 11 - 6 - 1 = 4, v2 = 6이라고 가정하면 F 임계값은 4.53입니다. F = 459.753674는 4.53보다 훨씬 크므로 이 정도로 높은 F 값이 우연히 발생할 가능성은 극히 희박합니다. alpha = 0.05인 경우, F가 임계값 4.53을 초과하면 known_y’s와 known_x’s 간에 관계가 없다는 가설은 기각됩니다. Excel의 FDIST 함수를 사용하여 이 정도 크기의 F 값이 우연히 발생할 확률을 계산할 수 있습니다. 예를 들어 FDIST(459.753674, 4, 6) = 1.37E-7, 즉 극히 적은 확률입니다. 표에서 F 임계값을 찾거나 FDIST 함수를 사용하면, 회귀 방정식은 이 지역 사무실 건물의 평가액을 예측할 때 유용하다는 결론을 내릴 수 있습니다. 앞 단락에서 계산된 정확한 v1과 v2 값을 사용하는 것이 매우 중요합니다.
예제 5 - t 통계 계산
다른 가설 검정으로 각 기울기 계수가 예제 3에서와 같이 사무실 건물의 평가액을 어림잡는 데 유용한지 판단합니다. 예를 들어 건축 연수 계수의 통계적 중요성을 검정하기 위해 -234.24(건축 연수의 기울기 계수)를 13.268(A15 셀에 있는 건축 연수 계수의 표준 오차 추정값)로 나눕니다. 다음은 t 관측값입니다.
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
f의 절대값이 충분히 높으면 기울기 계수가 예제 3에서와 같이 사무실 건물의 평가액을 추정하는 데 유용하다는 결론을 내릴 수 있습니다. 아래 표에서는 4개의 t 관측값을 보여 줍니다.
통계표에서 자유도 6, Alpha = 0.05인 양측 검정 t 임계값이 2.447임을 확인할 수 있습니다. Excel의 TINV 함수로도 이 임계값을 찾을 수 있습니다. 즉, TINV(0.05,6) = 2.447입니다. t(17.7)의 절대값이 2.447보다 크므로 사무실 건물의 평가액을 추정할 때 건축 연수가 중요한 변수가 됩니다. 다른 독립 변수도 유사한 방법으로 검정할 수 있습니다. 다음은 각 독립 변수의 t 관측값입니다.
|
변수 |
t 관측값 |
|---|---|
|
사무실 면적 |
5.1 |
|
사무실 수 |
31.3 |
|
출입구 수 |
4.8 |
|
건축 연수 |
17.7 |
이러한 값은 절대값이 2.447보다 크므로 회귀 방정식에 사용된 모든 변수는 이 지역 사무실 건물의 평가액을 추정하는 데 유용합니다.









