
Programmā Excel varat izveidot datu modeļus, kas ietver miljoniem rindu, un pēc tam veikt jaudīgu datu analīzi pret šiem modeļiem. Datu modeļus var izveidot ar vai bez pievienojumprogrammas Power Pivot, lai atbalstītu jebkādu skaitu rakurstabulu, diagrammu un Power View vizualizāciju vienā darbgrāmatā.
Lai gan programmā Excel var viegli izveidot apjomīgus datu modeļus, ir vairāki iemesli to nedarīt. Pirmkārt, lielie modeļi, kas satur daudzas tabulas un kolonnas, ir pārspīlēti lielākajai daļai analīžu un veido apgrūtinošu lauku sarakstu. Otrkārt, lielie modeļi izmanto vērtīgo atmiņu, negatīvi ietekmējot citas lietojumprogrammas un atskaites, kas izmanto tos pašus sistēmas resursus. Visbeidzot, pakalpojumā Microsoft 365 gan SharePoint Online, gan Excel Web App ierobežo Excel faila lielumu līdz 10 MB. Darbgrāmatu datu modeļos, kuros ir miljoniem rindu, 10 MB ierobežojums tiks sasniegts diezgan ātri. Skatiet datu modeļa specifikāciju un ierobežojumus.
Šajā rakstā uzzināsit, kā izveidot cieši konstruētu modeli, ar kuru ir vieglāk strādāt un kura atmiņas apjoms ir mazāks. Laiks, kas veltīts efektīvas modeļu noformējuma paraugprakses apguvei, atmaksāsies jebkuram izveidotam un lietotam modelim — gan programmā Excel, gan Microsoft 365, gan SharePoint Online, gan Office Web Apps Server vai SharePoint vidē.
Apsveriet iespēju izmantot arī darbgrāmatas lieluma optimizētāju. Tas analizē jūsu Excel darbgrāmatu un, ja iespējams, vēl vairāk to saspiež. Lejupielādējiet darbgrāmatas lieluma optimizētāju.
Tēmas šajā rakstā
Nekas nav labāks par neesošu kolonnu, ja atmiņas lietojums ir zems
Ko darīt, ja mums ir nepieciešama kolonna; Vai mēs joprojām varam samazināt tās kosmosa izmaksas?
Saspiešanas pakāpes un atmiņas analīzes dzinējs
Lai datus glabātu atmiņā, datu modeļi programmā Excel izmanto atmiņas analīzes programmu. Dzinējs ievieš jaudīgas saspiešanas metodes, lai samazinātu uzglabāšanas prasības, samazinot rezultātu kopumu, līdz tas ir daļa no tā sākotnējā izmēra.
Var sagaidīt, ka datu modelis būs vidēji 7 līdz 10 reizes mazāks par tiem pašiem datiem tā izcelsmes punktā. Piemēram, importējot 7 MB datu no SQL Server datu bāzes, Excel datu modelis var būt 1 MB vai mazāks. Faktiski sasniegtā saspiešanas pakāpe galvenokārt ir atkarīga no unikālo vērtību skaita katrā kolonnā. Jo vairāk unikālu vērtību, jo vairāk atmiņas ir nepieciešama to glabāšanai.
Kāpēc mēs runājam par saspiešanu un unikālām vērtībām? Jo efektīva modeļa, kas minimizē atmiņas lietojumu, izveide ir saistīta ar saspiešanas maksimizāciju, un vienkāršākais veids, kā to izdarīt, ir atbrīvoties no kolonnām, kas patiesībā nav vajadzīgas, īpaši, ja šajās kolonnās ir daudz unikālu vērtību.
Piezīme
Atsevišķu kolonnu uzglabāšanas prasību atšķirības var būt milzīgas. Dažos gadījumos ir labāk, ja ir vairākas kolonnas ar nelielu unikālo vērtību skaitu, nevis viena kolonna ar lielu unikālo vērtību skaitu. Sadaļā par datuma un laika optimizācijām šī metode ir detalizēti aprakstīta.
Nekas nav labāks par neesošu kolonnu, ja atmiņas lietojums ir zems
Visefektīvākā atmiņas izmantošana ir kolonna, kuru nekad neesat importējis. Ja vēlaties izveidot efektīvu modeli, pārskatiet katru kolonnu un pajautājiet sev, vai tā palīdz veikt analīzi. Ja tā nav vai neesat pārliecināts, izlaidiet to. Vajadzības gadījumā vēlāk varat pievienot jaunas kolonnas.
Divi kolonnu piemēri, kas vienmēr jāizslēdz
Pirmais piemērs attiecas uz datiem, kas iegūti no datu noliktavas. Datu noliktavā bieži sastopami ETL procesu artefakti, kas ielādē un atsvaidzina datus noliktavā. Kolonnas, piemēram, "izveides datums", "atjaunināšanas datums" un "ETL palaišana", tiek izveidotas, kad dati tiek ielādēti. Neviena no šīm kolonnām modelī nav nepieciešama, un datu importēšanas laikā tai ir jānoņem atlase.
Otrajā piemērā primārās atslēgas kolonna tiek izlaista, importējot faktu tabulu.
Daudzām tabulām, tostarp faktu tabulām, ir primārās atslēgas. Lielākajai daļai tabulu, piemēram, tām, kas satur klientu, darbinieku vai pārdošanas datus, ir nepieciešama tabulas primārā atslēga, lai to varētu izmantot relāciju izveidei modelī.
Faktu tabulas atšķiras. Faktu tabulā primārā atslēga tiek izmantota, lai unikāli identificētu katru rindu. Lai gan tas ir nepieciešams normalizēšanas nolūkos, tas ir mazāk noderīgs datu modelī, kur vēlaties izmantot tikai šīs kolonnas analīzei vai tabulu relāciju izveidei. Šī iemesla dēļ, importējot no faktu tabulas, neiekļaujiet tās primāro atslēgu. Primārās atslēgas faktu tabulā aizņem ļoti daudz vietas modelī, tomēr nesniedz nekādas priekšrocības, jo tās nevar izmantot relāciju izveidei.
Piezīme
Datu noliktavās un daudzdimensiju datu bāzēs lielas tabulas, kas sastāv galvenokārt no skaitliskiem datiem, bieži dēvē par "faktu tabulām". Faktu tabulās parasti ir iekļauti biznesa veiktspējas vai transakciju dati, piemēram, pārdošanas un izmaksu datu punkti, kas ir apkopoti un līdzināti ar organizācijas vienībām, produktiem, tirgus segmentiem, ģeogrāfiskajiem reģioniem utt. Visas faktu tabulas kolonnas, kurās ir biznesa dati vai kuras var izmantot, lai izveidotu savstarpējas atsauces uz citās tabulās glabātiem datiem, ir jāiekļauj modelī, lai atbalstītu datu analīzi. Kolonna, kuru vēlaties izslēgt, ir faktu tabulas primārās atslēgas kolonna, kurā ir unikālas vērtības, kas pastāv tikai faktu tabulā un nekur citur. Tā kā faktu tabulas ir tik lielas, vieni no lielākajiem modeļu efektivitātes ieguvumiem rodas, izslēdzot rindas vai kolonnas no faktu tabulām.
Kā izslēgt nevajadzīgas kolonnas
Efektīvie modeļi satur tikai tās kolonnas, kas darbgrāmatā faktiski ir nepieciešamas. Ja vēlaties kontrolēt, kuras kolonnas ir iekļautas modelī, datu importēšanai jāizmanto pievienojumprogrammas Power Pivot tabulas importēšanas vednis , nevis Excel dialoglodziņš Datu importēšana.
Palaižot tabulas importēšanas vedni, varat atlasīt importējamās tabulas.

Katrai tabulai varat noklikšķināt uz pogas Priekšskatīt & Filtrēt un atlasīt tabulas daļas, kas jums patiešām ir vajadzīgas. Ieteicams vispirms noņemt atzīmi visām kolonnām un pēc tam, izvērtējot, vai tās ir nepieciešamas analīzei, turpināt pārbaudīt vajadzīgās kolonnas.

Vai var filtrēt tikai nepieciešamās rindas?
Daudzās tabulās uzņēmumu datu bāzēs un datu noliktavās ir vēsturiski dati, kas uzkrāti ilgākā laika periodā. Turklāt jūs varat konstatēt, ka jūs interesējošajās tabulās ir informācija par uzņēmējdarbības jomām, kas nav nepieciešama konkrētajai analīzei.
Izmantojot tabulas importēšanas vedni, varat filtrēt vēsturiskos vai nesaistītos datus, tādējādi ietaupot daudz vietas modelī. Tālāk esošajā attēlā datuma filtrs tiek izmantots, lai izgūtu tikai rindas, kurās ir šī gada dati, izņemot vēsturiskos datus, kas nav nepieciešami.

Ko darīt, ja mums ir nepieciešama kolonna; Vai mēs joprojām varam samazināt tās kosmosa izmaksas?
Ir dažas papildu metodes, kuras varat lietot, lai kolonnu labāk izmantotu saspiešanai. Atcerieties, ka vienīgā kolonnas īpašība, kas ietekmē saspiešanu, ir unikālo vērtību skaits. Šajā sadaļā ir sniegta informācija par to, kā dažas kolonnas var modificēt, lai samazinātu unikālo vērtību skaitu.
Datuma/laika kolonnu modificēšana
Daudzos gadījumos datuma un laika kolonnas aizņem daudz vietas. Par laimi, ir vairāki veidi, kā samazināt šī datu tipa krātuves prasības. Metodes var atšķirties atkarībā no kolonnas izmantošanas veida un jūsu ērtības līmeņa, veidojot SQL vaicājumus.
Datuma un laika kolonnās ir datuma daļa un laiks. Kad sev jautājat, vai jums ir vajadzīga kolonna, uzdodiet vienu un to pašu jautājumu vairākas reizes kolonnā Datums/laiks:
- Vai man ir nepieciešama laika daļa?
- Vai man ir nepieciešama laika daļa stundu līmenī? , minūtes? , sekundes? , milisekundes?
- Vai ir izveidotas vairākas datuma/laika kolonnas tāpēc, ka vēlos aprēķināt starpību starp tām, vai vienkārši apkopot datus pēc gada, mēneša, ceturkšņa utt.
Atbildes uz katru no šiem jautājumiem nosaka jūsu iespējas darbam ar kolonnu Datums/laiks.
Visiem šiem risinājumiem ir nepieciešama SQL vaicājuma modificēšana. Lai atvieglotu vaicājumu modificēšanu, katrā tabulā jāatfiltrē vismaz viena kolonna. Filtrējot kolonnu, jūs maināt vaicājuma uzbūvi no saīsināta formāta (SELECT *) uz priekšrakstu SELECT, kurā iekļauti pilni kolonnu nosaukumi, kurus ir vieglāk modificēt.
Apskatīsim jums izveidotos vaicājumus. Dialoglodziņā Tabulas rekvizīti varat pārslēgties uz vaicājumu redaktoru un skatīt pašreizējo SQL vaicājumu katrai tabulai.

Sadaļā Tabulas rekvizīti atlasiet Vaicājumu redaktors.
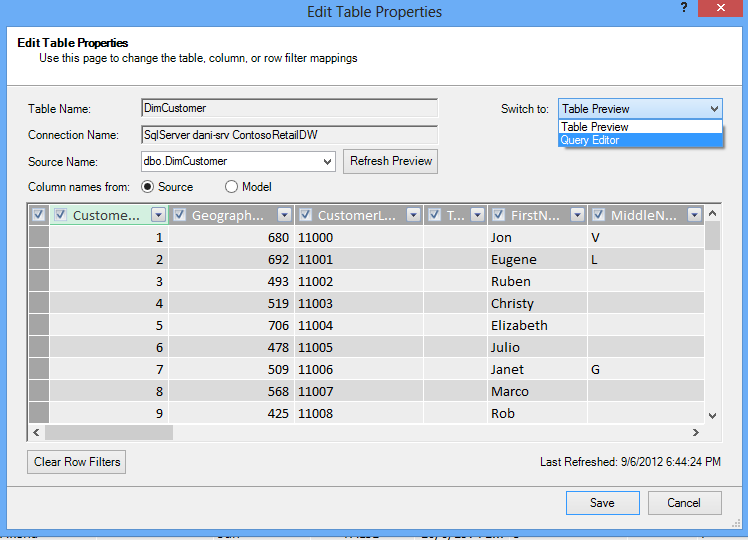
Vaicājumu redaktors rāda SQL vaicājumu, ko izmanto tabulas aizpildīšanai. Ja importēšanas laikā atfiltrējāt kādu kolonnu, vaicājumā tiek iekļauti pilni kolonnu nosaukumi:

Savukārt, ja importējāt tabulu kopumā, nenoņemot atzīmi nevienai kolonnai un nelietojot filtrus, vaicājums būs redzams kā "Select * from ", ko būs grūtāk modificēt: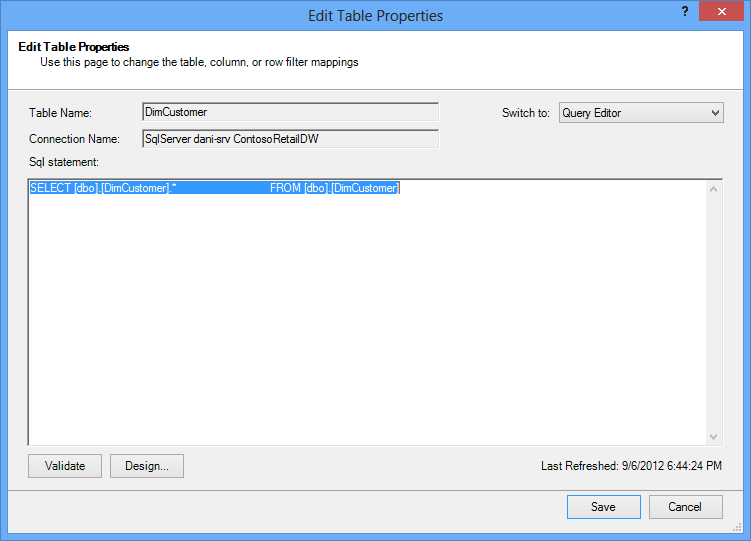
|
|---|
SQL vaicājuma modificēšana
Tagad, kad zināt, kā atrast vaicājumu, varat to modificēt, lai vēl vairāk samazinātu modeļa lielumu.
- Ja kolonnām, kurās ir valūtas vai decimāldaļskaitļi, nav vajadzīgi decimālskaitļi, izmantojiet šo sintaksi, lai atbrīvotos no decimāldaļskaitļiem:
"SELECT ROUND([Decimal_column_name],0)... .”
Ja jums ir vajadzīgi centi, bet ne centu daļas, aizstājiet 0 ar 2. Ja izmantojat negatīvus skaitļus, varat noapaļot uz vienībām, desmitiem, simtiem utt. - Ja jums ir kolonna Datums/laiks ar nosaukumu dbo. Liels galds. [Datums un laiks] un jums nav nepieciešama daļa Laiks, izmantojiet sintaksi, lai atbrīvotos no laika:
"SELECT CAST (dbo. Liels galds. [Datums, laiks] kā datums) AS [Datums, laiks]) " - Ja jums ir kolonna Datums/laiks ar nosaukumu dbo. Liels galds. [Datums un laiks] un jums ir nepieciešama gan datuma, gan laika daļas; SQL vaicājumā izmantojiet vairākas kolonnas, nevis vienu kolonnu Datums/laiks:
"SELECT CAST (dbo. Liels galds. [Datums Laiks] kā datums ) AS [Datums laiks],
DatePart(hh, dbo. Liels galds. [Datums, laiks]) kā [datums, laiks, stundas],
DatePart(mi, DBO. Liels galds. [Datums, laiks]) kā [Datums, laiks, minūtes],
DatePart(ss, dbo. Liels galds. [Datums, laiks]) kā [datums, laiks, sekundes],
DatePart(MS, DBO. Liels galds. [Datums, laiks]) kā [datums, laiks, milisekundes]"
Izmantojiet tik daudz kolonnu, cik nepieciešams, lai katru daļu saglabātu atsevišķās kolonnās. - Ja nepieciešamas stundas un minūtes un vēlaties tās apvienot vienā laika kolonnā, varat izmantot šādu sintaksi:
Timefromparts(datepart(hh, dbo. Liels galds. [Date Time]), DatePart(mm, dbo. Liels galds. [Datums, laiks])) kā [Datums, laiks, stundas_minūte] - Ja jums ir divas datuma/laika kolonnas, piemēram, [Sākuma laiks] un [Beigu laiks], un jums patiešām ir vajadzīga laika starpība starp tām sekundēs kā kolonna ar nosaukumu [Ilgums], noņemiet abas kolonnas no saraksta un pievienojiet:
"datediff(ss,[Start Date],[End Date]) AS [Duration]"
Ja izmantosit atslēgvārdu ms, nevis ss, saņemsit ilgumu milisekundēs
DAX aprēķināto mēru izmantošana kolonnu vietā
Ja esat strādājis ar DAX izteiksmju valodu iepriekš, iespējams, jau zināt, ka aprēķinātās kolonnas tiek izmantotas, lai atvasinātu jaunas kolonnas, ņemot vērā kādu citu kolonnu modelī, bet aprēķinātie mēri modelī tiek definēti vienreiz, bet novērtēti tikai tad, ja tiek izmantoti rakurstabulā vai citā atskaitē.
Viens no atmiņas taupīšanas paņēmieniem ir parasto vai aprēķināto kolonnu aizstāšana ar aprēķinātiem mēriem. Klasiskais piemērs ir Vienības cena, Daudzums un Kopsumma. Ja jums ir visi trīs punkti, varat ietaupīt vietu, saglabājot tikai divus punktus un aprēķinot trešo, izmantojot DAX.
Kuras 2 kolonnas ir jāsaglabā?
Iepriekšējā piemērā paturiet laukus Daudzums un Vienības cena. Šīm divām summām ir mazāk vērtību nekā kopsummai. Lai aprēķinātu kopsummu, pievienojiet aprēķinātu mēru, piemēram:
"TotalSales:=sumx('Pārdošanas tabula','Pārdošanas tabula','Pārdošanas tabula'[Vienības cena]*'Pārdošanas tabula'[Daudzums])"
Aprēķinātās kolonnas ir kā parastas kolonnas, jo abas aizņem vietu modelī. Turpretī aprēķinātie mērījumi tiek aprēķināti lidojumā un neaizņem vietu.
Secinājums
Šajā rakstā mēs runājām par vairākām pieejām, kas var palīdzēt jums izveidot atmiņas efektīvāku modeli. Veids, kā samazināt datu modeļa faila lielumu un atmiņas prasības, ir samazināt kolonnu un rindu kopējo skaitu, kā arī katrā kolonnā parādāmo unikālo vērtību skaitu. Lūk, dažas metodes, ko aplūkojām:
- Kolonnu noņemšana, protams, ir labākais veids, kā ietaupīt vietu. Izlemiet, kuras kolonnas jums patiešām ir vajadzīgas.
- Dažreiz varat noņemt kolonnu un aizstāt to ar aprēķinātu rādītāju tabulā.
- Iespējams, nevajadzēs visas tabulas rindas. Tabulas importēšanas vednī varat filtrēt rindas.
- Parasti vienas kolonnas sadalīšana vairākās atsevišķās daļās ir labs veids, kā samazināt unikālo vērtību skaitu kolonnā. Katrai daļai būs neliels unikālo vērtību skaits, un kopējā summa būs mazāka nekā sākotnēji vienotā kolonna.
- Daudzos gadījumos atsevišķas daļas ir jāizmanto kā datu griezumi atskaitēs. Ja nepieciešams, varat izveidot hierarhijas no tādām daļām kā stundas, minūtes un sekundes.
- Bieži vien arī kolonnās ir vairāk informācijas, nekā nepieciešams. Piemēram, pieņemsim, ka kolonnā tiek glabāti decimālskaitļi, bet jūs esat lietojis formatējumu, lai paslēptu visus decimāldaļskaitļus. Noapaļošana var būt ļoti efektīva, samazinot skaitliskas kolonnas lielumu.
Tagad, kad esat darījis visu iespējamo, lai samazinātu darbgrāmatas lielumu, apsveriet iespēju palaist arī darbgrāmatas lieluma optimizētāju. Tas analizē jūsu Excel darbgrāmatu un, ja iespējams, vēl vairāk to saspiež. Lejupielādējiet darbgrāmatas lieluma optimizētāju.
Saistītās saites
Datu modeļa specifikācija un ierobežojumi
Darbgrāmatas lieluma optimizētājs
PowerPivot: jaudīga datu analīze un datu modelēšana programmā Excel