
Um banco de dados projetado corretamente fornece acesso a informações atualizadas e precisas. Como um design correto é essencial para alcançar suas metas em trabalhar com um banco de dados, investir o tempo necessário para aprender os princípios do bom design faz sentido. No final, é muito mais provável que você acabe com um banco de dados que atenda às suas necessidades e possa acomodar facilmente as alterações.
Este artigo fornece diretrizes para planejar um banco de dados de área de trabalho. Você aprenderá a decidir quais informações você precisa, como dividir essas informações nas tabelas e colunas apropriadas e como essas tabelas se relacionam entre si. Você deve ler este artigo antes de criar seu primeiro banco de dados da área de trabalho.
Neste artigo
Alguns termos de banco de dados para saber
Access organiza suas informações em tabelas: listas de linhas e colunas que lembram o bloco de um contador ou uma planilha. Em um banco de dados simples, você pode ter apenas uma tabela. Para a maioria dos bancos de dados, você precisará de mais de um. Por exemplo, você pode ter uma tabela que armazena informações sobre produtos, outra tabela que armazena informações sobre pedidos e outra tabela com informações sobre clientes.
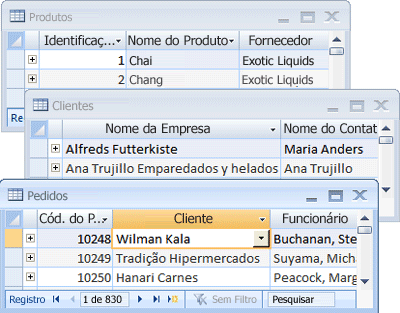
Cada linha é mais corretamente chamada de registro e cada coluna, um campo. Um registro é uma maneira significativa e consistente de combinar informações sobre algo. Um campo é um único item de informações – um tipo de item que aparece em cada registro. Na tabela Produtos, por exemplo, cada linha ou registro teria as informações sobre um produto. Cada coluna ou campo contém algum tipo de informação sobre o produto, por exemplo, nome ou preço.
O que é um bom design de banco de dados?
Determinados princípios orientam o processo de design do banco de dados. O primeiro princípio é que as informações duplicadas (também chamadas de dados redundantes) são ruins, pois desperdiçam espaço e aumentam a probabilidade de erros e inconsistências. O segundo princípio é que a correção e a integridade das informações são importantes. Se o banco de dados contiver informações incorretas, todos os relatórios que extraem informações do banco de dados também conterão informações incorretas. Como resultado, todas as decisões que você tomar com base nesses relatórios serão então mal informadas.
Um bom design de banco de dados é, portanto, aquele que:
-
Divide suas informações em tabelas baseadas em assunto para reduzir dados redundantes.
-
Fornece o Access com as informações necessárias para unir as informações nas tabelas, conforme necessário.
-
Ajuda a dar suporte e garantir a precisão e integridade de suas informações.
-
Acomoda suas necessidades de processamento de dados e relatórios.
O processo de design
O processo de design consiste nas seguintes etapas:
-
Determinar a finalidade do seu banco de dados
Isso ajuda a prepará-lo para as etapas restantes.
-
Localizar e organizar as informações necessárias
Reúna todos os tipos de informações que talvez você queira registrar no banco de dados, como nome do produto e número do pedido.
-
Dividir as informações em tabelas
Divida seus itens de informações em entidades ou entidades principais, como Produtos ou Pedidos. Cada assunto então se torna uma tabela.
-
Transformar itens de informações em colunas
Decida quais informações você deseja armazenar em cada tabela. Cada item se torna um campo e é exibido como uma coluna na tabela. Por exemplo, uma tabela Funcionários pode incluir campos como Sobrenome e Data de Contratação.
-
Especificar chaves primárias
Escolha a chave primária de cada tabela. A chave primária é uma coluna usada para identificar exclusivamente cada linha. Um exemplo pode ser ID do produto ou ID do pedido.
-
Configurar as relações de tabela
Olhe para cada tabela e decida como os dados em uma tabela estão relacionados aos dados em outras tabelas. Adicione campos a tabelas ou crie novas tabelas para esclarecer as relações, conforme necessário.
-
Refinar seu design
Analise seu design em busca de erros. Crie as tabelas e adicione alguns registros de dados de exemplo. Confira se você pode obter os resultados desejados em suas tabelas. Faça ajustes no design, conforme necessário.
-
Aplicar as regras de normalização
Aplique as regras de normalização de dados para ver se as tabelas estão estruturadas corretamente. Faça ajustes nas tabelas, conforme necessário.
Determinando a finalidade do banco de dados
É uma boa ideia anotar a finalidade do banco de dados no papel – sua finalidade, como você espera usá-lo e quem o usará. Para um pequeno banco de dados para uma empresa baseada em casa, por exemplo, você pode escrever algo simples como "O banco de dados do cliente mantém uma lista de informações do cliente com a finalidade de produzir emails e relatórios". Se o banco de dados for mais complexo ou for usado por muitas pessoas, como ocorre frequentemente em uma configuração corporativa, a finalidade poderá ser facilmente um parágrafo ou mais e deve incluir quando e como cada pessoa usará o banco de dados. A ideia é ter uma instrução de missão bem desenvolvida que possa ser encaminhada durante todo o processo de design. Ter essa instrução ajuda você a se concentrar em seus objetivos ao tomar decisões.
Localizar e organizar as informações necessárias
Para localizar e organizar as informações necessárias, comece com suas informações existentes. Por exemplo, você pode registrar pedidos de compra em um razão ou manter informações do cliente em formulários de papel em um armário de arquivos. Reúna esses documentos e liste cada tipo de informação mostrada (por exemplo, cada caixa que você preenche em um formulário). Se você não tiver formulários existentes, imagine que você precisa criar um formulário para registrar as informações do cliente. Quais informações você colocaria no formulário? Que caixas de preenchimento você criaria? Identifique e liste cada um desses itens. Por exemplo, suponha que atualmente você mantenha a lista de clientes em cartões de índice. Examinar esses cartões pode mostrar que cada cartão contém um nome, endereço, cidade, estado, código postal e número de telefone dos clientes. Cada um desses itens representa uma coluna potencial em uma tabela.
Ao preparar esta lista, não se preocupe em aperfeiçoá-la no início. Em vez disso, liste cada item que vem à mente. Se outra pessoa usar o banco de dados, peça suas ideias também. Você pode ajustar a lista mais tarde.
Em seguida, considere os tipos de relatórios ou emails que talvez você queira produzir do banco de dados. Por exemplo, você pode querer que um relatório de vendas de produtos mostre vendas por região ou um relatório de resumo de inventário que mostre os níveis de inventário do produto. Você também pode querer gerar cartas de formulário para enviar aos clientes que anunciam um evento de venda ou oferecem um prêmio. Crie o relatório em sua mente e imagine como ele seria. Quais informações você colocaria no relatório? Liste cada item. Faça o mesmo para a letra do formulário e para qualquer outro relatório que você preveja criar.

Pensar nos relatórios e emails que talvez você queira criar ajuda a identificar itens necessários em seu banco de dados. Por exemplo, suponha que você dê aos clientes a oportunidade de optar por atualizações de email periódicas (ou fora) e deseja imprimir uma listagem daqueles que optaram por entrar. Para registrar essas informações, você adiciona uma coluna "Enviar email" à tabela do cliente. Para cada cliente, você pode definir o campo como Sim ou Não.
O requisito para enviar mensagens de email aos clientes sugere outro item a ser registrado. Depois de saber que um cliente deseja receber mensagens de email, você também precisará saber o endereço de email para o qual enviá-las. Portanto, você precisa gravar um endereço de email para cada cliente.
Faz sentido construir um protótipo de cada relatório ou listagem de saída e considerar quais itens você precisará para produzir o relatório. Por exemplo, quando você examina uma carta de formulário, algumas coisas podem vir à mente. Se você quiser incluir uma saudação adequada – por exemplo, a cadeia de caracteres "Mr.", "Mrs." ou "Ms" que inicia uma saudação, você terá que criar um item de saudação. Além disso, você normalmente pode começar uma carta com "Caro Sr. Smith", em vez de "Querido. Sr. Sylvester Smith". Isso sugere que você normalmente deseja armazenar o sobrenome separado do primeiro nome.
Um ponto chave a ser lembrado é que você deve dividir cada informação em suas menores partes úteis. No caso de um nome, para disponibilizar o sobrenome prontamente, você dividirá o nome em duas partes : Nome e Sobrenome. Para classificar um relatório pelo sobrenome, por exemplo, ele ajuda a ter o sobrenome do cliente armazenado separadamente. Em geral, se você quiser classificar, pesquisar, calcular ou relatar com base em um item de informações, você deverá colocar esse item em seu próprio campo.
Pense nas perguntas que talvez você queira que o banco de dados responda. Por exemplo, quantas vendas do seu produto em destaque você fechou no mês passado? Onde moram seus melhores clientes ? Quem é o fornecedor do seu produto mais vendido? A antecipação dessas perguntas ajuda você a zero em itens adicionais a serem registrados.
Depois de coletar essas informações, você está pronto para a próxima etapa.
Dividindo as informações em tabelas
Para dividir as informações em tabelas, escolha as entidades principais ou as entidades. Por exemplo, depois de encontrar e organizar informações para um banco de dados de vendas de produtos, a lista preliminar pode ser semelhante a esta:

As principais entidades mostradas aqui são os produtos, os fornecedores, os clientes e os pedidos. Portanto, faz sentido começar com essas quatro tabelas: uma para fatos sobre produtos, uma para fatos sobre fornecedores, uma para fatos sobre clientes e outra para fatos sobre pedidos. Embora isso não conclua a lista, é um bom ponto de partida. Você pode continuar a refinar essa lista até ter um design que funcione bem.
Ao examinar pela primeira vez a lista preliminar de itens, você poderá ser tentado a colocá-los todos em uma única tabela, em vez dos quatro mostrados na ilustração anterior. Você aprenderá aqui por que isso é uma má idéia. Considere por um momento, a tabela mostrada aqui:
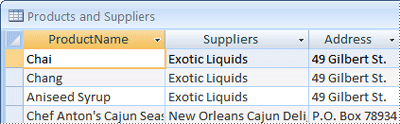
Nesse caso, cada linha contém informações sobre o produto e seu fornecedor. Como você pode ter muitos produtos do mesmo fornecedor, o nome do fornecedor e as informações de endereço devem ser repetidos muitas vezes. Isso desperdiça espaço em disco. Registrar as informações do fornecedor apenas uma vez em uma tabela fornecedores separada e, em seguida, vincular essa tabela à tabela Produtos, é uma solução muito melhor.
Um segundo problema com esse design ocorre quando você precisa modificar informações sobre o fornecedor. Por exemplo, suponha que você precise alterar o endereço de um fornecedor. Como ele aparece em vários lugares, talvez você acidentalmente altere o endereço em um só lugar, mas esqueça de alterá-lo em outros. Gravar o endereço do fornecedor em apenas um local resolve o problema.
Ao projetar seu banco de dados, sempre tente registrar cada fato apenas uma vez. Se você se encontrar repetindo as mesmas informações em mais de um lugar, como o endereço de um fornecedor específico, coloque essas informações em uma tabela separada.
Por fim, suponha que haja apenas um produto fornecido pela Vinícola Coho e você queira excluir o produto, mas mantenha o nome do fornecedor e as informações de endereço. Como você excluiria o registro do produto sem perder também as informações do fornecedor? Isso não é possível. Como cada registro contém fatos sobre um produto, bem como fatos sobre um fornecedor, você não pode excluir um sem excluir o outro. Para manter esses fatos separados, você deve dividir uma tabela em duas: uma tabela para informações do produto e outra tabela para informações de fornecedor. A exclusão de um registro de produto deve excluir apenas os fatos sobre o produto, não os fatos sobre o fornecedor.
Depois de escolher o assunto representado por uma tabela, as colunas nessa tabela devem armazenar fatos apenas sobre o assunto. Por exemplo, a tabela do produto deve armazenar fatos apenas sobre produtos. Como o endereço do fornecedor é um fato sobre o fornecedor e não um fato sobre o produto, ele pertence à tabela de fornecedores.
Transformando itens de informação em colunas
Para determinar as colunas em uma tabela, decida quais informações você precisa acompanhar sobre o assunto registrado na tabela. Por exemplo, para a tabela Clientes, Nome, Endereço, Cidade-Estado-Zip, Enviar email, Saudação e endereço de email incluem uma boa lista inicial de colunas. Cada registro na tabela contém o mesmo conjunto de colunas, para que você possa armazenar Nome, Endereço, Cidade-Estado-Zip, Enviar e-mail, Saudação e informações de endereço de email para cada registro. Por exemplo, a coluna de endereços contém os endereços dos clientes. Cada registro contém dados sobre um cliente e o campo de endereço contém o endereço desse cliente.
Depois de determinar o conjunto inicial de colunas para cada tabela, você poderá refinar ainda mais as colunas. Por exemplo, faz sentido armazenar o nome do cliente como duas colunas separadas: nome e sobrenome, para que você possa classificar, pesquisar e indexar apenas nessas colunas. Da mesma forma, o endereço consiste em cinco componentes separados, endereço, cidade, estado, código postal e país/região, e também faz sentido armazená-los em colunas separadas. Se você quiser executar uma pesquisa, filtrar ou classificar operação por estado, por exemplo, precisará das informações de estado armazenadas em uma coluna separada.
Você também deve considerar se o banco de dados conterá informações de origem doméstica ou internacionais também. Por exemplo, se você planeja armazenar endereços internacionais, é melhor ter uma coluna Region em vez de Estado, pois essa coluna pode acomodar estados domésticos e regiões de outros países/regiões. Da mesma forma, o Código Postal faz mais sentido do que o CEP se você vai armazenar endereços internacionais.
A lista a seguir mostra algumas dicas para determinar suas colunas.
-
Não inclua dados calculados
Na maioria dos casos, você não deve armazenar o resultado de cálculos em tabelas. Em vez disso, você pode fazer com que o Access execute os cálculos quando quiser ver o resultado. Por exemplo, suponha que haja um relatório Products On Order que exibe o subtotal de unidades em ordem para cada categoria de produto no banco de dados. No entanto, não há nenhuma coluna subtotal Units On Order em qualquer tabela. Em vez disso, a tabela Produtos inclui uma coluna Units On Order que armazena as unidades em ordem para cada produto. Usando esses dados, o Access calcula o subtotal sempre que você imprime o relatório. O subtotal em si não deve ser armazenado em uma tabela.
-
Armazenar informações em suas menores partes lógicas
Você pode ser tentado a ter um único campo para nomes completos ou para nomes de produtos, juntamente com as descrições do produto. Se você combinar mais de um tipo de informação em um campo, é difícil recuperar fatos individuais mais tarde. Tente dividir informações em partes lógicas; por exemplo, crie campos separados para nome e sobrenome ou para nome do produto, categoria e descrição.

Depois de refinar as colunas de dados em cada tabela, você estará pronto para escolher a chave primária de cada tabela.
Especificando chaves primárias
Cada tabela deve incluir uma coluna ou um conjunto de colunas que identifica exclusivamente cada linha armazenada na tabela. Geralmente, esse é um número de identificação exclusivo, como um número de ID do funcionário ou um número de série. Na terminologia do banco de dados, essas informações são chamadas de chave primária da tabela. O Access usa campos-chave primários para associar rapidamente dados de várias tabelas e reunir os dados para você.
Se você já tiver um identificador exclusivo para uma tabela, como um número de produto que identifica exclusivamente cada produto em seu catálogo, poderá usar esse identificador como a chave primária da tabela , mas somente se os valores nesta coluna sempre forem diferentes para cada registro. Você não pode ter valores duplicados em uma chave primária. Por exemplo, não use os nomes das pessoas como uma chave primária, porque os nomes não são exclusivos. Você poderia facilmente ter duas pessoas com o mesmo nome na mesma tabela.
Uma chave primária deve sempre ter um valor. Se o valor de uma coluna pode ficar sem sinal ou desconhecido (um valor ausente) em algum momento, ele não poderá ser usado como um componente em uma chave primária.
Você sempre deve escolher uma chave primária cujo valor não será alterado. Em um banco de dados que usa mais de uma tabela, a chave primária de uma tabela pode ser usada como referência em outras tabelas. Se a chave primária for alterada, a alteração também deverá ser aplicada em todos os lugares em que a chave for referenciada. Usar uma chave primária que não será alterada reduz a chance de que a chave primária possa ficar fora de sincronização com outras tabelas que a referenciam.
Geralmente, um número único arbitrário é usado como a chave primária. Por exemplo, você pode atribuir a cada pedido um número de pedido exclusivo. A única finalidade do número de pedido é identificar uma ordem. Uma vez atribuído, ele nunca é alterado.
Se você não tiver em mente uma coluna ou um conjunto de colunas que possam fazer uma boa chave primária, considere usar uma coluna que tenha o tipo de dados AutoNumber. Quando você usa o tipo de dados AutoNumber, o Access atribui automaticamente um valor para você. Esse identificador não tem fatos; não contém informações factuais que descrevem a linha que ela representa. Identificadores sem fatos são ideais para uso como chave primária porque não são alterados. Uma chave primária que contém fatos sobre uma linha – um número de telefone ou um nome de cliente, por exemplo – é mais provável que seja alterada, pois as próprias informações factuais podem ser alteradas.
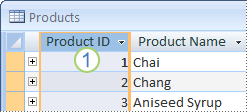
1. Um conjunto de colunas para o tipo de dados AutoNumber geralmente faz uma boa chave primária. Nenhuma ID de produto é a mesma.
Em alguns casos, você pode querer usar dois ou mais campos que, juntos, fornecem a chave primária de uma tabela. Por exemplo, uma tabela Detalhes do Pedido que armazena itens de linha para pedidos usaria duas colunas em sua chave primária: ID do pedido e ID do produto. Quando uma chave primária emprega mais de uma coluna, ela também é chamada de chave composta.
Para o banco de dados de vendas de produtos, você pode criar uma coluna AutoNumber para cada uma das tabelas para servir como chave primária: ProductID para a tabela Produtos, OrderID para a tabela Orders, CustomerID para a tabela Clientes e SupplierID para a tabela Fornecedores.

Criando as relações de tabela
Agora que você dividiu suas informações em tabelas, você precisa de uma maneira de reunir as informações novamente de maneiras significativas. Por exemplo, o formulário a seguir inclui informações de várias tabelas.
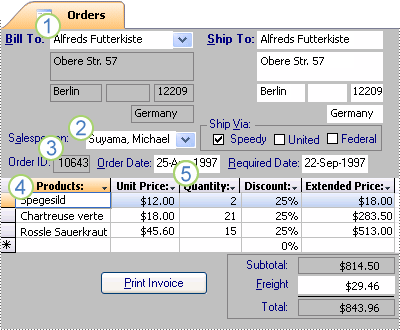
1. As informações desse formulário são originárias da tabela Clientes...
2. ... a tabela Funcionários...
3. ... a tabela Ordens...
4. ... a tabela Produtos...
5. ... e a tabela Detalhes do Pedido.
O acesso é um sistema de gerenciamento de banco de dados relacional. Em um banco de dados relacional, você divide suas informações em tabelas separadas baseadas em assunto. Em seguida, você usa relações de tabela para reunir as informações conforme necessário.
Criando uma relação de um para muitos
Considere este exemplo: as tabelas Fornecedores e Produtos no banco de dados de pedidos de produto. Um fornecedor pode fornecer qualquer número de produtos. Segue-se que, para qualquer fornecedor representado na tabela Fornecedores, pode haver muitos produtos representados na tabela Produtos. A relação entre a tabela Fornecedores e a tabela Produtos é, portanto, uma relação de um para muitos.
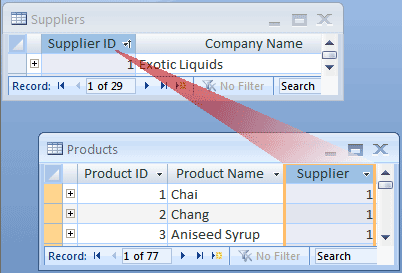
Para representar uma relação de um para muitos no design do banco de dados, pegue a chave primária no lado "um" da relação e adicione-a como uma coluna ou colunas adicionais à tabela no lado "muitos" da relação. Nesse caso, por exemplo, você adiciona a coluna ID do Fornecedor da tabela Fornecedores à tabela Produtos. Em seguida, o Access pode usar o número de ID do fornecedor na tabela Produtos para localizar o fornecedor correto para cada produto.
A coluna ID do Fornecedor na tabela Produtos é chamada de chave estrangeira. Uma chave estrangeira é a chave primária de outra tabela. A coluna ID do Fornecedor na tabela Produtos é uma chave estrangeira porque também é a chave primária na tabela Fornecedores.

Você fornece a base para unir tabelas relacionadas estabelecendo emparelhamentos de chaves primárias e chaves estrangeiras. Se você não tiver certeza de quais tabelas devem compartilhar uma coluna comum, identificar uma relação de um para muitos garante que as duas tabelas envolvidas exigirão, de fato, uma coluna compartilhada.
Criando uma relação de muitos para muitos
Considere a relação entre a tabela Produtos e a tabela Pedidos.
Um único pedido pode incluir mais de um produto. Por outro lado, um único produto pode constar em vários pedidos. Assim, para todos os registros da tabela Pedidos, pode haver vários registros na tabela Produtos. E para cada registro na tabela Produtos, pode haver muitos registros na tabela Pedidos. Esse tipo de relação é chamado de uma relação de muitos para muitos porque, para qualquer produto, pode haver muitos pedidos; e para qualquer pedido, pode haver muitos produtos. Observe que, para detectar relações de muitos para muitos entre suas tabelas, é importante que você considere ambos os lados da relação.
Os assuntos das duas tabelas – pedidos e produtos – têm uma relação de muitos para muitos. Isso apresenta um problema. Para entender o problema, imagine o que aconteceria se você tentasse criar a relação entre as duas tabelas adicionando o campo ID do produto à tabela Pedidos. Para ter mais de um produto por pedido, você precisa de mais de um registro na tabela Pedidos por ordem. Você estaria repetindo informações de pedido para cada linha relacionada a uma única ordem , resultando em um design ineficiente que poderia levar a dados imprecisos. Você terá o mesmo problema se colocar o campo ID do pedido na tabela Produtos – você terá mais de um registro na tabela Produtos para cada produto. Como você resolve esse problema?
A resposta é criar uma terceira tabela, muitas vezes chamada de tabela de junção, que divide a relação de muitos para muitos em duas relações de um para muitos. Insira a chave primária de cada uma das duas tabelas na terceira tabela. Como resultado, a terceira tabela registra cada ocorrência ou instância da relação.
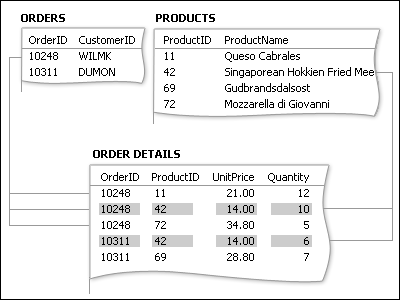
Cada registro na tabela Detalhes do Pedido representa um item de linha em um pedido. A chave primária da tabela Detalhes do Pedido consiste em dois campos: as chaves estrangeiras das tabelas Pedidos e Produtos. Usar o campo ID de pedido sozinho não funciona como a chave primária para esta tabela, pois um pedido pode ter muitos itens de linha. A ID do pedido é repetida para cada item de linha em um pedido, de modo que o campo não contém valores exclusivos. Usar o campo ID do produto sozinho também não funciona, pois um produto pode aparecer em muitos pedidos diferentes. Mas juntos, os dois campos sempre produzem um valor exclusivo para cada registro.
No banco de dados de vendas de produtos, a tabela Pedidos e a tabela Produtos não estão relacionadas entre si diretamente. Em vez disso, eles estão relacionados indiretamente por meio da tabela Detalhes do Pedido. A relação de muitos para muitos entre pedidos e produtos é representada no banco de dados usando duas relações de um para muitos:
-
A tabela Pedidos e a tabela Detalhes do Pedido têm uma relação de um para muitos. Cada pedido pode ter mais de um item de linha, mas cada item de linha está conectado a apenas um pedido.
-
A tabela Produtos e detalhes do pedido têm uma relação de um para muitos. Cada produto pode ter muitos itens de linha associados a ele, mas cada item de linha se refere a apenas um produto.
Na tabela Detalhes do Pedido, você pode determinar todos os produtos em um pedido específico. Você também pode determinar todos os pedidos de um determinado produto.
Depois de incorporar a tabela Detalhes do Pedido, a lista de tabelas e campos pode ser semelhante a esta:

Criando um relacionamento de um-para-um
Outro tipo de relação é a relação um-para-um. Por exemplo, suponha que você precise registrar algumas informações especiais de produto suplementar que você raramente precisará ou que se aplique apenas a alguns produtos. Como você não precisa das informações com frequência e, como armazenar as informações na tabela Produtos resultaria em espaço vazio para cada produto ao qual ela não se aplica, você as coloca em uma tabela separada. Assim como a tabela Produtos, você usa o ProductID como a chave primária. A relação entre essa tabela suplementar e a tabela Product é uma relação de um para um. Para cada registro na tabela Produto, existe um único registro correspondente na tabela suplementar. Quando você identifica esse tipo de relação, ambas as tabelas devem compartilhar um campo em comum.
Ao detectar a necessidade de uma relação um-para-um em seu banco de dados, considere se você pode colocar as informações das duas tabelas juntas em uma tabela. Se você não quiser fazer isso por algum motivo, talvez porque isso resultaria em muito espaço vazio, a lista a seguir mostra como você representaria a relação em seu design:
-
Se as duas tabelas tiverem o mesmo assunto, provavelmente você poderá configurar a relação usando a mesma chave primária em ambas as tabelas.
-
Se as duas tabelas tiverem assuntos diferentes com chaves primárias diferentes, escolha uma das tabelas (uma delas) e insira sua chave primária na outra tabela como uma chave estrangeira.
Determinar as relações entre tabelas ajuda você a garantir que você tenha as tabelas e colunas certas. Quando existe uma relação de um para um ou um para muitos, as tabelas envolvidas precisam compartilhar uma coluna ou coluna comum. Quando existe uma relação de muitos para muitos, uma terceira tabela é necessária para representar a relação.
Refinando o design
Depois de ter as tabelas, campos e relacionamentos necessários, você deve criar e preencher suas tabelas com dados de exemplo e tentar trabalhar com as informações: criar consultas, adicionar novos registros e assim por diante. Fazer isso ajuda a realçar possíveis problemas – por exemplo, talvez seja necessário adicionar uma coluna que você esqueceu de inserir durante a fase de design ou pode ter uma tabela que você deve dividir em duas tabelas para remover a duplicação.
Veja se você pode usar o banco de dados para obter as respostas desejadas. Crie rascunhos brutos de seus formulários e relatórios e veja se eles mostram os dados esperados. Procure duplicação desnecessária de dados e, quando encontrar algum, altere seu design para eliminá-los.
Ao experimentar seu banco de dados inicial, você provavelmente descobrirá espaço para melhorias. Aqui estão algumas coisas para marcar:
-
Esqueceu alguma coluna? Nesse caso, as informações pertencem às tabelas existentes? Se forem informações sobre outra coisa, talvez seja necessário criar outra tabela. Crie uma coluna para cada item de informação que você precisa rastrear. Se as informações não puderem ser calculadas de outras colunas, é provável que você precise de uma nova coluna para ela.
-
Alguma coluna é desnecessária porque pode ser calculada a partir de campos existentes? Se um item de informações puder ser calculado a partir de outras colunas existentes – um preço com desconto calculado a partir do preço de varejo, por exemplo – geralmente é melhor fazer exatamente isso e evitar criar uma nova coluna.
-
Você está inserindo repetidamente informações duplicadas em uma de suas tabelas? Se assim for, você provavelmente precisa dividir a tabela em duas tabelas que têm uma relação de um para muitos.
-
Você tem tabelas com muitos campos, um número limitado de registros e muitos campos vazios em registros individuais? Nesse caso, pense em reprojetar a tabela para que ela tenha menos campos e mais registros.
-
Cada item de informação foi dividido em suas menores partes úteis? Se você precisar relatar, classificar, pesquisar ou calcular em um item de informações, coloque esse item em sua própria coluna.
-
Cada coluna contém um fato sobre o assunto da tabela? Se uma coluna não contiver informações sobre o assunto da tabela, ela pertence a uma tabela diferente.
-
Todas as relações entre tabelas são representadas por campos comuns ou por uma terceira tabela? Relações um para um e um para muitos exigem colunas comuns. Relações de muitos para muitos exigem uma terceira tabela.
Refinando a tabela Produtos
Suponha que cada produto no banco de dados de vendas de produtos esteja em uma categoria geral, como bebidas, condimentos ou frutos do mar. A tabela Produtos pode incluir um campo que mostra a categoria de cada produto.
Suponha que, depois de examinar e refinar o design do banco de dados, você decida armazenar uma descrição da categoria junto com seu nome. Se você adicionar um campo Descrição de Categoria à tabela Produtos, deverá repetir cada descrição de categoria para cada produto que se enquadra na categoria – essa não é uma boa solução.
Uma solução melhor é tornar Categorias um novo assunto para o banco de dados acompanhar, com sua própria tabela e sua própria chave primária. Em seguida, você pode adicionar a chave primária da tabela Categorias à tabela Produtos como uma chave estrangeira.
As tabelas Categorias e Produtos têm uma relação de um para muitos: uma categoria pode incluir mais de um produto, mas um produto pode pertencer a apenas uma categoria.
Ao examinar suas estruturas de tabela, fique atento a grupos repetidos. Por exemplo, considere uma tabela que contém as seguintes colunas:
-
ID do Produto
-
Nome
-
ID1 do produto
-
Name1
-
ID2 do produto
-
Name2
-
ID3 do produto
-
Name3
Aqui, cada produto é um grupo repetido de colunas que difere das outras apenas adicionando um número ao final do nome da coluna. Quando você vir colunas numeradas dessa forma, você deve revisitar seu design.
Esse design tem várias falhas. Para começar, isso força você a colocar um limite superior no número de produtos. Assim que exceder esse limite, você deve adicionar um novo grupo de colunas à estrutura da tabela, que é uma tarefa administrativa importante.
Outro problema é que os fornecedores que têm menos do que o número máximo de produtos desperdiçarão algum espaço, já que as colunas adicionais ficarão em branco. A falha mais grave com esse design é que torna muitas tarefas difíceis de executar, como classificar ou indexar a tabela por ID ou nome do produto.
Sempre que você vir grupos repetidos, examine o design de perto de olho na divisão da tabela em dois. No exemplo acima, é melhor usar duas tabelas, uma para fornecedores e outra para produtos, vinculadas pela ID do fornecedor.
Aplicando as regras de normalização
Você pode aplicar as regras de normalização de dados (às vezes chamadas apenas de regras de normalização) como a próxima etapa em seu design. Use essas regras para ver se as tabelas estão estruturadas corretamente. O processo de aplicação das regras ao design do banco de dados é chamado de normalização do banco de dados ou apenas normalização.
A normalização é mais útil depois que você representa todos os itens de informação e chega a um design preliminar. A ideia é ajudá-lo a garantir que você tenha dividido seus itens de informações nas tabelas apropriadas. O que a normalização não pode fazer é garantir que você tenha todos os itens de dados corretos para começar.
Você aplica as regras em sucessão, em cada etapa, garantindo que seu design chegue a um dos "formulários normais". Cinco formulários normais são amplamente aceitos – o primeiro formulário normal até o quinto formulário normal. Este artigo se expande nos três primeiros, porque eles são tudo o que é necessário para a maioria dos designs de banco de dados.
Primeiro formulário normal
O primeiro formulário normal afirma que em cada interseção de linha e coluna na tabela, existe um único valor e nunca uma lista de valores. Por exemplo, você não pode ter um campo chamado Price no qual você coloca mais de um Preço. Se você pensar em cada interseção de linhas e colunas como uma célula, cada célula poderá conter apenas um valor.
Segundo formulário normal
O segundo formulário normal exige que cada coluna não-chave seja totalmente dependente de toda a chave primária, não apenas de parte da chave. Essa regra se aplica quando você tem uma chave primária que consiste em mais de uma coluna. Por exemplo, suponha que você tenha uma tabela que contém as seguintes colunas, em que iD do pedido e ID do produto formam a chave primária:
-
ID do pedido (chave primária)
-
ID do produto (chave primária)
-
Nome do Produto
Esse design viola o segundo formulário normal, pois o Nome do Produto depende da ID do produto, mas não da ID do pedido, portanto, não depende de toda a chave primária. Você deve remover o Nome do Produto da tabela. Ele pertence a uma tabela diferente (Produtos).
Terceira forma normal
O terceiro formulário normal exige que não apenas todas as colunas não-chave dependam de toda a chave primária, mas que as colunas não-chave sejam independentes umas das outras.
Outra maneira de dizer isso é que cada coluna não-chave deve depender da chave primária e nada além da chave primária. Por exemplo, suponha que você tenha uma tabela contendo as seguintes colunas:
-
ProductID (chave primária)
-
Nome
-
SRP
-
Desconto
Suponha que o Desconto dependa do preço de varejo sugerido (SRP). Essa tabela viola o terceiro formulário normal porque uma coluna não-chave, Discount, depende de outra coluna não-chave, SRP. A independência da coluna significa que você deve ser capaz de alterar qualquer coluna não-chave sem afetar nenhuma outra coluna. Se você alterar um valor no campo SRP, o Desconto será alterado de acordo, violando essa regra. Nesse caso, o Desconto deve ser movido para outra tabela que é chaveada no SRP.









