
Este artigo descreve a sintaxe da fórmula e o uso da função PROJ.LIN no Microsoft Excel. Encontre links para informações adicionais sobre como criar gráficos e realizar uma análise de regressão na seção Veja também.
Descrição
A função PROJ.LIN calcula as estatísticas para uma linha usando o método "quadrados mínimos" para calcular uma linha reta que melhor se ajusta aos seus dados e retorna uma matriz que descreve essa linha. Você também pode combinar a função PROJ.LIN com outras funções para calcular as estatísticas de outros tipos de modelos que são lineares nos parâmetros desconhecidos, incluindo séries polinomiais, logarítmicas, exponenciais e de potência. Como essa função retorna uma matriz de valores, ela deve ser inserida como uma fórmula de matriz. Instruções acompanham os exemplos neste artigo.
A equação para a linha é:
y = mx + b
–ou–
y = m1x1 + m2x2 + ... + b
se existirem vários intervalos de valores x, em que os valores y dependentes são uma função dos valores x independentes. Os valores m são coeficientes que correspondem a cada valor x e b é um valor constante. Observe que y, x e m podem ser vetores. A matriz retornada pela função PROJ.LIN é {mn,mn-1,...,m1,b}. PROJ.LIN também pode retornar estatísticas de regressão adicionais.
Sintaxe
PROJ.LIN(val_conhecidos_y, [val_conhecidos_x], [constante], [estatísticas])
A sintaxe da função PROJ.LIN tem os seguintes argumentos:
Sintaxe
-
val_conhecidos_y Necessário. O conjunto de valores y que você já conhece na relação y = mx + b.
-
Se o intervalo de val_conhecidos_y estiver em uma única coluna, cada coluna de val_conhecidos_x será interpretada como uma variável separada.
-
Se o intervalo de val_conhecidos_y estiver contido em uma única linha, cada linha de val_conhecidos_x será interpretada como uma variável separada.
-
-
val_conhecidos_x Opcional. Um conjunto opcional de valores x que talvez você já conheça na relação y = mx + b.
-
O intervalo de val_conhecidos_x pode incluir um ou mais conjuntos de variáveis. Se apenas uma variável for usada, val_conhecidos_y e val_conhecidos_x poderão ser intervalos de qualquer forma, desde que tenham dimensões iguais. Se mais de uma variável for usada, val_conhecidos_y deverá ser um vetor (ou seja, um intervalo com altura de uma linha ou largura de uma coluna).
-
Se val_conhecidos_x for omitido, pressupõe-se que ele seja a matriz {1,2,3,...} com o mesmo tamanho que val_conhecidos_y.
-
-
constante Opcional. Um valor lógico que especifica se a constante b será ou não forçada a se igualar a 0.
-
Se constante for VERDADEIRO ou for omitido, b será calculado normalmente.
-
Se constante for FALSO, b será definido como igual a 0 e os valores m serão ajustados para se adaptarem a y = mx.
-
-
estatísticas Opcional. O valor lógico que especifica se estatísticas de regressão adicionais serão retornadas.
-
Se estatísticas for VERDADEIRO, PROJ.LIN retornará as estatísticas de regressão adicionais; como resultado, a matriz retornada será {mn,mn-1,...,m1,b;sen,sen-1,...,se1,seb;r2,sey; F,df;ssreg,ssresid}.
-
Se estatísticas for FALSO ou estiver omitido, PROJ.LIN retornará somente os coeficientes m e a constante b.
Os dados estatísticos de regressão adicionais são:
-
|
Dados estatísticos |
Descrição |
|---|---|
|
se1.se2.....sem |
Os valores de erro padrão para os coeficientes m1.m2.....mn. |
|
seb |
O valor de erro padrão para a constante b (seb = #N/D quando constante é FALSO). |
|
r2 |
O coeficiente de determinação. Compara os valores y estimados e reais e os intervalos no valor de 0 a 1. Se for 1, existe uma correlação perfeita no exemplo — não há diferença entre o valor y estimado e o valor y real. No outro extremo, se o coeficiente de determinação for 0, a equação de regressão não será útil na previsão de um valor y. Para obter informações sobre como2 é calculada, consulte "Comentários", mais adiante neste tópico. |
|
Sey |
O valor de erro para a estimativa de y. |
|
S |
A estatística F, ou o valor de F observado. Use a estatística F para determinar se a relação observada entre as variáveis dependentes e independentes ocorre por acaso. |
|
Df |
Os graus de liberdade. Use os graus de liberdade para ajudar a encontrar os valores F críticos em uma tabela estatística. Compare os valores encontrados na tabela com a estatística F retornada por PROJ.LIN de modo a determinar um nível de confiança para o modelo. Para obter informações sobre como df é calculado, consulte "Comentários", mais adiante neste tópico. O Exemplo 4 mostra o uso de F e df. |
|
Ssreg |
A soma dos quadrados da regressão. |
|
Ssresid |
A soma residual dos quadrados. Para obter informações sobre como ssreg e ssresid são calculados, consulte "Comentários" mais adiante neste tópico. |
A ilustração a seguir mostra a ordem em que os dados estatísticos adicionais são fornecidos.

Comentários
-
Você pode descrever qualquer linha reta com a inclinação e o ponto de origem y:
Inclinação (m):
Para calcular a inclinação de uma linha, frequentemente representada por m, use dois pontos da linha, (x1,y1) e (x2,y2); a inclinação será igual a (y2 - y1)/(x2 - x1).Interceptação de y (b):
O intercepto de y de uma linha, frequentemente representado por b, é o valor de y no ponto em que a linha cruza o eixo y.A equação de uma linha reta é y = mx + b. Uma vez fornecidos os valores de m e de b, você pode calcular qualquer ponto na linha inserindo o valor de y ou de x nessa equação. Você também pode usar a função TENDÊNCIA.
-
Quando você tiver apenas uma variável de x independente, poderá obter os valores de inclinação e de intercepto de y diretamente, usando as fórmulas a seguir:
Inclinação:
=ÍNDICE(PROJ.LIN(val_conhecidos_y;val_conhecidos_x);1)Interceptação y:
=ÍNDICE(PROJ.LIN(val_conhecidos_y;val_conhecidos_x);2) -
A precisão da linha calculada pela função PROJ.LIN dependerá do grau de dispersão dos seus dados. Quanto mais lineares forem os dados, mais preciso será o modelo de PROJ.LIN. PROJ.LIN usa o método dos mínimos quadrados para determinar o ajuste perfeito aos seus dados. Quando você tiver apenas uma variável independente, os cálculos para m e b serão baseados nas fórmulas a seguir:
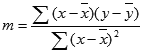
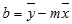
em que x e y são exemplos de média, ou seja, x = MÉDIA(val_conhecidos_x) e y = MÉDIA(val_conhecidos_y).
-
As funções de ajuste de linha e curva PROJ.LIN e PROJ.LOG podem calcular a melhor linha reta ou curva exponencial que se ajusta aos seus dados. Entretanto, você precisa decidir qual dos dois resultados se ajusta melhor aos seus dados. Você pode calcular o TREND(known_y's,known_x's) para uma linha reta ou GROWTH(known_y's, known_x's) a uma curva exponencial. Essas funções, sem o new_x do, retornam uma matriz de valores y previstos ao longo dessa linha ou curva nos seus pontos de dados reais. Em seguida, você pode comparar os valores previstos com os valores reais. Talvez você queira catálogo em destaque para comparação visual.
-
Na análise de regressão, o Excel calcula a diferença de quadrados entre o valor y estimado e o valor y real para cada ponto. A soma dessas diferenças de quadrados é chamada de soma dos quadrados de resíduo, ssresid. O Excel calcula então a soma total dos quadrados. Quando o argumento constante for VERDADEIRO ou for omitido, a soma total dos quadrados será a soma das diferenças dos quadrados entre os valores y reais e a média dos valores y. Quando o argumento constante for FALSO, a soma total dos quadrados será a soma de quadrados dos próprios valores de y (sem subtrair a média dos valores de y de cada valor de y individual). A soma da regressão dos quadrados, ssreg, pode ser obtida de: ssreg = sstotal - ssresid. Quanto menor for a soma residual de quadrados, em comparação com a soma total de quadrados, maior será o valor do coeficiente de determinação, r2, que é um indicador de quão bem a equação resultante da análise de regressão explica a relação entre as variáveis. O valor de r2 igual a ssreg/sstotal.
-
Em alguns casos, uma ou mais colunas de X (supondo que os Ys e Xs estejam em colunas) podem não ter nenhum valor previsível adicional na presença das outras colunas de X. Em outras palavras, se forem eliminadas uma ou mais colunas de X, poderemos chegar a valores previsíveis de Y com a mesma precisão. Nesse caso, as colunas de X redundantes devem ser omitidas do modelo de regressão. Esse fenômeno é chamado de “colinearidade” porque qualquer coluna de X redundante pode ser expressa como uma soma dos múltiplos das colunas de X não redundantes. A função PROJ.LIN verifica a colinearidade e remove as colunas de X redundantes do modelo de regressão quando as identifica. As colunas de X removidas podem ser reconhecidas no resultado de PROJ.LIN como tendo 0 coeficiente além de valores 0 se. Se uma ou mais colunas forem removidas como redundantes, df será afetada porque depende do número de colunas de X realmente usadas para fins previsíveis. Para obter mais detalhes sobre o cálculo de df, consulte o Exemplo 4. Se df for alterada porque as colunas de X redundantes foram removidas, os valores de sey e F também serão afetados. Na prática, a colinearidade é relativamente rara. Contudo, um caso em que sua ocorrência será mais provável é quando algumas colunas de X contiverem somente valores 0 e 1 indicando se um dado é um experimento ou se não faz parte de um determinado grupo. Se constante for VERDADEIRO ou se for omitido, a função PROJ.LIN irá inserir uma coluna de X adicional de valores 1 para modelar a interceptação. Se você tiver uma coluna com um 1 para cada dado se masculino, ou 0 se não for, você também terá uma coluna com um 1 para cada dado se for feminino e 0 se não for. Essa segunda coluna será redundante porque suas informações poderão ser obtidas pela subtração da entrada da coluna “indicador de masculino” da entrada da coluna adicional de valores 1 adicionada pela função PROJ.LIN.
-
O valor de df é calculado da seguinte maneira, quando nenhuma coluna de X é removida do modelo devido à colinearidade: se houver k colunas de val_conhecidos_x e constante for VERDADEIRO ou estiver omitido, então df = n – k – 1. Se constante for FALSO, então df = n - k. Em ambos os casos, cada coluna de X removida devido à colinearidade aumentará df em 1.
-
Ao inserir a constante de uma matriz (como val_conhecidos_x) como um argumento, use vírgulas para separar valores contidos na mesma linha e pontos-e-vírgulas para separar linhas. Os caracteres de separadores poderão ser diferentes dependendo de suas configurações regionais.
-
Você deve observar que os valores de y estimados pela equação de regressão podem não ser válidos se estiverem fora do intervalo de valores de y usado para determinar a equação.
-
O algoritmo subjacente usado na função PROJ.LIN é diferente do algoritmo subjacente usado nas funções INTERCEPÇÃO e INCLINAÇÃO. A diferença entre esses algoritmos pode levar a diferentes resultados quando os dados forem indeterminados e colineares. Por exemplo, se os pontos de dados do argumento val_conhecidos_y forem 0 e os pontos de dados do argumento val_conhecidos_x forem 1:
-
PROJ.LIN retornará um valor de 0. O algoritmo da função PROJ.LIN foi desenvolvido para retornar resultados razoáveis para dados colineares e, nesse caso, pelo menos uma resposta será encontrada.
-
INCLINAÇÃO e INTERCEPÇÃO retornam um #DIV/0! #REF!. O algoritmo das funções INCLINAÇÃO e INTERCEPÇÃO foi desenvolvido para procurar somente uma resposta e, nesse caso, pode haver mais de uma resposta.
-
-
Além de usar PROJ.LOG para calcular estatísticas para outros tipos de regressão, você pode usar PROJ.LIN para calcular um intervalo de outros tipos de regressão inserindo funções de variáveis x e y como séries x e y de PROJ.LIN. Por exemplo, a fórmula a seguir:
=PROJ.LIN(valores y, valores x^COLUNA($A:$C))
funciona quando você tem uma única coluna de valores y e uma única coluna de valores x para calcular a aproximação cúbica (polinomial de ordem 3) do formato:
y = m1*x + m2*x^2 + m3*x^3 + b
Você pode ajustar essa fórmula para calcular outros tipos de regressão, mas em alguns casos é necessário o ajuste dos valores de saída e outras estatísticas.
-
O valor do teste F que é retornado pela função PROJ.LIN é diferente do valor do teste F retornado pela função TESTEF. PROJ.LIN retorna a estatística F, enquanto TESTEF retorna a probabilidade.
Exemplos
Exemplo 1 - Inclinação e Intercepção de Y
Copie os dados de exemplo da tabela a seguir e cole-os na célula A1 de uma nova planilha do Excel. Para as fórmulas mostrarem resultados, selecione-as, pressione F2 e pressione Enter. Se precisar, você poderá ajustar as larguras das colunas para ver todos os dados.
|
y conhecido |
x conhecido |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Resultado (declive) |
Resultado (interceptação y) |
|
2 |
1 |
|
Fórmula (fórmula de matriz nas células A7:B7) |
|
|
=PROJ.LIN(A2:A5;B2:B5;FALSO) |
Exemplo 2 - Regressão Linear Simples
Copie os dados de exemplo da tabela a seguir e cole-os na célula A1 de uma nova planilha do Excel. Para as fórmulas mostrarem resultados, selecione-as, pressione F2 e pressione Enter. Se precisar, você poderá ajustar as larguras das colunas para ver todos os dados.
|
Mês |
Vendas |
|---|---|
|
1 |
$3.100 |
|
2 |
$4.500 |
|
3 |
$4.400 |
|
4 |
$5.400 |
|
5 |
$7.500 |
|
6 |
$8.100 |
|
Fórmula |
Resultado |
|
=SOMA(PROJ.LIN(B1:B6, A1:A6)*{9,1}) |
$11.000 |
|
Calcula a estimativa das vendas no nono mês, com base nas vendas dos meses de 1 a 6. |
Exemplo 3 - Regressão Linear Múltipla
Copie os dados de exemplo da tabela a seguir e cole-os na célula A1 de uma nova planilha do Excel. Para as fórmulas mostrarem resultados, selecione-as, pressione F2 e pressione Enter. Se precisar, você poderá ajustar as larguras das colunas para ver todos os dados.
|
Área útil (x1) |
Salas (x2) |
Entradas (x3) |
Idade (x4) |
Valor estimado (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
$142.000 |
|
2333 |
2 |
2 |
12 |
$144.000 |
|
2356 |
3 |
1,5 |
33 |
$151.000 |
|
2379 |
3 |
2 |
43 |
$150.000 |
|
2402 |
2 |
3 |
53 |
$139.000 |
|
2425 |
4 |
2 |
23 |
$169.000 |
|
2448 |
2 |
1,5 |
99 |
$126.000 |
|
2471 |
2 |
2 |
34 |
$142.900 |
|
2494 |
3 |
3 |
23 |
$163.000 |
|
2517 |
4 |
4 |
55 |
$169.000 |
|
2540 |
2 |
3 |
22 |
$149.000 |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Fórmula (fórmula de matriz dinâmica inserida em A19) |
||||
|
=PROJ.LIN(E2:E12;A2:D12;VERDADEIRO;VERDADEIRO) |
Exemplo 4 – Usando as Estatísticas F e r2
No exemplo anterior, o coeficiente de determinação, ou r2, é 0,99675 (consulte a célula A17 na saída para PROJ.LIN), que indicaria uma relação forte entre as variáveis independentes e o preço de venda. Você pode usar a estatística F para determinar se esses resultados, com um valor de r2 tão alto, ocorreram por acaso.
Suponha, por agora, que na verdade não há relação entre as variáveis, mas que você selecionou uma amostra rara de 11 prédios que fará com que a análise estatística demonstre uma forte relação. O termo "Alfa" é usado para indicar a probabilidade de se concluir erroneamente que existe uma relação.
Os valores F e df no resultado da função PROJ.LIN podem ser usados para avaliar a probabilidade de ocorrer um valor mais alto de F por acaso. F pode ser comparado a valores críticos em tabelas de distribuição de F publicadas ou a função DISTF no Excel pode ser usada para calcular a probabilidade de ocorrer um valor de F maior por acaso. A distribuição apropriada de F possui graus v1 e v2 de liberdade. Se n for o número de pontos de dados e constante for VERDADEIRO ou estiver omitido, então v1 = n – df – 1 e v2 = df. (Se constante for FALSO, então v1 = n – df e v2 = df). A função DISTF — com a sintaxe DISTF(F,v1,v2) — retornará a probabilidade de um valor mais alto de F ocorrer por acaso. Nesse exemplo, df = 6 (célula B18) e F = 459,753674 (célula A18).
Supondo um valor Alfa de 0,05, v1 = 11 – 6 – 1 = 4 e v2 = 6, o nível crítico de F é 4,53. Como F = 459,753674 é muito maior que 4,53, é extremamente improvável que um valor F tão alto tenha ocorrido por acaso. (Com Alfa = 0,05, a hipótese de que não há relação entre known_y’s e known_x’s deve ser rejeitada quando F exceder o nível crítico, 4,53.) Você pode usar a função FDIST no Excel para obter a probabilidade de que um valor F alto tenha ocorrido por acaso. Por exemplo, FDIST(459,753674, 4, 6) = 1,37E-7, uma probabilidade extremamente pequena. Você pode concluir, localizando o nível crítico de F em uma tabela ou usando a função FDIST, que a equação de regressão é útil para prever o valor avaliado dos edifícios de escritório nessa área. Lembre-se de que é fundamental usar os valores corretos de v1 e v2 que foram computados no parágrafo anterior.
Calculando as estatísticas de t
Outro teste hipotético pode determinar se um coeficiente de inclinação é útil para prever o valor estimado de um prédio no Exemplo 3. Por exemplo, para testar o coeficiente de idade para significância estatística, divida -234,24 (coeficiente de idade da inclinação) por 13,268 (o valor de erro estimado para os coeficientes de idade na célula A15). A equação a seguir representa o valor de t observado:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Se o valor absoluto de t for suficientemente alto, poderemos concluir que o eficiente da curva é útil na estimativa do valor avaliado de um prédio comercial no Exemplo 3. A tabela a seguir mostra os valores absolutos dos 4 valores observados de t.
Se você consultar uma tabela em um manual de estatística, você descobrirá que o valor t crítico e bicaudal com 6 graus de liberdade e Alfa = 0,05 é 2,447. Este valor crítico também pode ser obtido por meio da função INVT no Excel. INVT(0.05,6) = 2.447. Na medida em que o valor t absoluto (17,7) é maior que 2,447, a idade será uma variável importante para prever o valor estimado de um prédio. Cada uma das outras variáveis independentes pode ser testada para valor estatístico de maneira semelhante. Na tabela a seguir, encontram-se os valores t observados para cada variável independente:
|
Variável |
valor de t observado |
|---|---|
|
Área útil |
5,1 |
|
Número de salas |
31,3 |
|
Número de entradas |
4,8 |
|
Idade |
17,7 |
Todos esses valores apresentam um valor absoluto maior que 2,447; dessa forma, todas as variáveis usadas na equação de regressão serão úteis para prever o valor estimado dos prédios dessa área.









