
Após migrar os seus dados do Access para o SQL Server, terá uma base de dados de cliente/servidor, que pode ser uma solução no local ou de nuvem híbrida do Azure. De qualquer forma, o Access passará a ser a camada de apresentação e o SQL Server a camada de dados. Este é o momento indicado para repensar os aspectos da sua solução, principalmente no que toca ao desempenho de consultas, segurança e continuidade do negócio, para que possa melhorar e dimensionar a sua solução de base de dados.
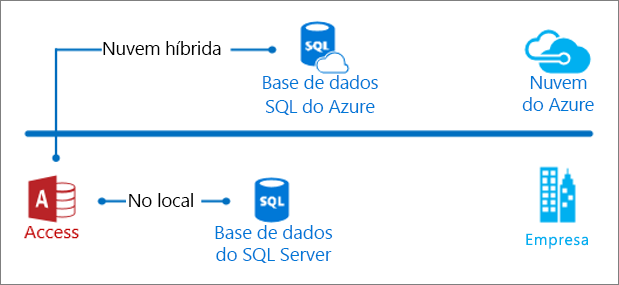
Esta tarefa pode revelar-se intimidante para um utilizador do Access que tome contacto pela primeira vez com a documentação do SQL Server e do Azure. Por este motivo, é indispensável realizar uma apresentação que realce os aspetos que são importantes para si. Após concluir esta apresentação, estará em condições de explorar os avanços em tecnologia da base de dados e a prosseguir o seu caminho.
Neste Artigo
|
Gestão de Bases de Dados Promover a continuidade do negócio Lidar com questões sobre privacidade |
Consultas e aspetos relacionados |
Tipos de Dados |
Diversos |
Promover a continuidade do negócio
No caso da sua solução do Access, pretende mantê-la operacional com um mínimo de interrupções, mas as suas opções disponíveis numa base de dados back-end do Access são limitadas. Criar cópias de segurança da sua base de dados do Access é essencial para proteger os seus dados, mas exige que os seus utilizadores estejam offline. Além disso, podem ocorrer tempos de inatividade não planeados causados por atualizações de manutenção de hardware/software, falhas de rede ou de energia, falhas de hardware, falhas de segurança ou mesmo ciberataques. Para minimizar o tempo de inatividade e o impacto na sua empresa, pode criar uma cópia de segurança de uma base de dados do SQL Server enquanto esta estiver em utilização. Além disso, o SQL Server também oferece estratégias de elevada disponibilidade (HA) e de recuperação após desastres (DR). Estas duas tecnologias combinadas são conhecidas pela sigla inglesa "HADR". Para mais informações, consulte Continuidade do negócio e recuperação de bases de dados e Promover a continuidade do negócio com o SQL Server (e-book).
Criar cópias de segurança durante a utilização
O SQL Server utiliza um processo de cópia de segurança online que pode ocorrer enquanto a base de dados estiver em execução. Pode efetuar uma cópia de segurança completa, uma cópia de segurança parcial ou uma cópia de segurança de ficheiros. Uma cópia de segurança copia registos de dados e de transações para garantir uma operação de restauro completa. Especialmente no caso de uma solução no local, tenha em atenção as diferença entre as opções de recuperação simples e total e como estas afetam o crescimento do registo de transações. Para obter mais informações, consulte Modelos de Recuperação.
A maioria das operações de cópia de segurança ocorre de imediato, exceto as operações de gestão de ficheiros e de redução de bases de dados. Por outro lado, se tentar criar ou eliminar um ficheiro de base de dados enquanto uma operação de cópia de segurança estiver em curso, a operação irá falhar. Para obter mais informações, consulte Descrição Geral das Cópias de Segurança
HADR
As duas técnicas mais comuns para conseguir elevada disponibilidade e a continuidade do negócio são o espelhamento e o clustering. O SQL Server integra tecnologia de espelhamento e de clustering com a opção "Instâncias do Cluster de Ativação Pós-falha AlwaysOn" e "Grupos de Disponibilidade AlwaysOn".
O espelhamento é uma solução de continuidade ao nível da base de dados que suporta o mecanismo de pós-falha quase instantâneo ao manter uma base de dados em modo de espera, ou seja, uma cópia completa ou um espelho da base de dados ativa em hardware separado. Pode trabalhar num modo síncrono (de alta segurança), em que uma transação de entrada é efetuada em todos os servidores ao mesmo tempo ou num modo assíncrono (de alto desempenho), em que uma transação de entrada é efetuada na base de dados ativa e posteriormente copiada para o espelho num dado momento predeterminado. O espelhamento é uma solução ao nível da base de dados e só funciona com bases de dados que utilizem o modelo de recuperação completa.
O clustering é uma solução ao nível do servidor que combina servidores num único armazenamento de dados e que tem o aspeto de uma única instância aos olhos do utilizador. Os utilizadores ligam-se à instância e nunca precisam de saber qual dos servidores na instância está atualmente ativo. Caso ocorra uma falha no servidor ou seja necessário colocá-lo offline para manutenção, a experiência do utilizador não se altera. Cada servidor no cluster é monitorizado pelo gestor de clusters através de um mecanismo de heartbeat, pelo que irá detetar quando um servidor ativo no cluster está offline e tentará mudar para o servidor seguinte no cluster de forma ininterrupta, embora exista um atraso temporal variável durante a mudança.
Para obter mais informações, consulte Instâncias do Cluster de Ativação Pós-falha Always On e Grupos de Disponibilidade Always On: uma solução de alta disponibilidade e de recuperação de desastres.
Segurança do SQL Server
Apesar de poder proteger a sua base de dados do Access ao utilizar o Centro de Confiança e ao encriptar a base de dados, o SQL Server tem funcionalidades de segurança mais avançadas. Vamos analisar três funcionalidades que se destacam para os utilizadores do Access. Para mais informações, consulte Proteger o SQL Server.
Autenticação de bases de dados
Existem quatro métodos de autenticação de bases de dados no SQL Server que pode especificar numa cadeira de ligação ODBC. Para mais informações, consulte Ligar ou importar dados de uma Base de Dados Azure SQL Server. Cada método tem as suas próprias vantagens.
Autenticação Integrada do Windows Utilize as credenciais do Windows para a validação dos utilizadores, funções de segurança e limitação de utilizadores a funcionalidades e dados. Pode tirar partido das credenciais de domínio e gerir facilmente os direitos dos utilizadores na sua aplicação. Em alternativa, introduza os Nomes dos Principais do Serviço (SPNs). Para obter mais informações, consulte Escolher um Modo de Autenticação.
Autenticação do SQL Server Os utilizadores precisam de se ligar com as credenciais que foram configuradas na base de dados ao introduzirem o ID de início de sessão e a palavra-passe na primeira vez que acederem à base de dados numa sessão. Para obter mais informações, consulte Escolher um Modo de Autenticação.
Autenticação Integrada do Azure Active Directory Ligue-se à Base de Dados do Azure SQL Server ao utilizar o Azure Active Directory. Assim que tiver configurado a autenticação do Azure Active Directory, não é preciso início de sessão e palavra-passe adicional. Para obter mais informações, consulte Connecting to SQL Database by Using Azure Active Directory Authentication (Ligar a Uma Base de Dados SQL Através da Autenticação do Azure Active Directory).
Autenticação por Palavra-passe do Active Directory Ligue-se com as credenciais que foram configuradas no Azure Active Directory ao introduzir o nome de início de sessão e palavra-passe. Para obter mais informações, consulte Connecting to SQL Database by Using Azure Active Directory Authentication (Ligar a Uma Base de Dados SQL Através da Autenticação do Azure Active Directory).
Sugestão Utilize a Deteção de Ameaças para receber alertas sobre atividade anómala na base de dados que indique possíveis ameaças de segurança a uma base de dados do Azure SQL Server. Para mais informações, consulte Deteção de Ameaças numa Base de Dados SQL.
Segurança da aplicação
O SQL Server tem duas funcionalidades de segurança ao nível da aplicação das quais pode tirar partido do Access.
Máscara de Dados Dinâmicos Oculte dados confidenciais ao mascará-los de utilizadores não privilegiados. Por exemplo, pode mascarar parcial ou totalmente números da Segurança Social.
 Uma máscara de dados parcial |
 Uma máscara de dados completa |
Existem várias formas de definir uma máscara de dados e pode aplicá-las a diferentes tipos de dados. A máscara de dados é regulada por políticas ao nível da tabela e da coluna para um conjunto definido de utilizadores e é aplicada em tempo real às consultas. Para mais informações, consulte Máscara de Dados Dinâmicos.
Segurança ao Nível da Linha Pode controlar o acesso a linhas específicas de uma base de dados que contenham dados confidenciais, com base nas características dos utilizadores, ao usar a Segurança ao Nível da Linha. O sistema de base de dados aplica estas restrições de acesso e torna o sistema de segurança mais fiável e robusto.

Existem dois tipos de predicados de segurança:
-
Um predicado de filtro que filtra as linhas de uma consulta. O filtro é transparente e o utilizador final não se apercebe da presença de qualquer filtro.
-
Um predicado de bloqueio impede ações não autorizadas e aciona uma exceção se não for possível efetuar a ação.
Para mais informações, consulte Segurança ao nível da linha.
Proteger Dados com Encriptação
Salvaguarde dados em repouso, em trânsito e em utilização sem afetar o desempenho da base de dados. Para obter mais informações, consulte Encriptação do SQL Server.
Encriptação em repouso Para proteger dados pessoais contra ataques offline na camada de armazenamento físico, utilize encriptação em repouso, também denominada Encriptação de Dados Transparente (TDE). Isto significa que os seus dados estão protegidos mesmo que o suporte físico seja roubado ou eliminado de forma incorreta. A TDE executa encriptação e desencriptação de bases de dados, cópias de segurança e registos de transações em tempo real sem precisar de alterar as suas aplicações.
Encriptação em trânsito Para se proteger contra a monitorização dos dados e ataques man-in-the-middle, pode encriptar os dados transmitidos pela rede. O SQL Server suporta Transport Layer Security (TLS) 1.2 para comunicações altamente seguras. O protocolo TDS (Tabular Data Stream) também é utilizado para proteger comunicações através de redes não fidedignas.
Encriptação para dados em utilização no cliente Para proteger dados pessoais enquanto estiverem em utilização, “Always Encrypted” é a funcionalidade certa. Os dados pessoais são encriptados e desencriptados por um controlador no computador cliente sem revelar as chaves de encriptação ao motor de base de dados. Como resultado, os dados encriptados só ficam visíveis para as pessoas responsáveis pela gestão desses dados e não para outros utilizadores com privilégios bastante elevados que não devam ter acesso. Dependendo do tipo de encriptação selecionado, a funcionalidade Always Encrypted pode limitar algumas funcionalidades da base de dados, como procurar, agrupar e indexar colunas encriptadas.
Lidar com questões sobre privacidade
As questões de privacidade são tão abrangentes que a União Europeia definiu requisitos legais através do Regulamento Geral Sobre a Proteção de Dados (RGPD). Felizmente, um SQL Server no back-end é bastante adequado para responder a estes requisitos. A implementação do RGPD deve ser pensada numa estrutura de três passos.

Passo 1: Avaliar e gerir os riscos de conformidade
O RGPD exige que identifique e faça o levantamento das informações pessoais que tem em tabelas e ficheiros. Esta informação pode ser qualquer coisa, desde um nome, fotografia, endereço de e-mail, dados bancários, publicações em sites de redes sociais, informações médicas ou até mesmo um endereço IP.
Uma nova ferramenta de Detecção e Classificação de Dados SQL, incorporada no SQL Server Management Studio, ajuda-o a descobrir, classificar, etiquetar e obter relatórios sobre dados confidenciais ao aplicar dois atributos de metadados às colunas:
-
Etiquetas Para definir a confidencialidade dos dados.
-
Tipos de informação Para fornecer um nível de granularidade adicional sobre os tipos de dados armazenados numa coluna.
Outro mecanismo de descoberta que pode utilizar é a pesquisa de texto completo, que inclui a utilização dos predicados CONTAINS e FREETEXT e funções com valor de conjunto de linhas como CONTAINSTABLE e FREETEXTTABLE para utilizar com a instrução SELECT. Com a pesquisa de texto completo, pode pesquisar tabelas para descobrir palavras, combinações de palavras ou variações de uma palavra, como sinónimos ou formas flexionadas. Para obter mais informações, consulte Pesquisa de Texto Completo.
Passo 2: Proteger informações pessoais
O RGPD exige que proteja as suas informações pessoais e limite o acesso às mesmas. Além dos passos padrão que deverá seguir para gerir o acesso à sua rede e recursos, como as definições de firewall, pode utilizar as funcionalidades de segurança do SQL Server para o ajudar a controlar o acesso aos dados:
-
Autenticação do SQL Server para gerir a identidade do utilizador e impedir o acesso não autorizado.
-
Segurança ao Nível da Linha para limitar o acesso a linhas numa tabela com base na relação entre o utilizador e esses dados.
-
Máscara de Dados Dinâmicos para limitar a exposição a dados pessoais ao mascará-los de utilizadores não privilegiados.
-
Encriptação para garantir que os dados pessoais estão protegidos durante a transmissão e armazenamento e contra acesso indevido, incluindo do lado do servidor.
Para mais informações, consulte Segurança do SQL Server
Passo 3: Responder de forma eficiente a pedidos
O RGPD exige que mantenha os registos de processamento de dados pessoais e os disponibilize às autoridades de supervisão, sempre que solicitado. Caso ocorram problemas como a publicação acidental de dados, os controlos de proteção permitem-lhe responder rapidamente. Os dados têm de estar disponíveis rapidamente quando for necessário efetuar uma comunicação. Por exemplo, o RGPD exige que uma violação de dados pessoais seja comunicada à autoridade de supervisão “num prazo não superior a 72 horas após tomar conhecimento da mesma”.
O SQL Server 2017 ajuda-o com as tarefas de comunicação de várias formas:
-
Auditoria do SQL Server ajuda-o a garantir a existência de registos persistentes de acesso à base de dados e de atividades de processamento. É executada uma auditoria minuciosa que monitoriza as atividades da base de dados para o ajudar a compreender e a identificar possíveis ameaças, suspeitas de abuso ou violações de segurança. Pode executar facilmente atividades periciais nos seus dados.
-
As tabelas temporais do SQL Server são tabelas de utilizador com uma versão de sistema, concebidas para manter um histórico completo de alterações de dados. Pode utilizar estes dados para criar facilmente relatórios e análises num momento específico.
-
Avaliação de Vulnerabilidade do SQL ajuda-o a detectar problemas relacionados com segurança e permissões. Sempre que for detetado um problema, também pode efetuar desagregações em relatórios de análise de base de dados para localizar ações para a resolução.
Para mais informações, consulte Criar uma plataforma de segurança (e-book) e Roteiro para a Conformidade com o RGPD.
Criar instantâneos de base de dados
Um instantâneo de base de dados é uma vista estática e só de leitura de uma base de dados do SQL Server num determinado momento. Apesar de poder copiar um ficheiro de base de dados do Access para criar, na prática, um instantâneo de base de dados, o Access não dispõe de uma metodologia incorporada como SQL Server. Pode utilizar um instantâneo de base de dados para escrever relatórios com base nos dados no momento da criação do instantâneo de base de dados. Também pode utilizar um instantâneo da base de dados para manter os dados de histórico, como um para cada trimestre financeiro para criar relatórios no final do ano fiscal. Sugerimos as seguintes práticas recomendadas:
-
Atribuir um nome ao instantâneo Cada instantâneo de base de dados necessita de um nome de base de dados único. Adicione o objetivo e o período de tempo ao nome para facilitar a identificação. Por exemplo, para criar um instantâneo da base de dados AdventureWorks três vezes por dia em intervalos de 6 horas, entre as 06:00 e as 18:00, com base num relógio de 24 horas, atribua-lhes o nome AdventureWorks_instantâneo_0600, AdventureWorks_instantâneo_1200 e AdventureWorks_instantâneo_1800.
-
Limitar o número de instantâneos Cada instantâneo de base de dados irá persistir até ser explicitamente removido. Uma vez que cada instantâneo continuará a crescer, poderá ser aconselhável poupar espaço em disco ao eliminar um instantâneo antigo após criar um novo. Por exemplo, se estiver a criar relatórios diários, mantenha o instantâneo de base de dados durante 24 horas e, em seguida, remova-o e substitua-o por um novo.
-
Ligar-se ao instantâneo correto Para utilizar um instantâneo de base de dados, o front-end do Access precisa de saber a localização correta. Ao substituir um instantâneo existente por um novo, precisa de redirecionar o Access para o novo instantâneo. Adicione lógica ao front-end do Access para se certificar de que liga ao instantâneo de base de dados correto.
Eis como criar um instantâneo de base de dados:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Para mais informações, consulte Instantâneos de Base de Dados (SQL Server).
Controlo de simultaneidade
Quando vários pessoas tentarem modificar os dados numa base de dados ao mesmo tempo, é necessário um sistema de controlos para que as alterações efetuadas por uma pessoa não afetem de forma adversa as de outra pessoa. Este procedimento é denominado controlo de simultaneidade, e existem duas estratégias de bloqueio básicas: pessimista e otimista. O bloqueio pode impedir os utilizadores de modificarem os dados de uma forma que afete outros utilizadores. O bloqueio também ajuda a garantir a integridade da base de dados, especialmente em consultas que podem produzir resultados inesperados. Existem diferenças importantes na forma como o Access e o SQL Server implementam estas estratégias de controlo de simultaneidade.
No Access, a estratégia de bloqueio predefinida é otimista e concede a titularidade do bloqueio à primeira pessoa a tentar escrever num registo. O Access apresenta a caixa de diálogo Conflito de Escrita à outra pessoa que esteja a tentar escrever no mesmo registo ao mesmo tempo. Para resolver o conflito, a outra pessoa pode guardar o registo, copiá-lo para a área de transferência ou remover as alterações.
Também pode utilizar a propriedade ProteçõesDeRegistos para alterar a estratégia de controlo da simultaneidade. Esta propriedade afeta formulários, relatórios e consultas e tem três definições:
-
Sem Proteções Num formulário, os utilizadores podem tentar editar o mesmo registo em simultâneo, mas a caixa de diálogo Conflito de Escrita poderá ser apresentada. Num relatório, os registos não estão protegidos enquanto o relatório estiver a ser pré-visualizado ou impresso. Numa consulta, os registos não estão protegidos enquanto a consulta está a ser executada. Esta é a forma do Access implementar a proteção otimista.
-
Todos os Registos Todos os registos na consulta ou tabela subjacente estão protegidos enquanto o formulário estiver aberto na Vista Formulário ou na Vista Folha de Dados, enquanto o relatório estiver a ser pré-visualizado ou impresso ou enquanto a consulta estiver a ser executada. Os utilizadores podem ler os registos durante o bloqueio.
-
Registo editado No caso dos formulários e consultas, uma página de registos é protegida assim que um utilizador começar a editar um campo no registo e fica protegida até o utilizador mudar para outro registo. Consequentemente, um registo apenas pode ser editado por um utilizador de cada vez. Esta é a forma do Access implementar a proteção pessimista.
Para mais informações, consulte Caixa de diálogo Conflito de Escrita e Propriedade ProteçõesDeRegistos.
No SQL Server, o controlo de simultaneidade funciona da seguinte forma:
-
Pessimista Após um utilizador efetuar uma ação que faça com que um bloqueio seja aplicado, os outros utilizadores não podem executar ações que possam entrar em conflito com o bloqueio até que o proprietário remova o mesmo. Este controlo de simultaneidade é utilizado principalmente em ambientes onde existe um nível de concorrência elevado no acesso aos dados.
-
Otimista No controlo de concorrência otimista, os utilizadores não bloqueiam os dados enquanto os leem. Quando um utilizador atualiza os dados, o sistema verifica se outro utilizador alterou os dados após a leitura dos mesmos. Se outro utilizador tiver atualizado os dados, é gerado um erro. Normalmente, o utilizador que recebe o erro reverte a transação e inicia o processo novamente. Este controlo de simultaneidade é utilizado principalmente em ambientes onde existe um nível de concorrência baixo no acesso aos dados.
Pode especificar o tipo de controlo de simultaneidade ao selecionar vários níveis de isolamento de transações, que definem o nível de proteção da transação a respeito de modificações efetuadas por outras transações, ao utilizar a instrução SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Nível de isolamento |
Descrição |
|
Ler consolidações não confirmadas |
As transações são isoladas apenas o suficiente para garantir que os dados danificados fisicamente não sejam lidos. |
|
Ler consolidações |
As transações podem ler dados lidos anteriormente por outra transação sem aguardar que a primeira transação seja concluída. |
|
Leitura repetida |
Os bloqueios de leitura e de escrita ocorrem nos dados selecionados até ao fim da transação, mas é possível que ocorram leituras fantasma. |
|
Instantâneo |
Utiliza a versão de linha para fornecer consistência de leitura ao nível da transação. |
|
Serializável |
As transações são completamente isoladas umas das outras. |
Para mais informações, consulte Guia para Bloqueio de Transações e Controlo de Versão de Linha.
Melhorar o desempenho das consultas
Assim que tiver uma consulta pass-through operacional no Access, tire partido dos métodos sofisticados disponíveis no SQL Server para que funcione de forma mais eficiente.
Ao contrário de uma base de dados do Access, o SQL Server fornece consultas em paralelo para otimizar a execução de consultas e as operações de indexação em computadores com mais de um microprocessador (CPU). Uma vez que o SQL Server pode executar uma consulta ou uma operações de indexação em paralelo através de vários threads de trabalho do sistema, a operação pode ser concluída de forma rápida e eficiente.
As consultas são uma componente crítica para melhorar o desempenho geral da sua solução de base de dados. As consultas incorretas são executadas indefinidamente, excedem o tempo limite de execução e consomem recursos como CPUs, memória e largura de banda de rede. Estes fatores impedem a disponibilidade de informações comerciais importantes. Uma só consulta incorreta pode causar problemas de desempenho graves na sua base de dados.
Para mais informações, consulte Consultas mais rápidas com o SQL Server (e-book).
Otimização de consultas
Várias ferramentas funcionam em conjunto para o ajudar a analisar e a melhorar o desempenho de uma consulta: Otimizador de Consultas, planos de execução e Arquivo de Consultas.
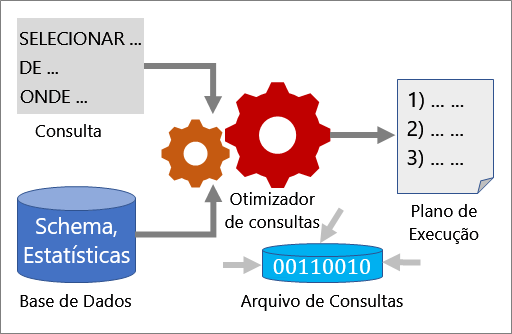
Otimizador de consultas
O Otimizador de Consultas é um dos componentes mais importantes do SQL Server. Utilize o otimizador de consultas para analisar uma consulta e determinar a forma mais eficaz de aceder aos dados necessários. A entrada para o Otimizador de Consultas consiste na consulta, no esquema da base de dados (definições de tabela e indexação) e nas estatísticas da base de dados. O resultado do Otimizador de Consultas é um plano de execução.
Para mais informações, consulte O Otimizador de Consultas do SQL Server.
Plano de execução
Um plano de execução é uma definição que sequencia as tabelas de origem para aceder aos dados de cada tabela e os métodos utilizados para extrair os mesmos. A otimização é o processo de seleção de um plano de execução entre potencialmente muitos planos possíveis. Cada plano de execução possível tem um custo associado ao nível da quantidade de recursos computacionais utilizados, e o Otimizador de Consultas seleciona o que tem o custo estimado mais baixo.
O SQL Server também tem de se ajustar de forma dinâmica às mudanças nas condições da base de dados. As regressões em planos de execução de consultas podem afetar significativamente o desempenho. Algumas alterações numa base de dados podem fazer com que um plano de execução se torne ineficiente ou inválido, com base no novo estado da base de dados. O SQL Server detecta as alterações que invalidam um plano de execução e marca o plano como não válido.
Em seguida, será necessário recompilar um novo plano para a próxima ligação que executa a consulta. As condições que invalidam um plano incluem:
-
Alterações efetuadas a uma tabela ou vista referenciada pela consulta (ALTER TABLE e ALTER VIEW).
-
Alterações aos índices utilizados pelo plano de execução.
-
Atualizações de estatísticas utilizadas pelo plano de execução, geradas explicitamente a partir de uma instrução, como UPDATE STATISTICS ou de forma automática.
Para mais informações, consulte Planos de Execução.
Arquivo de Consultas
O Arquivo de Consultas fornece informações sobre a escolha do plano de execução e o desempenho. Esta funcionalidade simplifica a resolução de problemas de desempenho ao ajudá-lo a encontrar rapidamente diferenças de desempenho causadas por alterações ao plano de execução. O Arquivo de Consultas recolhe dados de telemetria, como um histórico de consultas, planos, estatísticas de tempo de execução e estatísticas de tempo de espera. Utilize a instrução ALTER DATABASE para implementar o Arquivo de Consulta:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Para mais informações, consulte Monitorizar o desempenho através do Arquivo de Consultas
Correção Automática de Planos
A forma mais fácil de melhorar o desempenho das consultas será talvez através da Correção Automática de Planos, que é uma funcionalidade disponibilizada com a Base de Dados SQL do Azure. Basta ativá-la e deixá-la funcionar. Esta funcionalidade executa continuamente a monitorização e a análise de planos de execução, detecta planos de execução problemáticos e corrige automaticamente problemas de desempenho. Em segundo plano, a Correção Automática de Planos utiliza uma estratégia de quatro passos: aprender, adaptar, verificar e repetir.
Para mais informações, consulte Otimização automática.
Processamento de Consultas Adaptável
Também pode obter consultas mais rapidamente ao atualizar para o SQL Server 2017, que tem uma nova funcionalidade denominada processamento de consultas adaptável. O SQL Server ajusta as opções de plano de consultas com base nas características do tempo de execução.
A estimativa de cardinalidade aproxima o número de linhas processadas em cada passo de um plano de execução. As estimativas imprecisas podem resultar num tempo de resposta da consulta lento, na utilização desnecessária de recursos (memória, CPU e E/S), além de débito e simultaneidade reduzidos. São utilizadas três técnicas para a adaptação às características de carga de trabalho da aplicação:
-
Feedback da concessão de memória em modo de lote As estimativas de cardinalidade deficientes podem fazer com que as consultas sejam “transpostas para o disco” ou ocupem muita memória. O SQL Server 2017 ajusta a concessão de memória com base no feedback da execução, remove transposições para o disco e melhora a simultaneidade de consultas repetidas.
-
Associações adaptáveis de modo de lote As associações adaptáveis selecionam, de forma dinâmica, um tipo de associação interna melhor (associações de ciclo aninhado, associações de união ou associações hash) durante a execução, com base em linhas de entrada reais. Consequentemente, um plano pode mudar, de forma dinâmica, para uma estratégia de associação melhorada durante a execução.
-
Execução intercalada As funções com valores de tabela com várias instruções foram tradicionalmente tratadas como uma caixa negra pelo processamento de consultas. O SQL Server 2017 consegue fazer uma estimativa melhor das contagens de linhas para melhorar as operações a jusante.
Pode fazer com que as cargas de trabalho sejam automaticamente elegíveis para processamento de consultas adaptável ao ativar um nível de compatibilidade de 140 para a base de dados:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Para obter mais informações, consulte Processamento inteligente de consultas em bases de dados SQL.
Métodos de consulta
No SQL Server, existem várias formas de consultar, e cada uma tem as suas vantagens. Quer saber em que consistem, para que possa tomar a decisão certa para a sua solução do Access. A melhor forma de criar as suas consultas TSQL é editá-las e testá-las de forma interativa através do editor Transact-SQL do SQL Server Management Studio (SSMS) que tem Intellisense para o ajudar a selecionar as palavras-chave corretas e a verificar se existem erros de sintaxe.
Vistas
No SQL Server, uma vista é como uma tabela virtual onde os dados da visualização provêm de uma ou mais tabelas ou de outras vistas. No entanto, as vistas são referenciadas da mesma forma que as tabelas nas consultas. As vistas podem ocultar a complexidade das consultas e ajudar a proteger os dados ao limitar o conjunto de linhas e colunas. Eis um exemplo de uma vista simples:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Para um ótimo desempenho e para editar os resultados da vista, crie uma vista indexada, que persiste na base de dados como uma tabela, tem armazenamento alocado à mesma e pode ser consultada como qualquer tabela. Para utilizá-la no Access, crie uma ligação para a vista da mesma forma que cria uma ligação para uma tabela. Eis um exemplo de uma vista indexada:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Contudo, existem restrições. Não é possível atualizar os dados se mais do que uma tabela base for afetada ou a vista incluir funções de agregação ou uma cláusula DISTINCT. Se o SQL Server devolver uma mensagem de erro a informar que não sabe qual o registo a eliminar, poderá ter de adicionar um ativador de eliminação na vista. Por fim, não pode utilizar a cláusula ORDER BY como numa consulta do Access.
Para mais informações, consulte Vistas e Criar Vistas Indexadas.
Procedimentos armazenados
Um procedimento armazenado é um grupo de uma ou mais instruções TSQL que têm parâmetros de entrada, devolvem parâmetros de saída e indicam o sucesso ou a falha com um valor de estado. Atuam como uma camada intermédia entre o acesso front-end do Access e o back-end do SQL Server. Os procedimentos armazenados podem ser tão simples como uma instrução SELECT ou complexos como qualquer programa. Eis um exemplo:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Ao utilizar um procedimento armazenado no Access, este devolve normalmente um conjunto de resultados a um formulário ou relatório. No entanto, o procedimento pode efetuar outras ações que não devolvam resultados, tais como instruções DDL ou DML. Ao utilizar uma consulta pass-through, certifique-se de que configura corretamente a propriedade Devolve Registos.
Para mais informações, consulte Procedimentos armazenados.
Expressões de Tabela Comuns
As Expressões de Tabela Comuns (CTE) são como uma tabela temporária que gera um conjunto de resultados com nome. Apenas existem para a execução de uma única consulta ou instrução DML. As CTE baseiam-se na mesma linha de código que a instrução SELECT ou a instrução DML que a utiliza, ao passo que a criação e a utilização de uma tabela ou vista temporárias consistem geralmente num processo de dois passos. Eis um exemplo:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
As CTEs têm vários benefícios, incluindo o seguinte:
-
Uma vez que as CTEs são temporárias, não tem de criá-las como objetos de base de dados permanentes, como as vistas.
-
Pode referenciar a mesma CTE mais do que uma vez numa consulta ou instrução DML, o que torna o seu código mais fácil de gerir.
-
Pode utilizar consultas que façam referência a uma CTE para definir um cursor.
Para mais informações, consulte WITH common_table_expression.
Funções Definidas pelo Utilizador
Uma função definida pelo utilizador (UDF) pode efetuar consultas e cálculos e devolver valores escalares ou conjuntos de resultados de dados. São como funções em linguagens de programação que aceitam parâmetros, executam uma ação, tal como um cálculo complexo, e devolvem o resultado dessa ação como um valor. Eis um exemplo:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Uma UDF tem determinadas limitações. Por exemplo, não podem utilizar determinadas funções não determinísticas do sistema, executar instruções DML ou DDL ou efetuar consultas SQL dinâmicas.
Para mais informações, consulte Funções Definidas pelo Utilizador.
Adicionar chaves e índices
Seja qual for o sistema de base de dados que utiliza, as chaves e os índices são indissociáveis.
Chaves
No SQL Server, certifique-se de que cria chaves primárias para cada tabela e chaves externas para cada tabela relacionada. A funcionalidade equivalente no SQL Server ao tipo de dados Numeração automática do Access é a propriedade IDENTITY, que pode ser utilizada para criar valores de chave. Após aplicar esta propriedade a qualquer coluna numérica, esta torna-se só de leitura e é mantida pelo sistema de bases de dados. Quando insere um registo numa tabela que contém uma coluna IDENTITY, o sistema incrementa automaticamente o valor da coluna IDENTITY em 1 e a partir de 1, mas pode controlar estes valores com argumentos.
Para obter mais informações, consulte CREATE TABLE, IDENTITY (Propriedade).
Índices
Como sempre, a seleção de índices representa um compromisso entre a velocidade da consulta e o custo da atualização. No Access, tem um tipo de índice, ao passo que no SQL Server tem doze. Felizmente, pode utilizar o otimizador de consultas para o ajudar a escolher, de forma fiável, o índice mais eficaz. No Azure SQL, pode utilizar a gestão automática de índices, uma funcionalidade da otimização automática que recomenda a adição ou remoção de índices. Ao contrário do Access, tem de criar os seus próprios índices para chaves externas no SQL Server. Também pode criar índices numa vista indexada para melhorar o desempenho da consulta. A desvantagem de uma vista indexada é uma maior sobrecarga quando modifica os dados nas tabelas base da vista, uma vez que a vista também tem de ser atualizada. Para mais informações, consulte Guia de Estrutura e Arquitetura de Índices no SQL Server e Índices.
Executar transações
É difícil executar um Processo de Transação online (OLTP) ao utilizar o Access, mas no SQL Server é relativamente fácil. Uma transação é uma unidade de trabalho individual que consolida todas as alterações de dados quando é efetuada com êxito, mas reverte as alterações quando não é bem-sucedida. As transações têm de ter quatro propriedades, muitas vezes referidas como ACID:
-
Atomicidade Uma transação tem de ser uma unidade de trabalho atómica: todas as modificações de dados têm de ser efetuadas, caso contrário, nenhuma será executada.
-
Consistência Quando concluída, a transação tem de deixar todos os dados num estado consistente. Isto significa que todas as regras de integridade de dados são aplicadas.
-
Isolamento As alterações efetuadas por transações simultâneas são isoladas da transação atual.
-
Durabilidade Após a conclusão de uma transação, as alterações são permanentes, mesmo em caso de uma falha de sistema.
A utilização de uma transação visa garantir a integridade dos dados, tal como um levantamento de dinheiro numa caixa multibanco ou um depósito automático de um cheque. Pode efetuar transações explícitas, implícitas ou com base no âmbito de um lote. Eis dois exemplos de TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Para mais informações, consulte Transações.
Utilizar restrições e ativadores
Todas as bases de dados têm formas de manter a integridade dos dados.
Restrições
No Access, pode impor a integridade referencial numa relação de tabela através de pares de chaves primárias e externas, atualizações e eliminações em cascata e regras de validação. Para obter mais informações, consulte o Guia para relações de tabelas e Restringir a introdução de dados através de regras de validação.
No SQL Server, pode utilizar as restrições UNIQUE e CHECK, que são objetos de base de dados que forçam a integridade dos dados em tabelas do SQL Server. Para verificar se um valor é válido noutra tabela, utilize uma restrição de chave externa. Para validar que um valor numa coluna está dentro de um intervalo específico, utilize uma restrição CHECK. Estes objetos são a sua primeira linha de defesa e foram concebidos para trabalhar de forma eficiente. Para obter mais informações, consulte Restrições UNIQUE e Restrições CHECK.
Ativadores
O Access não tem ativadores de base de dados. No SQL Server, pode utilizar ativadores para aplicar regras complexas de integridade de dados e para executar esta lógica de negócio no servidor. Um ativador de base de dados é um procedimento armazenado que é executado quando ocorrem ações específicas numa base de dados. O ativador é um evento, como adicionar ou eliminar um registo a uma tabela, que é acionado e, em seguida, executa o procedimento armazenado. Apesar de uma base de dados do Access poder garantir a integridade referencial quando um utilizador tenta atualizar ou eliminar dados, o SQL Server tem um conjunto sofisticado de ativadores. Por exemplo, pode programar um ativador para eliminar registos em volume e garantir a integridade dos dados. Pode inclusivamente adicionar ativadores a tabelas e vistas.
Para obter mais informações, consulte Ativadores - DML, Ativadores - DDL e Estruturar um ativador T-SQL.
Utilizar colunas calculadas
No Access, pode criar uma coluna calculada ao adicioná-la a uma consulta e criar uma expressão, tal como:
Extended Price: [Quantity] * [Unit Price]
No SQL Server, a funcionalidade equivalente chama-se também uma coluna calculada, que é uma coluna virtual que não está fisicamente armazenada na tabela, a não ser que a coluna esteja marcada como PERSISTENTES. Tal como numa coluna calculada no Access, uma coluna calculada no SQL Server utiliza dados de outras colunas numa expressão. Para criar uma coluna calculada, adicione-a a uma tabela. Por exemplo:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Para mais informações, consulte Especificar Colunas Calculadas numa Tabela.
Adicionar carimbo de data/hora aos seus dados
Por vezes, adiciona um campo de tabela para guardar um carimbo de data/hora quando um registo é criado, para que possa registar a introdução de dados. No Access, pode simplesmente criar uma coluna de data com o valor predefinido de =Now(). Para guardar uma data ou hora no SQL Server, utilize o tipo de dados datetime2 com o valor predefinido de SYSDATETIME().
Nota Evite a confusão com rowversion ao adicionar um carimbo de data/hora aos seus dados. A palavra-chave "carimbo de data/hora" é sinónima de "rowversion" no SQL Server, mas deve usar a palavra-chave "rowversion". No SQL Server, rowversion é um tipo de dados que expõe números binários exclusivos gerados automaticamente numa base de dados e é, geralmente, utilizado como um mecanismo para carimbar a versão nas linhas de tabela. No entanto, o tipo de dados rowversion é apenas um número incremental, não preserva uma data ou hora e não foi concebido para adicionar um carimbo de data/hora a uma linha.
Para mais informações, consulte rowversion. Para obter mais informações sobre como utilizar o rowversion para minimizar os conflitos de registos, consulte Migrar uma base de dados do Access para o SQL Server.
Gerir objetos grandes
No Access, pode gerir dados não estruturados, como ficheiros, fotografias e imagens, ao utilizar o Tipo de dados Anexo. Na terminologia do SQL Server, os dados não estruturados chamam-se Blob (Objetos Binários Grandes) e existem várias formas de trabalhar com eles:
FILESTREAM Utiliza o tipo de dados varbinary(max) para armazenar os dados não estruturados no sistema de ficheiros, em vez de na base de dados. Para mais informações, consulte Dados FILESTREAM do Access com Transact-SQL.
FileTable Armazena blobs em tabelas especiais denominadas FileTables e fornece compatibilidade com as aplicações do Windows, como se estivessem armazenados no sistema de ficheiros e sem fazer alterações às suas aplicações cliente. FileTable requer a utilização de FILESTREAM. Para mais informações, consulte FileTables.
Arquivo remoto de BLOBs (RBS) Armazena objetos binários grandes (BLOBs) em soluções de armazenamento comerciais em vez de diretamente no servidor. Esta ação poupa espaço e reduz os recursos de hardware. Para mais informações, consulte Dados de Objetos Binários Grandes (Blob).
Trabalhar com dados hierárquicos
Apesar de as bases de dados relacionais, como o Access, serem bastante flexíveis, trabalhar com relações hierárquicas é uma exceção que requer, muitas vezes, instruções SQL ou código complexos. Os exemplos de dados hierárquicos incluem: uma estrutura organizacional, um sistema de ficheiros, uma taxonomia de termos linguísticos e um gráfico de ligações entre páginas Web. O SQL Server tem um tipo de dados hierarchyid incorporado e um conjunto de funções hierárquicas para armazenar, consultar e gerir facilmente dados hierárquicos.
Para obter mais informações, consulte Dados hierárquicos e Tutorial: Utilizar o tipo de dados hierarchyid.
Manipular texto JSON
JavaScript Object Notation (JSON) é um serviço Web que utiliza texto legível por utilizadores de forma a transmitir dados como pares atributo–valor em comunicações assíncronas browser–servidor. Por exemplo:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
O Access não tem métodos incorporados para a gestão de dados JSON, ao passo que, no SQL Server, pode armazenar, indexar, consultar e extrair dados JSON de forma simples. Pode converter e armazenar texto JSON numa tabela ou formatar dados como texto JSON. Por exemplo, poderá querer formatar resultados de consultas como JSON para uma aplicação Web ou adicionar estruturas de dados JSON a linhas e colunas.
Nota JSON não é suportado no VBA. Como alternativa, pode utilizar XML no VBA através da biblioteca MSXML.
Para mais informações, consulte Dados JSON no SQL Server.
Recursos
Este é o momento ideal para saber mais sobre o SQL Server e o Transact SQL (TSQL). Como pôde ver, existem muitas funcionalidades como no Access, mas também outras ferramentas que simplesmente não estão disponíveis no Access. Para complementar esta apresentação, eis alguns recursos de aprendizagem:
|
Recurso |
Descrição |
|
Curso baseado em vídeo |
|
|
Tutoriais sobre o SQL Server 2017 |
|
|
Aprendizagem prática sobre o Azure |
|
|
Torne-se um especialista |
|
|
A página de destino principal |
|
|
Informações de Ajuda |
|
|
Informações de ajuda |
|
|
Uma descrição geral da nuvem |
|
|
Um resumo visual das novas funcionalidades |
|
|
Um resumo das funcionalidades por versões |
|
|
Transfira o SQL Server Express 2017 |
|
|
Transfira bases de dados de exemplo |









