
En korrekt utformad databas ger dig tillgång till aktuell och korrekt information. Eftersom en korrekt design är nödvändig för att du ska kunna uppnå dina mål när du arbetar med en databas, så är det vettigt att investera den tid som krävs för att lära sig principerna för god design. I slutändan blir det då långt mer sannolikt att du får en databas som uppfyller dina behov och som kan ändras enkelt.
Den här artikeln innehåller riktlinjer för planering av en skrivbordsdatabas. Du får lära dig att avgöra vilken information du behöver och hur du ska dela in den informationen i lämpliga tabeller och kolumner, samt hur tabellerna förhåller sig till varandra. Du bör läsa den här artikeln innan du skapar din första skrivbordsdatabas.
Artikelinnehåll
Databastermer som är bra att känna till
Access ordnar din information i tabeller: listor med rader och kolumner som påminner om en revisors block eller ett kalkylblad. I en enkel databas kanske du bara har en tabell. För de flesta databaser behöver du fler än en. Du kan till exempel ha en tabell som lagrar information om produkter, en annan tabell som lagrar information om order och en annan tabell med information om kunder.
Varje rad kan mer korrekt kallas för en post, och varje kolumn för ett fält. En post är ett meningsfullt och konsekvent sätt att kombinera information om något. Ett fält är en enstaka bit information – en objekttyp som visas i varje post. I tabellen Produkter skulle t.ex. varje rad eller post innehålla information om en produkt. Varje kolumn eller fält skulle innehålla en viss typ av information om den produkten, exempelvis dess namn eller pris.
Vad är god databasdesign?
Det finns vissa principer som bör vägleda arbetet med databasdesign. Den första principen är att duplicerad information (kallas även redundanta data) är något dåligt, eftersom det tar upp utrymme och ökar risken för fel och inkonsekvenser. Den andra principen är att det är viktigt att informationen är korrekt och komplett. Om databasen innehåller felaktig information, så kommer även rapporter som hämtar information från databasen att innehålla felaktig information. I sådant fall kommer eventuella beslut som du fattar utifrån dessa rapporter att bygga på felaktig information.
Det innebär att en god databasdesign gör följande:
-
Delar upp informationen i ämnesbaserade tabeller för att minska redundanta data.
-
Förser Access med den information som behövs för att sammanfoga informationen i tabellerna vid behov.
-
Bidrar till att stödja och säkerställa korrektheten och fullständigheten hos informationen.
-
Klarar att uppfylla dina databehandlings- och rapporteringsbehov.
Designprocessen
Designprocessen består av följande steg:
-
Bestäm syftet med databasen
Det här steget är en förberedelse för resten av stegen.
-
Hitta och strukturera den information som behövs
Samla in alla de typer av information som du kan vilja lagra i databasen, t.ex. produktnamn och ordernummer.
-
Dela upp informationen i tabeller
Dela upp dina informationsobjekt i olika grupper eller ämnen, t.ex. produkter eller beställningar. Varje ämne blir en egen tabell.
-
Omvandla informationsobjekt till kolumner
Bestäm vilken information du ska lagra i varje tabell. Varje objekt blir ett fält och visas som en kolumn i tabellen. Tabellen Personal kan t.ex. innehålla fält som Efternamn och Anställningsdatum.
-
Ange primärnycklar
Välj primärnyckel för varje tabell. Primärnyckeln är en kolumn som används för att identifiera varje enskild rad. Ett exempel kan vara produkt-ID eller beställnings-ID.
-
Skapa tabellrelationer
Titta på varje tabell och avgör hur data i en tabell förhåller sig till data i andra tabeller. Lägg till fält i tabeller eller skapa nya tabeller för att klargöra relationer efter behov.
-
Förfina designen
Analysera designen och sök efter fel. Skapa tabeller och lägg till några poster med exempeldata. Se om du får önskat resultat från tabellerna. Justera designen vid behov.
-
Tillämpa normaliseringsregler
Tillämpa datanormaliseringsregler för att ta reda på om tabellerna är strukturerade på rätt sätt. Justera tabellerna vid behov.
Bestämma syftet med databasen
Det är en bra idé att skriva ned syftet med databasen på papper, inklusive hur du tänker använda den och vem som ska använda den. För en liten databas för en verksamhet du driver hemifrån kan du t.ex. skriva något enkelt, som ”Kunddatabasen innehåller en lista med kundinformation för att skapa utskick och ta fram rapporter”. Om databasen är mer komplex eller används av många personer, vilket ofta är fallet i företagsmiljöer, så kan syftet bli ett helt stycke lång, eller flera stycken, och redogöra för när och hur varje person ska använda databasen. Tanken är att ha en väl utvecklad uppdragsbeskrivning som du kan hänvisa till under hela designprocessen. En sådan beskrivning gör det lättare för dig att fokusera på dina mål när du ska fatta beslut.
Hitta och strukturera den information som behövs
När du ska hitta och strukturera informationen du behöver börjar du med din befintliga information. Du kanske registrerar inköpsorder i en huvudbok eller har din kundinformation på pappersformulär i ett arkivskåp. Samla in de relevanta dokumenten och skapa en lista över de olika typerna av information som visas (t.ex. de olika rutorna du fyller i i ett formulär). Om du inte har något befintligt formulär kan du istället tänka dig att din uppgift är att skapa ett formulär för registrering av kundinformation. Vilken information skulle du ta med i formuläret? Vilka ifyllningsfält skulle du skapa? Identifiera alla dessa uppgifter och ta med dem i listan. Anta att du för närvarande har din kundlista på arkivkort. Efter en undersökning av korten kanske du upptäcker att varje kort innehåller en kunds namn, adress, ort, region, postnummer och telefonnummer. Var och en av dessa uppgifter representerar en möjlig kolumn i en tabell.
När du förbereder den här listan behöver du inte anstränga dig för att få till allting perfekt från början. Skriv i stället ned alla tänkbara uppgifter som du kommer på. Om någon annan ska använda databasen kan du be dem att dela med sig av sina tankar också. Du kan alltid finjustera listan senare.
Nästa steg är att fundera på vilka typer av rapporter och utskick du kan tänkas vilja skapa utifrån databasen. Du kanske t.ex. vill ha en produktförsäljningsrapport som visar försäljningen per region, eller en sammanfattningsrapport för inventering där lagernivåerna för olika produkter visas. Du kanske även vill generera standardbrev som du ska skicka till kunder för att meddela om en kampanj eller ett erbjudande. Utforma rapporten i huvudet och föreställ dig hur den skulle se ut. Vilken information skulle du ta med i rapporten? Ta med alla uppgifter i listan. Gör samma sak för standardbrevet och eventuella andra rapporter som du planerar att skapa.

Att tänka över de rapporter och utskick du kanske vill skapa kan hjälpa dig att identifiera de uppgifter som du behöver ha med i databasen. Anta t.ex. att du ger kunder möjlighet att välja om de vill få regelbundna uppdateringar via e-post, och att du vill skriva ut en lista över kunder som angett att de vill ha dessa meddelanden. Om du vill nedteckna den informationen måste du lägga till kolumnen ”Skicka e-post” i kundtabellen. För varje kund kan du sedan ställa in fältet som Ja eller Nej.
Om du behöver skicka e-postmeddelanden till kunder är det ganska lätt att komma på en annan uppgift som behöver nedtecknas. När du vet att en kund vill ta emot e-postmeddelanden, så måste du också veta vilken e-postadress du ska skicka dem till. Du måste därför registrera en e-postadress för varje kund.
Det är vettigt att skapa en prototyp av varje rapport eller utdatalistning och fundera över vilka objekt du behöver för att producera rapporten. När du till exempel undersöker ett formulärbrev kan några saker komma att tänka på. Om du vill ta med en korrekt hälsningsfras, till exempel strängen "Herr", "Fru" eller "Ms" som inleder en hälsningsfras, måste du skapa en hälsningsfras. Dessutom kan du vanligtvis börja ett brev med "Dear Mr. Smith", snarare än "Dear. Mr Sylvester Smith" Det här tyder på att du vanligtvis vill lagra efternamnet separat från förnamnet.
En viktig sak att komma ihåg är att du ska dela upp varje typ av information i sina minsta användbara beståndsdelar. När det gäller namn bör du lagra dem i två delar – förnamn och efternamn – så att du kan använda endast efternamnet. Om du t.ex. vill sortera en rapport efter efternamn, så hjälper det t.ex. om du har kundens efternamn lagrat för sig. Rent allmänt gäller att om du vill sortera, söka, beräkna eller rapportera utifrån en viss informationskomponent, så ska den informationen finnas i ett eget fält.
Koncentrera dig på de frågor som du kan tänkas vilja att databasen ska besvara. Till exempel, hur många försäljningar av en viss produkt genomfördes förra månaden? Var bor dina bästa kunder ? Vem är leverantören för din bästsäljande produkt? Om du kan förutse de här frågorna så blir det lättare att lista ut vilka ytterligare uppgifter du behöver ta med.
När du samlat in den här informationen är du redo för nästa steg.
Dela upp informationen i tabeller
När du ska dela upp informationen i tabeller väljer du större enheter eller ämnen. När du hittar och strukturerar information för en produktförsäljningsdatabas, så kanske den preliminära listan ser ut så här:

De större enheterna som visas här är produkterna, leverantörerna, kunderna och beställningarna. Därför är det vettigt att utgå från de här fyra tabellerna: en för fakta om produkter, en för fakta om leverantörer, en för fakta om kunder och en för fakta om beställningar. Även om det kanske inte är en helt färdig lista, så är det en bra utgångspunkt. Du kan fortsätta att förfina den här listan tills du fått till en design som fungerar bra.
När du först granskar den preliminära listan över objekt, så kanske du frestas att placera dem alla i en enda tabell, i stället för de fyra som visas i bilden ovan. Du kommer nu att få veta varför det är en dålig idé. Ta en titt på tabellen som visas nedan:
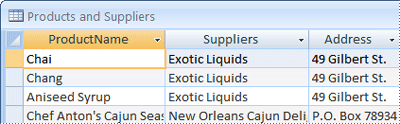
I det här fallet innehåller varje rad information om både produkten och dess leverantör. Eftersom du kan ha många produkter från samma leverantör, så måste leverantörens namn och adress upprepas många gånger. Det slösar lagringsutrymme. Det är en mycket bättre lösning att spara leverantörsinformationen en gång i en separat leverantörstabell och sedan länka den tabellen till tabellen Produkter.
Ett andra problem med denna design blir tydligt när du vill ändra information om leverantören. Anta att du t.ex. behöver ändra en leverantörs adress. Eftersom den förekommer på många platser kan du råka ändra den på en plats men glömma att ändra den på de andra. Genom att bara ha leverantörens adress på en plats undviker du det problemet.
När du utformar din databas bör du alltid försöka undvika att nedteckna en viss uppgift flera gånger. Om du märker att samma information upprepas på flera ställen, t.ex. en viss leverantörs adress, så bör du placera den informationen i en separat tabell.
Anta slutligen att Coho Winery bara levererar en produkt och att du vill ta bort produkten men behålla leverantörens namn och adressinformation. Hur tar du bort produktposten utan att även förlora leverantörsinformationen? Det går inte. Eftersom varje post innehåller information om en produkt samt information om en leverantör, går det inte att ta bort den ena utan att ta bort den andra. För att hålla dessa data separerade delar du upp tabellen i två tabeller: en för produktinformation och en annan för leverantörsinformation. När du tar bort en produktpost ska endast information om produkten tas bort – inte information om leverantören.
När du har valt det ämne som en tabell ska representera, så ska kolumner i den tabellen endast innehålla information om det ämnet. En produkttabell ska t.ex. bara innehålla information om produkter. Eftersom leverantörens adress är information om leverantören och inte information om produkten, så hör den hemma i tabellen med leverantör.
Omvandla informationsobjekt till kolumner
För att bestämma kolumnerna i en tabell bestämmer du vilken information du behöver spåra om ämnet som registrerats i tabellen. För tabellen Kunder innehåller exempelvis namn, adress, ort-delstat, skicka e-post, hälsningsfras och e-postadress en bra startlista med kolumner. Varje post i tabellen innehåller samma uppsättning kolumner så att du kan lagra information om namn, adress, ortsstatus, skicka e-post, hälsning och e-postadress för varje post. Adresskolumnen innehåller till exempel kundernas adresser. Varje post innehåller data om en kund och adressfältet innehåller adressen till kunden.
När du har fastställt den första uppsättningen kolumner för varje tabell kan du förfina kolumnerna ytterligare. Det är till exempel vettigt att lagra kundnamnet som två separata kolumner: förnamn och efternamn, så att du kan sortera, söka och indexera bara för de kolumnerna. På samma sätt består adressen faktiskt av fem separata komponenter, adress, ort, region, postnummer och land/region, och det är också vettigt att lagra dem i separata kolumner. Om du till exempel vill utföra en sökning, filtrera eller sortera efter tillstånd behöver du den tillståndsinformation som lagras i en separat kolumn.
Du bör även fundera på om databasen enbart kommer innehålla information om inrikeskunder, eller om den även kommer innehålla internationella kunder. Om du planerar att lagra internationella adresser är det bättre om du har kolumnen Region jämfört med kolumnen Län, eftersom en kolumn med regioner kan innehålla både svenska län och andra länders olika regioner. På liknande sätt är kolumnen Postnummer bättre än kolumnen Zip Code om du ska lagra adresser från fler länder än USA.
I följande lista finns några tips för att bestämma vilka kolumner du behöver.
-
Ta inte med beräknade data
I de flesta fall bör du inte lagra resultat från beräkningar i tabeller. Du kan i stället låta Access utföra beräkningarna när du vill visa resultatet. Antag t.ex. att det finns en rapport med namnet Beställda produkter, där delsummorna för beställda enheter i varje produktkategori från databasen visas. Det finns dock ingen kolumn med en delsumma av beställda produkter i någon av tabellerna. I stället innehåller produkttabellen en kolumn med Beställda enheter där antalet beställda enheter lagras för varje produkt. Access beräknar delsumman utifrån dessa data varje gång du skriver ut rapporten. Själva delsumman ska inte lagras i en tabell.
-
Lagra informationen i dess minsta logiska delar
Du kan frestas att ha ett enda fält för fullständiga namn eller för produktnamn tillsammans med produktbeskrivningar. Om du kombinerar mer än en typ av information i ett fält är det svårt att hämta enskilda fakta senare. Försök att dela upp information i logiska delar. Du kan till exempel skapa separata fält för för- och efternamn, eller för produktnamn, kategori och beskrivning.

När du justerat datakolumnerna i tabellerna väljer du en primärnyckel för varje tabell.
Ange primärnycklar
Varje tabell bör ha en kolumn eller uppsättning kolumner som unikt identifierar varje rad som lagrats i tabellen. Detta är ofta ett unikt ID-nummer, t.ex. ett anställningsnummer eller ett serienummer. I databasterminologi heter det att den här informationen är tabellens primärnyckel. Access använder primärnyckelfält för att snabbt koppla samman data från olika tabeller och sammanställa dessa data åt dig.
Om du redan har en unik identifierare för en viss tabell, t.ex. ett produktnummer som unikt identifierar varje produkt i katalogen, så kan du använda den identifieraren som tabellens primärnyckel, men bara om värdena i den här kolumnen alltid kommer vara olika för varje post. Du får inte förekomma dubblettvärden i en primärnyckel. Använd t.ex. inte personers namn som primärnyckel, eftersom namn inte är unika. Det kan lätt hända att du har två personer med samma namn i en viss tabell.
En primärnyckel måste alltid ha ett värde. Om värdet för en kolumn kan tänkas tas bort eller bli okänt (värdet saknas) vid något tillfälle, så kan inte den kolumnen användas som komponent i en primärnyckel.
Du bör alltid välja en primärnyckel vars värde inte kommer ändras. I databaser med flera tabeller kan en tabells primärnyckel användas som en referens i andra tabeller. Om primärnyckeln ändras måste ändringen också tillämpas överallt där det förekommer referenser till nyckeln. Om du använder en primärnyckel som inte kommer ändras, så minskar du risken att primärnyckeln kommer ur synk med andra tabeller som refererar till den.
Ofta används ett godtyckligt unikt nummer som primärnyckel. Du kan t.ex. tilldela varje beställning ett unikt ordernummer. Det enda syftet ordernumret har är just att identifiera en order. När det väl har tilldelats ändras det aldrig.
Om du inte har kommer att tänka på någon kolumn eller uppsättning kolumner som kan fungera bra som primärnyckel, så kan du överväga att använda en kolumn med datatypen Räknare. När du använder datatypen Räknare tilldelas varje post ett värde automatiskt. En sådan identifierare innehåller ingen egentlig information, ingenting som beskriver raden den representerar. Informationslösa identifierare är perfekta att använda som primärnycklar eftersom de inte ändras. Det är mer troligt att en primärnyckel som innehåller information om en rad – t.ex. ett telefonnummer eller en kunds namn – kommer att ändras, eftersom den faktiska uppgifter själv kan komma att ändras.
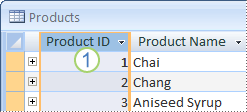
1. En kolumn med datatypen Räknare fungerar ofta bra som primärnyckel. Inga två produkt-ID:n är identiska.
I vissa fall kanske du vill använda två eller flera fält som gemensamt utgör en tabells primärnyckel. Exempelvis skulle en tabell med orderinformation, som innehåller radspecifikationer för order, kunna använda två kolumner i sin primärnyckel: Order-ID och Produkt-ID. När en primärnyckel består av flera kolumner kallas den för en sammansatt nyckel.
I en databas för produktförsäljning kan du skapa kolumner med datatypen Räknare i varje tabell och använda dem som primärnycklar: Produkt-ID för tabellen Produkter, Order-ID för tabellen Order, Kund-ID för tabellen Kunder och Leverantörs-ID för tabellen Leverantörer.

Skapa tabellrelationer
Nu när du har delat upp din information i tabeller behöver du kunna sammanställa informationen på ett meningsfullt sätt. Följande formulär innehåller t.ex. information från flera tabeller.
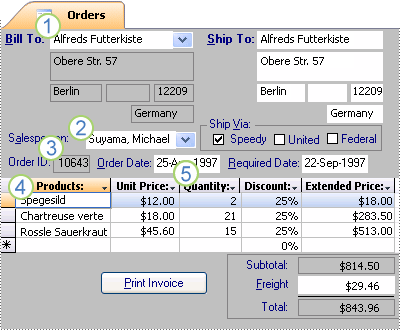
1. Informationen i det här formuläret kommer från tabellen Kunder ...
2. … tabellen Anställda …
3. … tabellen Order …
4. … tabellen Produkter …
5. … och tabellen Orderdetaljer.
Access är ett relationsbaserat databashanteringssystem. I en relationsdatabas delar du upp informationen i separata, ämnesbaserade tabeller. Sedan använder du tabellrelationer för att sammanställa informationen vid behov.
Skapa en 1:N-relation
Fundera på det här exemplet: tabellerna Leverantörer och Produkter i produktorderdatabasen. En viss leverantörer kan tillhandahålla flera produkter. Det följer då att för en leverantör som representeras i tabellen Leverantörer kan det finnas flera produkter representerade i tabellen Produkter. Förhållandet mellan tabellen Leverantörer och Products-tabellen är därför en 1:N-relation.
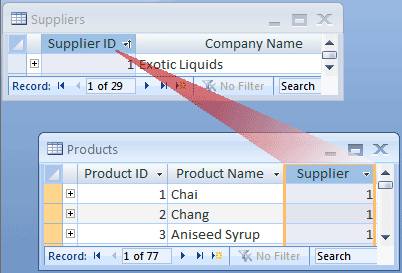
När du representerar en 1:N-relation i databasdesignen ska du ha primärnyckeln på 1-sidan av relationen och lägga till den som ytterligare en kolumn (eller flera kolumner) i tabellen på N-sidan av relationen. I det här fallet lägger du till kolumnen Leverantörs-ID från tabellen Leverantörer i tabellen Produkter. Access kan sedan använda leverantörs-IDt i tabellen Produkter för att hitta rätt leverantör för respektive produkt.
Kolumnen Leverantörs-ID i tabellen Produkter är en så kallad sekundärnyckel. En sekundärnyckel är primärnyckeln för en annan tabell. Kolumnen Leverantörs-ID i tabellen Produkter är en sekundärnyckel eftersom den även är primärnyckel i tabellen Leverantörer.

Du fastställer hur relaterade tabeller är sammankopplade genom att upprätta par av primärnycklar och sekundärnycklar. Om du inte är säker på vilka tabeller som ska bör dela en gemensam kolumn, så kan du utgå ifrån att en identifierad 1:N-relation säkerställer att de två tabellerna som ingår verkligen behöver en gemensam kolumn.
Vad är en många-till-många-relation?
Fundera på relationen mellan tabellerna Produkter och Order.
En enda order kan omfatta flera produkter. Å andra sidan kan en enskild produkt finnas på flera order. Därför kan det för varje post i tabellen Order finnas många poster i tabellen Produkter. För varje post i tabellen Produkter kan det dessutom finnas många poster i tabellen Order. Den här typen av relation kallas för en många-till-många-relation eftersom det kan finnas flera order för varje produkt, och flera olika produkter i varje order. För att du ska kunna hitta många-till-många-relationerna mellan tabeller är det viktigt att du granskar båda sidor av relationen.
Ämnena i de två tabellerna – order och produkter – har en många-till-många-relation. Detta utgör ett problem. För att förstå problemet kan du föreställa dig vad som skulle hända om du försökte skapa en relation mellan de båda tabellerna genom att lägga till fältet produkt-ID i tabellen Order. Om du ska ha flera produkter per order behöver du ha flera poster per order i tabellen Order. Då skulle du få upprepa orderinformationen i varje rad som hör till en viss order, vilket skulle resultera i en ineffektiv design som kan leda till felaktiga data. Du stöter på samma problem om du lägger till fältet Order-ID i tabellen produkter – du skulle få flera poster per produkt i tabellen Produkter. Hur löser du problemet?
Lösningen är att skapa en tredje tabell, som ofta kallas en kopplingstabell, där många-till-många-relationen bryts ned till två 1:N-relationer. Du infogar primärnycklarna från de båda tabellerna i den tredje tabellen. Det innebär att den tredje tabellen lagrar varje enskild förekomst eller instans av relationen.
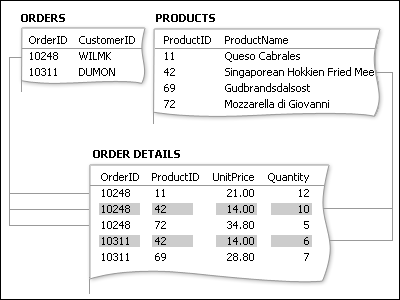
Varje post i tabellen Orderdetaljer representerar ett radobjekt i en order. Primärnyckeln i tabellen Orderdetaljer består av två fält – sekundärnycklar från tabellerna Produkter och Order. Att använda enbart fältet Ordernummer som primärnyckel för den här tabellen fungerar inte eftersom en order kan innehålla många radobjekt. Order-IDt upprepas för varje radobjekt i en order, vilket innebär att värdena i fältet inte är unika. Att enbart använda fältet produkt-ID fungerar inte heller, eftersom en viss produkt kan förekomma i flera olika order. Sammantagna ger dock de två fälten alltid ett unikt värde för varje post.
I databasen för produktförsäljning är tabellerna Order och Produkter inte direkt relaterade till varandra. De är istället indirekt relaterade via tabellen Orderdetaljer. Många-till-många-relation mellan order och produkter representeras i databasen genom två 1:N-relationer:
-
Tabellen Order och tabellen Orderdetaljer har en 1:N-relation. Varje order kan ha flera radobjekt, men varje radobjekt är endast kopplat till en order.
-
Tabellen Produkter och tabellen Orderdetaljer har en 1:N-relation. Varje produkt kan ha flera radobjekt som är kopplade till den, men varje radobjekt refererar endast till en produkt.
Från tabellen Orderdetaljer kan du identifiera alla produkter som hör till en viss order. Du kan även identifiera alla order för en viss produkt.
När du har infört tabellen Orderdetaljer kan listan med tabeller och fält se ut ungefär så här:

Skapa en 1:1-relation
En annan typ av relation är 1:1-relationen. Anta t.ex. att du behöver nedteckna särskilda kompletterande produktuppgifter som sällan behövs, eller som endast gäller ett fåtal av produkterna. Eftersom du inte behöver informationen så ofta, och du skulle få tomma fält i tabellen Produkter för alla produkter som den inte gäller för, så placerar du den i en separat tabell. Precis som i tabellen Produkter använder du Produkt-ID som primärnyckel. Relationen mellan den här extra tabellen och tabellen Produkter är en 1:1-relation. Det finns en enda matchande post i den kompletterande tabellen för varje post i tabellen Produkter. När du identifierar en sådan relation, så måste båda tabeller ha ett gemensamt fält.
När du upptäcker behovet av en 1:1-relation i databasen, så bör du överväga om du kan sammanföra informationen från de båda tabellerna i en tabell. Om du av någon anledning inte vill göra det, kanske för att det skulle orsaka ett stort antal tomma fält, så visar följande lista hur du kan representera relationen i din design:
-
Om de båda tabellerna inte har samma ämne, så kan du antagligen konfigurera relationen genom att använda samma primärnyckel i båda tabeller.
-
Om de två tabellerna har olika ämnen och olika primärnycklar, så väljer du en av tabellerna (vilken som) och infogar primärnyckeln i den andra tabellen som en sekundärnyckel.
Genom att fastställa relationer mellan tabeller kan du säkerställa att du har de rätta tabellerna och kolumnerna. När det finns en 1:1-relation eller en 1:N-relation, så måste de tabeller som ingår ha minst en gemensam kolumn. När det finns en många-till-många-relation, så behövs en tredje tabell som representerar relationen.
Förfina designen
När du har de tabeller, fält och relationer som du behöver bör du skapa tabellerna och fylla dem med exempeldata och sedan prova att arbeta med informationen genom att skapa frågor, lägga till nya poster m.m. Genom att göra det kan du identifiera potentiella problem. Exempelvis kan du behöva lägga till en kolumn som du glömde att infoga under designfasen, eller spå har du kanske en tabell som du borde dela upp i två tabeller för att undvika dubblettinformation.
Kontrollera att du kan använda databasen för att få de svar du vill ha. Skapa utkast av formulär och rapporter, och kontrollera om de visar de data du förväntar dig. Leta efter onödig dubblering av data, och ändra designen för att eliminera den om du hittar den.
När du provar din första version av databasen kommer du antagligen upptäcka att det finns utrymme för förbättring. Här är några saker att kontrollera:
-
Har du glömt några kolumner? I så fall, hör den informationen hemma i de befintliga tabellerna? Om det rör sig om information om något annat, så kanske du måste skapa en ytterligare tabell. Skapa kolumner för alla informationsobjekt som du behöver spåra. Om informationen inte kan beräknas utifrån andra kolumner, så är det sannolikt att du behöver en ytterligare kolumn för den.
-
Finns det några överflödig kolumner som kan beräknas utifrån befintliga fält? Om ett informationsobjekt kan beräknas utifrån andra befintliga kolumner – t.ex. ett rabatterat pris som beräknas utifrån det ordinarie priset – så är det oftast bättre att göra just det och undvika att skapa ny kolumn.
-
Anger du dubblerad information upprepade gånger i någon av dina tabeller? I så fall behöver du antagligen dela upp tabellen i två tabeller med en 1:N-relation till varandra.
-
Har du tabeller med många fält, ett begränsat antal poster och många tomma fält i enskilda poster? I så fall bör du fundera på att ändra tabellens design så att den har färre fält och fler poster.
-
Har alla informationsobjekt brutits ned i sina minsta användbara delar? Om du behöver rapportera, sortera, söka och beräkna utifrån ett informationsobjekt, så lägger du objektet i en egen kolumn.
-
Innehåller varje kolumn ett faktum om tabellens ämne? Om en kolumn inte innehåller information om tabellens ämne, så hör den hemma i en annan tabell.
-
Representeras alla relationer mellan tabeller, antingen av gemensamma fält eller av en tredje tabell? 1:1- och 1:N-relationer kräver gemensamma kolumner. Många-till-många-relationer kräver en tredje tabell.
Förfina tabellen Produkter
Anta att varje produkt i produktförsäljningsdatabasen faller under en allmän kategori, t.ex. drycker, såser eller fisk. Tabellen Produkter kan då innehålla ett fält som visar kategorin för varje produkt.
Anta att du när du granskat och förfinat databasens design bestämmer dig för att lagra en beskrivning av kategorin tillsammans med namnet. Om du då lägger till ett fält med namnet Kategoribeskrivning i tabellen Produkter, så måste du upprepa kategoribeskrivningen för varje produkt som faller under kategorin – det här är ingen bra lösning!
En bättre lösning är att göra Kategorier till ett nytt ämne som spåras i databasen, med en egen tabell och en egen primärnyckel. Du kan sedan lägga till primärnyckeln från tabellen Kategorier i tabellen Produkter som en sekundärnyckel.
Tabellerna Kategorier och Produkter har då en 1:N-relation: en kategori kan innehålla flera produkter, men en produkt kan endast tillhöra en kategori.
När du granskar dina tabellstrukturer, så bör du vara uppmärksam på grupper som upprepas. Anta t.ex. att en tabell innehåller följande kolumner:
-
Produkt-ID
-
Namn
-
Produkt-ID1
-
Namn1
-
Produkt-ID2
-
Namn2
-
Produkt-ID3
-
Namn3
I det här fallet är varje produkt en upprepande grupp med kolumner, som bara skiljer sig från de andra genom att ett nummer lagts till i slutet av kolumnnamnet. När du ser kolumner som är numrerade på det här sättet bör du kontrollera din design.
En sådan design har ett antal svagheter. Till att börja med tvingar den dig att sätta en övre gräns för antalet produkter. Så snart du överskrider gränsen måste du lägga till en ny grupp med kolumner i tabellstrukturen, vilket är en omfattande administrativ uppgift.
Ett annat problem är att de leverantörer som har färre än det maximala antalet produkter lämnar utrymme outnyttjat, eftersom de överflödiga kolumnerna kommer att vara tomma. Det mest allvarliga felet med en sådan design är att den gör många aktiviteter svårt att utföra, t.ex. att sortera eller indexera tabellen efter produkt-ID eller namn.
När du ser grupper som upprepas bör du granska designen nära och se efter om du kan dela upp tabellen i två tabeller. I exemplet ovan skulle det vara bättre att ha två tabeller, en för leverantörer och en för produkter, och länka dem via leverantörs-IDt.
Tillämpa normaliseringsregler
Nästa steg i designarbetet kan vara att tillämpa databasnormaliseringsregler (kallas ibland endast för normaliseringsregler). De här reglerna används för att ta reda på om tabellerna är strukturerade på rätt sätt. Processen att tillämpa regler på databasdesignen kallas för att normalisera databasen, eller bara normalisering.
Normalisering är mest användbart när du redan har representerat alla informationsobjekt och har skapat en preliminär design. Tanken är att du ska kunna se till att du har delat upp dina informationsobjekt mellan lämpliga tabeller. Det som inte går att göra med normalisering är att se till att du har de rätta dataobjekten från början.
Reglerna tillämpas i en följd, och i varje steg säkerställs att designen producerar någon av de som kallas för de ”normalformerna”. Fem normalformer är allmänt accepterade – från den första normalformen till den femte normalformen. I den här artikeln redogör vi för de tre första av dem, eftersom det är allt som krävs för flesta databasdesignerna.
Den första normalformen
Den första normalformen anger att det på varje skärningspunkt mellan rader och kolumner i tabellen ska finnas ett enda värde, och aldrig en lista med värden. Du får t.ex. inte ha ett fält med namnet Pris där du lägger flera olika priser. Om du tänker dig varje skärningspunkt mellan rader och kolumner som en cell, så får varje cell endast innehålla ett värde.
Den andra normalformen
Den andra normalformen kräver att alla kolumner som inte är nyckelkolumner ska vara helt beroende av hela primärnyckeln, inte bara av en del av nyckeln. Den här regeln gäller när du har en primärnyckel som består av flera kolumner. Anta t.ex. att du har en tabell som innehåller följande kolumner, där primärnyckeln utgörs av Order-IDt och Produkt-IDt:
-
Order-ID (primärnyckel)
-
Produkt-ID (primärnyckel)
-
Produktnamn
Den här designen strider mot den andra normalformen eftersom Produktnamn är beroende av Produkt-ID, men inte av Order-ID, vilket innebär att den inte är beroende av hela primärnyckeln. Du måste ta bort Produktnamn från tabellen. Det fältet hör hemma i en annan tabell (Produkter).
Den tredje normalformen
Den tredje normalformen kräver inte bara att varje kolumn som inte är en nyckelkolumn ska vara beroende av hela primärnyckeln, utan även att alla kolumner som inte är nyckelkolumner ska vara oberoende av varandra.
Ett annat sätt att uttrycka det är att alla kolumner som inte är nyckelkolumner måste vara beroende av primärnyckeln och ingenting annat än primärnyckeln. Antag att du t.ex. har en tabell som innehåller följande kolumner:
-
Produkt-ID (primärnyckel)
-
Namn
-
Rek. pris
-
Rabatt
Anta att Rabatt beror på det föreslagna återförsäljarpriset (SRP). Den här tabellen bryter mot tredje normalformen eftersom en icke-nyckelkolumn, Rabatt, beror på en annan icke-nyckelkolumn, SRP. Kolumn oberoende innebär att du ska kunna ändra alla icke-nyckelkolumner utan att påverka någon annan kolumn. Om du ändrar ett värde i fältet SRP ändras rabatten i enlighet därmed, vilket strider mot regeln. I det här fallet ska Rabatt flyttas till en annan tabell som har SRP-tangenten som nyckel.









