
В тази статия е описан синтаксисът и употребата на функцията LINEST в Microsoft Excel.
Описание
Функцията LINEST изчислява статистиките за линия с помощта на метода на най-малките квадрати, за да намери правата линия, която най-добре се съгласува с вашите данни, и връща масив, който описва линията. Освен това можете да комбинирате LINEST с други функции, за да изчислите статистиката за други типове модели, които са линейни при неизвестните параметри, включително полиномни, логаритмични, експоненциални и на степенни редове. Тъй като тази функция връща масив от стойности, тя трябва да бъде въведена като формула за масив. Инструкциите са по реда на примерите в тази статия.
Уравнението за линията е:
y = mx + b
–или–
y = m1x1 + m2x2 + ... + b
ако има множество диапазони от x-стойности, където зависимите стойности на y са функция на независимите стойности на x. Стойностите m са коефициенти, съответстващи на всяка стойност на x, а b е константа. Забележете, че y, x и m могат да са вектори. Масивът, който функцията LINEST връща, е {mn,mn-1,...,m1,b}. LINEST може да върне и допълнителни регресионни статистики.
Синтаксис
LINEST(известни_y; [известни_x]; [конст]; [състояния])
Синтаксисът на функцията LINEST има следните аргументи:
Синтаксис
-
известни_y Задължително. Наборът от стойности на y в отношението y = mx + b, които вече знаете.
-
Ако диапазонът на известни_y е в една колона, всяка колона от известни_x се разглежда като отделна променлива.
-
Ако диапазонът на известни_y се съдържа в един ред, всеки ред на известни_x се разглежда като отделна променлива.
-
-
известни_x Незадължително. Набор от стойности на x в отношението y = mx + b, които вече знаете.
-
Диапазонът известни_x може да включва един или повече набори от променливи. Ако се използва само една променлива, известни_y и известни_x могат да бъдат диапазони с произволна форма, стига да имат еднакви размерности. Ако се използва повече от една променлива, известни_y трябва да бъде вектор (т. е. диапазон с височина от един ред или ширина от един колона).
-
Ако известни_x е пропуснато, вместо него се използва масивът {1,2,3,...} със същия размер като известни_y.
-
-
конст Незадължително. Логическа стойност, задаваща дали константата b да се изравни на 0.
-
Ако конст е TRUE или е пропуснато, b се изчислява нормално.
-
Ако конст е FALSE, b се задава равно на 0 и m-стойностите се нагласяват така, че да се съгласуват с y = mx.
-
-
състояния Незадължително. Логическа стойност, задаваща дали да се върнат допълнителни регресионни статистики.
-
Ако статистика е TRUE, LINEST връща допълнителните регресионни статистики; в резултат на това върнатият масив е {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Ако състояния е FALSE или пропуснат, LINEST връща само коефициентите m и константата b.
Допълнителните регресионни статистики са като следва.
-
|
Статистика |
Описание |
|---|---|
|
se1,se2,...,sen |
Стойности на стандартните грешки за коефициентите m1,m2,...,mn. |
|
seb |
Стойност на стандартната грешка за константата b (seb = #N/A, когато конст е FALSE). |
|
r2 |
Коефициентът на определяне. Сравнява приблизителните и действителните стойности на y и диапазоните в стойност от 0 до 1. Ако то е 1, в извадката има перфектна корелация – няма разлика между приблизителната стойност на y и действителната стойност на y. В другата крайност, ако коефициентът на определяне е 0, регресионното уравнение не е полезно при прогнозирането на стойност на y. За информация как се изчислява2 , вижте "Забележки" по-нататък в тази тема. |
|
sey |
Стандартната грешка за оценката за y. |
|
F |
F статистиката, или наблюдаваната F стойност. Използвайте F статистиката, за да определите дали наблюдаваното отношение между зависимите и независимите променливи е получено случайно. |
|
df |
Степените на свобода. Използвайте степените на свобода, за да намерите F-критични стойности в статистическа таблица. Сравнете стойностите, които намирате в таблицата, с F статистиката, върната от LINEST , за да определите доверителното ниво за модела. За информация как се изчислява df вижте "Забележки" по-нататък в тази тема. Пример 4 показва използването на F и df. |
|
ssreg |
Сумата от квадратите за регресията. |
|
ssresid |
Остатъчната сума от квадрати. За информация как се изчисляват ssreg и ssresid, вижте "Забележки" по-нататък в тази тема. |
Следващата илюстрация показва реда, в който се връщат допълнителните регресионни статистики.

Забележки
-
Всяка права линия може да се опише с наклона й и точката, в която пресича оста y:
Наклон (m):
За да намерите наклона на линия, често написан като m, вземете две точки от линията, (x1,y1) и (x2,y2); наклонът е равен на (y2 - y1)/(x2 - x1).Пресечна точка с Y (b):
Пресечната точка y на линия, често написана като b, е стойността на y в точката, където линията пресича оста y.Уравнението на права линия е y = mx + b. След като знаете стойностите на m и b, можете да изчислите всяка точка от линията, като поставите в това уравнение стойността на y или x. Можете също да използвате функцията TREND.
-
Когато имате само една независима променлива x, можете да получите стойностите на наклона и пресечната точка директно с помощта на следните формули:
Наклон:
=INDEX(LINEST(known_y;known_x);1)Пресечна точка с Y:
=INDEX(LINEST(known_y;known_x);2) -
Точността на изчислената с LINEST линия зависи от степента на разсейване във вашите данни. Колкото по-линейни са данните, толкова по-точен е моделът LINEST . LINEST използва метода на най-малките квадрати, за да определи най-доброто съгласуване с данните. Когато имате само една независима променлива x, изчисленията за m и b се основават на следните формули:
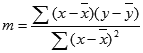
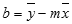
където x и y са средни стойности, т. е. x = AVERAGE(известни_x) и y = AVERAGE(известни_y).
-
Функциите за линейна и крива LINEST и LOGEST могат да изчислят най-добрата права линия или експоненциална крива, която отговаря на вашите данни. Трябва обаче да решите кой от двата резултата най-добре отговаря на вашите данни. Можете да изчислите TREND(known_y;known_x) за права линия или GROWTH(known_y, known_x) за експоненциална крива. Тези функции, без аргумента на new_x , връщат масив от стойности на y, прогнозирани по тази линия или крива в действителните точки от данни. След това можете да сравните прогнозираните стойности с действителните стойности. Може да искате да ги начертаете и двете за визуално сравнение.
-
В регресионния анализ Excel изчислява за всяка точка повдигнатата на квадрат разлика между стойността на y, оценена за тази точка, и действителната стойност на y. Сумата на тези повдигнати на квадрат разлики се нарича остатъчна сума от квадрати, ssresid. След това Excel изчислява общата сума от квадрати, sstotal. Когато аргументът конст = TRUE или е пропусната, общата сума от квадрати е сумата на повдигнатите на квадрат разлики между действителните стойности на y и средната стойност на отделните стойности на y. Когато аргументът конст = FALSE, общата сума от квадрати е сумата на квадратите на действителните стойности на y (без да се изважда средната стойност на y от всяка отделна стойност на y). Тогава може да се намери регресионната сума от квадрати, ssreg, като: ssreg = sstotal – ssresid. Колкото по-малка е остатъчната сума от квадрати в сравнение с общата сума от квадрати, толкова по-голяма е стойността на коефициента на определяне r2, което е индикатор за това колко добре уравнението, получено от регресионния анализ, обяснява отношението между променливите. Стойността на r2 е равна на ssreg/sstotal.
-
В някои случаи една или повече от X колоните (предполагат, че Y и X са в колони) може да нямат допълнителна прогнозна стойност в присъствието на другите X колони. С други думи премахването на една или повече X колони може да доведе до прогнозирани стойности на Y, които са еднакво точни. В този случай тези излишни X колони трябва да бъдат пропуснати от регресионния модел. Това явление се нарича "колинеарност", тъй като всяка излишна колона X може да се изразява като сума от кратни на несъкратните X колони. Функцията LINEST проверява за колинеарност и премахва излишните X колони от регресионния модел, когато ги идентифицира. Премахнатите X колони могат да се разпознаят в изходния LINEST като имащи коефициенти 0 в допълнение към стойностите 0 se. Ако една или повече колони бъдат премахнати като излишни, df е засегнато, защото df зависи от броя на колоните за X, които действително се използват за предвиждащи цели. За подробности относно изчисляването на df вж. пример 4. Ако df е променено, защото излишните X колони се премахват, стойностите на sey и F също са засегнати. Колинеарността трябва да бъде относително рядка на практика. Обаче един случай, в който е по-вероятно да възникнат, е когато някои X колони съдържат само 0 и 1 стойности като индикатори дали обект в експеримент е член на определена група или не. Ако конст = TRUE или е пропуснато, функцията LINEST ефективно вмъква допълнителна колона X от всички 1 стойности, за да моделира пресечната точка. Ако имате колона с 1 за всеки обект, ако е мъж, или 0, ако не, и имате колона с по 1 за всеки обект, ако е жена, или 0, ако не, втората колона е излишна, защото записите в нея могат да бъдат получени от изваждането на записа в колоната "индикатор за мъже" от записа в допълнителната колона на всички 1 стойности, добавени от функцията LINEST .
-
Когато от модела не са премахнати колони за X поради колинеарност, стойността на df се изчислява по следния начин: ако има k колони от известни_x и конст = TRUE или е пропуснато, df = n – k – 1. Ако конст = FALSE, df = n – k. И в двата случая всяка колона за X, премахната поради колинеарност, увеличава стойността на df с 1.
-
Когато въвеждате като аргумент масив от константи (като известни_x), използвайте запетаи за отделяне на стойностите, съдържащи се в един и същ ред, и точка и запетая за отделяне на различните редове. Разделителните знаци могат да се различават, в зависимост от вашите регионални настройки
-
Забележете, че стойностите на y, прогнозирани от регресионното уравнение, може да не са валидни, ако са извън диапазона на стойностите на y, който сте използвали, за да дефинирате уравнението.
-
Алгоритъмът, на който се базира функцията LINEST, е различен от този, който се използва във функциите SLOPE и INTERCEPT. Разликата в тези алгоритми може да доведе до различни резултати, когато данните са неопределени и колинеарни. Ако например точките на данните на аргумента известни_y са 0 и точките за данни на аргумента известни_x са 1:
-
LINEST връща стойност 0. Алгоритъмът на функцията LINEST е проектиран да връща смислени резултати за колинеарни данни и в този случай може да се намери поне един отговор.
-
SLOPE и INTERCEPT връщат #DIV/0! грешка. Алгоритъмът на функциите SLOPE и INTERCEPT е проектиран да търси само един отговор и в този случай може да има повече от един отговор.
-
-
В допълнение към използването на LOGEST за пресмятане на статистики за други типове регресии, можете да използвате LINEST, за да пресмятате диапазон на други типове регресии, въвеждайки променливите x и y като x и y серии за LINEST. Например формулата:
=LINEST(yстойности, xстойности^COLUMN($A:$C))
работи, когато имате единична колона от y-стойности и единични колона от x-стойности, за да изчислите кубично (полином от трета степен) приближение в следната форма:
y = m1*x + m2*x^2 + m3*x^3 + b
Можете да настроите тази формула за да изчислява други типове регресии, но в някои случаи тя изисква настройка на изходящите стойности и други статистики.
-
Стойността на F-теста, която е върната от функцията LINEST се различава от стойността на F-теста, връщана от функцията FTEST. LINEST връща F статистика, докато FTEST връща вероятността.
Примери
Пример 1 – Наклон и пресечна точка с оста Y
Копирайте примерните данни в следващата таблица и ги поставете в клетка A1 на нов работен лист на Excel. За да покажат резултати формулите, изберете ги, натиснете клавиша F2 и след това натиснете клавиша Enter. Ако е необходимо, коригирайте ширините на колоните, за да видите всичките данни.
|
Известни y |
Известни x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Резултат (с наклон) |
Резултат (прихванати y) |
|
2 |
1 |
|
Формула (формула за масив в клетки A7:B7) |
|
|
=LINEST(A2:A5;B2:B5;;FALSE) |
Пример 2 – Проста линейна регресия
Копирайте примерните данни в следващата таблица и ги поставете в клетка A1 на нов работен лист на Excel. За да покажат резултати формулите, изберете ги, натиснете клавиша F2 и след това натиснете клавиша Enter. Ако е необходимо, коригирайте ширините на колоните, за да видите всичките данни.
|
Месец |
Продажби |
|---|---|
|
1 |
3100 лв. |
|
2 |
4500 лв. |
|
3 |
4400 лв. |
|
4 |
5400 лв. |
|
5 |
7500 лв. |
|
6 |
8100 лв. |
|
Формула |
Резултат |
|
=SUM(LINEST(B1:B6; A1:A6)*{9;1}) |
11 000 лв. |
|
Изчислява оценката на продажбите през деветия месец на базата на продажбите за месеците от 1 до 6. |
Пример 3 – Множествена линейна регресия
Копирайте примерните данни в следващата таблица и ги поставете в клетка A1 на нов работен лист на Excel. За да покажат резултати формулите, изберете ги, натиснете клавиша F2 и след това натиснете клавиша Enter. Ако е необходимо, коригирайте ширините на колоните, за да видите всичките данни.
|
Застроена площ (x1) |
Офиси (x2) |
Входове (x3) |
Възраст (x4) |
Оценена стойност (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142 000 лв. |
|
2333 |
2 |
2 |
12 |
144 000 лв. |
|
2356 |
3 |
1.5 |
33 |
151 000 лв. |
|
2379 |
3 |
2 |
43 |
150 000 лв. |
|
2402 |
2 |
3 |
53 |
139 000 лв. |
|
2425 |
4 |
2 |
23 |
169 000 лв. |
|
2448 |
2 |
1.5 |
99 |
126 000 лв. |
|
2471 |
2 |
2 |
34 |
142 900 лв. |
|
2494 |
3 |
3 |
23 |
163 000 лв. |
|
2517 |
4 |
4 |
55 |
169 000 лв. |
|
2540 |
2 |
3 |
22 |
149 000 лв. |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Формула (формула за динамичен масив, въведена в A19) |
||||
|
=LINEST(E2:E12;A2:D12;TRUE;TRUE) |
Пример 4 – Използване на статистиката F и r2
В предишния пример коефициентът на определяне, или r2, е 0,99675 (вж. клетка A17 в резултата за LINEST), който показва силна връзка между независимите променливи и продажната цена. Можете да използвате F статистиката, за да определите дали тези резултати, с такава висока стойност на r2, са възникнали случайно.
Да допуснем за момент, че всъщност няма връзка между променливите, а просто сте попаднали случайно на една рядка извадка от 11 сгради, за която статистическият анализ показва силна връзка. Терминът "алфа" се използва за вероятността да се направи погрешен извод, че връзка съществува.
Стойностите F и df в резултата от функцията LINEST могат да се използват за оценяване на вероятността от по-висока F стойност, появяваща се случайно. F може да се сравнява с критични стойности в публикувани F-таблици за разпределение или функцията FDIST в Excel може да се използва за изчисляване на вероятността по-голяма F стойност да възникне случайно. Подходящото F разпределение има степени на свобода v1 и v2. Ако n е броят на точките от данни и конст = TRUE или пропуснато, тогава v1 = n – df – 1 и v2 = df. (Ако конст = FALSE, тогава v1 = n – df и v2 = df.) FDIST функцията – със синтаксиса FDIST(F,v1,v2) – ще върне вероятността за случайно появяване на по-висока F стойност. В този пример df = 6 (клетка B18) и F = 459,753674 (клетка A18).
Ако допуснем алфа стойност от 0,05, v1 = 11 – 6 – 1 = 4 и v2 = 6, критичното ниво на F е 4,53. Тъй като F = 459,753674 е много по-висока от 4,53, изключително малко вероятно е такава стойност F да е възникнала случайно. (При алфа = 0,05 хипотезата, че няма отношение между known_y и known_x трябва да се отхвърли, когато F надхвърли критичното ниво, 4,53.) Можете да използвате функцията FDIST в Excel, за да получите вероятността такава висока стойност да е възникнала случайно. Например FDIST(459,753674, 4; 6) = 1,37E-7 – изключително малка вероятност. Можете да заключите, като намерите критичното ниво на F в таблица или като използвате функцията FDIST , че регресионното уравнение е полезно при прогнозирането на оценената стойност на сградите в тази област. Не забравяйте, че е изключително важно да се използват правилните стойности на v1 и v2, които са изчислени в предишния параграф.
Пример – Изчисляване на t-статистика
Друг тест за проверка на хипотези ще определи дали всеки коефициент е полезен за оценка на стойността на сградите от пример 3. Например за да се проверите статистическата значимост на коефициента за възраст, разделете -234,24 (коефициента за възраст) на 13,268 (оценената стандартна грешка за коефициента за възраст в клетка A15). Стойността на t за наблюденията е:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Ако абсолютната стойност на t е достатъчно висока, може да бъде направен изводът, че коефициентът е полезен за намирането на оценената стойност на сградите в пример 3. Таблицата по-долу показва абсолютните стойности на t за четирите наблюдавани стойности.
Ако направите ръчно проверка в статистически справочник, ще намерите, че критичната стойност за t при двустранно разпределение с 6 степени на свобода и алфа = 0,05 е 2,447. Тази критична стойност може да бъде намерена и с помощта на функцията TINV. TINV(0,05,6) = 2,447. Тъй като абсолютната стойност на t (17,7), е по-голяма от 2,447, възрастта е важна променлива при оценката на стойността на сградите с офиси. По подобен начин може да се направи проверка за статистическата значимост на всяка от другите независими променливи. По-долу са показани стойностите на t за всяка от независимите променливи.
|
Променлива |
t стойност |
|---|---|
|
Застроена площ |
5,1 |
|
Брой офиси |
31,3 |
|
Брой входове |
4,8 |
|
Възраст |
17,7 |
Всички тези величини имат абсолютна стойност над 2,447; следователно всички променливи, използвани в регресионното уравнение, са полезни за прогнозирането на оценената стойност на офисите в района.









