La fonction GROUPBY vous permet de créer un résumé de vos données via une formule. Il prend en charge le regroupement le long d’un axe et l’agrégation des valeurs associées. Par instance, si vous disposiez d’une table de données de ventes, vous pouvez générer un résumé des ventes par année.
Syntaxe
La fonction GROUPBY vous permet de regrouper, d’agréger, de trier et de filtrer des données en fonction des champs que vous spécifiez.
La syntaxe de la fonction PIVOTBY est la suivante :
GROUPBY(row_fields,values,function,[field_headers],[total_depth],[sort_order],[filter_array])
|
Argument |
Description |
|---|---|
|
row_fields (obligatoire) |
Tableau ou plage orienté colonne qui contient les valeurs utilisées pour regrouper les lignes et générer des en-têtes de ligne. Le tableau ou la plage peut contenir plusieurs colonnes. Si c’est le cas, la sortie aura plusieurs niveaux de groupe de lignes. |
|
valeurs (obligatoire) |
Tableau ou plage orienté colonne des données à agréger. Le tableau ou la plage peut contenir plusieurs colonnes. Si c’est le cas, la sortie aura plusieurs agrégations. |
|
fonction (obligatoire) |
Lambda réduite explicite ou eta (SUM, PERCENTOF, AVERAGE, COUNT, etc.) utilisée pour agréger des valeurs. Un vecteur de lambdas peut être fourni. Si c’est le cas, la sortie aura plusieurs agrégations. L’orientation du vecteur détermine s’il est disposé au niveau des lignes ou des colonnes. |
|
field_headers |
Nombre qui spécifie si les row_fields et les valeurs ont des en-têtes et si les en-têtes de champ doivent être retournés dans les résultats. Les valeurs possibles sont les suivantes :
Manquant : automatique. Remarque : Automatique suppose que les données contiennent des en-têtes basés sur l’argument valeurs. Si la 1ère valeur est du texte et que la 2e valeur est un nombre, les données sont supposées avoir des en-têtes. Les en-têtes de champs sont affichés s’il existe plusieurs niveaux de groupe de lignes ou de colonnes. |
|
total_depth |
Détermine si les en-têtes de ligne doivent contenir des totaux. Les valeurs possibles sont les suivantes :
Manquant : Automatique : totaux généraux et, si possible, sous-totaux. Remarque : Pour les sous-totaux, les champs doivent avoir au moins 2 colonnes. Les nombres supérieurs à 2 sont pris en charge, à condition que le champ comporte suffisamment de colonnes. |
|
sort_order |
Nombre indiquant la façon dont les lignes doivent être triées. Les nombres correspondent aux colonnes dans row_fields suivis des colonnes dans les valeurs. Si le nombre est négatif, les lignes sont triées dans l’ordre décroissant/inverse. Un vecteur de nombres peut être fourni lors du tri basé uniquement sur row_fields. |
|
filter_array |
Tableau 1D orienté colonne de booléens qui indiquent si la ligne de données correspondante doit être prise en compte. Remarque : La longueur du tableau doit correspondre à celle fournie à row_fields. |
Exemples
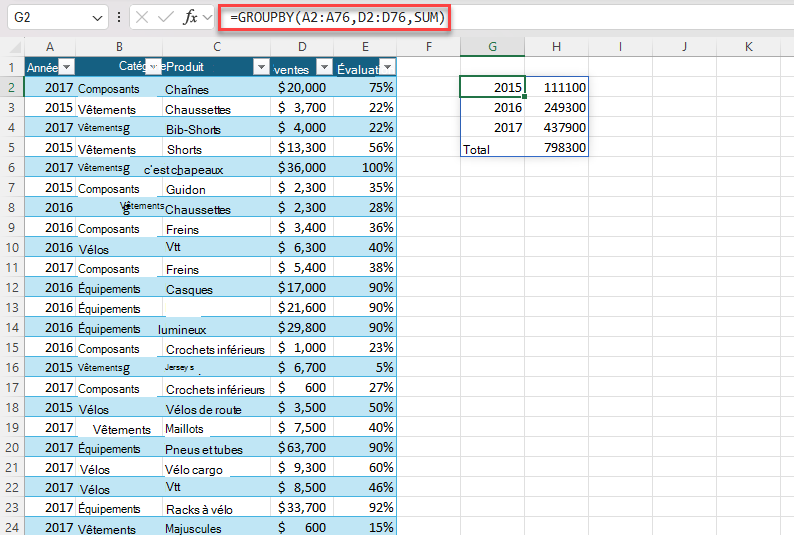
Exemple 1 : utilisez GROUPBY pour générer un résumé des ventes totales par année.
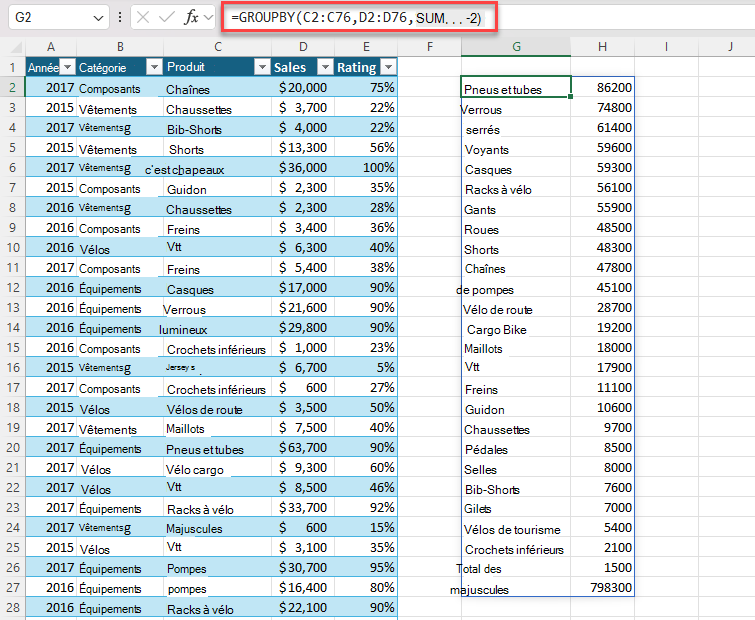
Exemple 2 : utilisez GROUPBY pour générer un résumé des ventes totales par produit. Tri décroissant par ventes.