
U ovom se članku opisuje sintaksa formula i korištenje funkcije LINEST u programu Microsoft Excel.
Opis
Funkcija LINEST izračunava statistiku za pravac korištenjem metode "najmanji kvadrati" za izračun ravnog pravca koji najbolje odgovara vašim podacima, a potom vraća polje koje opisuje taj pravac. Također možete kombinirati funkciju LINEST s drugim funkcijama da biste izračunali statistiku za druge vrste modela koji su linearni s nepoznatim parametrima, uključujući serije polinoma, logaritamske, eksponencijalne i potencijske serije. Budući da ova funkcija vraća polje vrijednosti, potrebno ju je unijeti kao formulu polja. Upute slijede primjere u ovom članku.
Jednadžba pravca je:
y = mx + b
– ili –
y = m1x1 + m2x2 + ... + b
ako postoji više raspona vrijednosti x, pri čemu su zavisne vrijednosti y funkcija nezavisnih vrijednosti x. Vrijednosti m koeficijenti su koji odgovaraju svakoj vrijednosti x, a b je konstantna vrijednost. Upamtite da y,x i m mogu biti vektori. Polje koje vraća funkcija LINEST je {mn;mn-1;...;m1;b}. LINEST također može vratiti dodatne regresijske statistike.
Sintaksa
LINEST(poznati_y; [poznati_x]; [konst]; [stat])
Sintaksa funkcije LINEST sadrži sljedeće argumente:
Sintaksa
-
poznati_y Obavezno. Skup vrijednosti y koje su vam već poznate u odnosu y = mx + b.
-
Ako je raspon poznati_y u jednom stupcu, svaki stupac u skupu poznati_x tumači se kao zasebna varijabla.
-
Ako je raspon skupa poznati_y sadržan u jednom retku, svaki redak skupa poznati_x tumači se kao zasebna varijabla.
-
-
poznati_x Obavezno. Skup vrijednosti x koje su vam već poznate u odnosu y = mx + b.
-
Raspon poznati_x može obuhvaćati jedan ili više skupova varijabli. Ako se koristi samo jedna varijabla, poznati_y i poznati_x mogu biti rasponi bilo kojeg oblika, tako dugo dok su im dimenzije jednake. Ako se koristi više od jedne varijable, poznati_y mora biti vektor (odnosno raspon s visinom jednog retka ili širinom jednog stupca).
-
Ako se poznati_x izostavi, pretpostavlja se da je riječ o polju {1,2,3,...} iste veličine kao i poznati_y.
-
-
konst Dodatno. Logička vrijednosti koja određuje hoće li konstanta b biti jednaka 0.
-
Ako je vrijednost konstTRUE ili je izostavljena, b se izračunava normalnim putem.
-
Ako je vrijednost konst je FALSE, određuje se da je b jednak 0, a vrijednosti m prilagođavaju se da bi odgovarale y = mx.
-
-
stat Dodatno. Logička vrijednost koja određuje hoće li biti vraćene i dodatne statistike regresije.
-
Ako je statistika TRUE, LINEST vraća dodatne statistike regresije; kao rezultat toga, vraćeno polje je {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Ako je stat FALSE ili je izostavljen, LINEST vraća samo m-koeficijente i konstantu b.
Dodatni statistički podaci regresije su sljedeći.
-
|
Statistički podaci |
Opis |
|---|---|
|
se1;se2;...;sen |
Standardne vrijednosti pogreške za koeficijente m1,m2,...,mn. |
|
seb |
Standardna vrijednost pogreške za konstantu b (seb = #N/A kada je konstFALSE). |
|
r2 |
Koeficijent određivanja. Uspoređuje procijenjene i stvarne vrijednosti y te raspone u vrijednosti od 0 do 1. Ako je 1, u uzorku postoji savršena korelacija – nema razlike između procijenjene vrijednosti y i stvarne vrijednosti y. U drugom ekstremnom slučaju, ako je koeficijent određivanja 0, regresijski jednadžba nije korisna u predviđanju y-vrijednosti. Informacije o načinu izračunabroja 2 potražite u odjeljku "Napomene" u nastavku ove teme. |
|
sey |
Standardna pogreška za procijenjenu vrijednost y. |
|
F |
F statistika ili opažena F vrijednost. F statistiku koristite za određivanje je li opaženi odnos između zavisnih i nezavisnih varijabli slučajan. |
|
df |
Stupnjevi slobode. Koristite stupnjeve slobode da biste lakše pronašli kritične F vrijednosti u statističkoj tablici. Usporedite vrijednosti koje pronađete u tablici s F statistikom koju vraća funkcija LINEST da biste odredili razinu pouzdanosti modela. Dodatne informacije o izračunavanju varijable df potražite u odjeljku "Primjedbe" u nastavku ove teme. U primjeru 4 prikazano je korištenje varijabli F i df. |
|
ssreg |
Regresijski zbroj kvadrata. |
|
ssresid |
Rezidualni zbroj kvadrata. Informacije o izračunavanju varijabli ssreg i ssresid potražite u odjeljku "Primjedbe" u nastavku ove teme. |
Sljedeća ilustracija prikazuje redoslijed kojim se vraćaju dodatni statistički podaci.

Primjedbe
-
Bilo koji pravac možete opisati pomoću nagiba i sjecišta osi y.
Nagib (m):
Da biste pronašli nagib crte, često napisan kao m, uzeti dvije točke na liniji, (x1,y1) i (x2,y2); nagib je jednak (y2 - y1)/(x2 - x1).Y-intercept (b):
y-intercept of a line, often written as b, is the value of y at the point where the line crosses the y-axis.Jednadžba pravca je y = mx + b. Kada su vam poznate vrijednosti m i b, možete izračunati bilo koju točku na pravcu tako da u jednadžbu uvrstite vrijednost y ili vrijednost x. Također možete koristiti funkciju TREND.
-
Kad imate samo jednu nezavisnu varijablu x, nagib (m) i sjecište osi y (b) možete odrediti pomoću sljedećih formula:
Nagib:
=INDEX(LINEST(known_y's;known_x's);1)Presretanje osi Y:
=INDEX(LINEST(known_y;known_x 2) -
Točnost pravca izračunatog pomoću funkcije LINEST ovisi o stupnju raspršenosti podataka. Što su podaci linearniji, to je model LINEST točniji. LINEST koristi metodu najmanjih kvadrata za izračunavanje pravca koji najbolje odgovara podacima. Ako imate samo jednu neovisnu varijablu x, izračuni za m i b temelje se na sljedećim formulama:
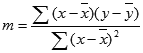
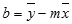
pri čemu su x i y aritmetičke sredine uzorka, odnosno x = AVERAGE(poznati_ x) i y = AVERAGE(poznati_y).
-
Funkcije line-and curve-fitting LINEST i LOGEST mogu izračunati najbolju ravnu ili eksponencijalnu krivulju koja odgovara vašim podacima. No morate odlučiti koji od ta dva rezultata najbolje odgovara vašim podacima. Možete izračunati TREND(known_y,known_x) za ravnu crtu ili GROWTH(known_y, known_x) za eksponencijalnu krivulju. Te funkcije, bez new_x argumenta, vraćaju polje vrijednosti y predviđenih duž te crte ili krivulje na stvarnim točkama podataka. Zatim možete usporediti predviđene vrijednosti sa stvarnim vrijednostima. Možda ćete ih htjeti obojiti grafikonom radi vizualne usporedbe.
-
U regresijskoj analizi Excel za svaku točku izračunava kvadrat razlike između vrijednosti y procijenjene za tu točku i njezine stvarne vrijednosti y. Zbroj kvadrata tih razlika naziva se rezidualnim zbrojem kvadrata, odnosno ssresid. Excel tada izračunava ukupni zbroj kvadrata, odnosno sstotal. Kada je argument konst = TRUE ili je izostavljen, ukupni zbroj kvadrata zbroj je kvadrata razlika između stvarnih vrijednost y i prosjeka vrijednosti y. Kada je argument konst = FALSE, ukupni zbroj kvadrata je zbroj kvadrata stvarnih vrijednosti y (bez oduzimanja prosječne vrijednosti y od svake pojedine vrijednosti y). Regresijski zbroj kvadrata, ssreg, moguće je dobiti iz jednadžbe ssreg = sstotal - ssresid. Što je rezidualni zbroj kvadrata manji, u usporedbi s ukupnim zbrojem kvadrata, to je veća vrijednost koeficijenta određivanja, r2, što je pokazatelj koliko dobro jednadžba koja proizlazi iz regresijske analize objašnjava odnos među varijablama. Vrijednost r2 jednaka je ssreg/sstotal.
-
U nekim slučajevima jedan ili više stupaca X (pretpostavljaju da su Y i X u stupcima) možda neće imati dodatne predvidljive vrijednosti u prisutnosti drugih stupaca X. Drugim riječima, uklanjanje jednog ili više X stupaca može dovesti do predviđenih vrijednosti Y koje su jednako točne. U tom slučaju ti redundantni X stupci moraju biti izostavljena iz modela regresije. Taj se fenomen naziva "kolinearnost" jer se bilo koji redundantni stupac X može izraziti kao zbroj višestrukih stupaca X koji nisu suvišni. Funkcija LINEST provjerava kolinearnost i uklanja sve suvišne stupce X iz modela regresije kada ih prepozna. Uklonjeni stupci X mogu se prepoznati u izlazu FUNKCIJE LINEST kao da imaju 0 koeficijenta uz 0 se vrijednosti. Ako se jedan ili više stupaca ukloni kao suvišan, to utječe na df jer df ovisi o broju stupaca X koji se zapravo koriste u predviđene svrhe. Pojedinosti o izračunu df potražite u 4. primjeru. Ako se df promijeni jer se uklanjaju redundantni X stupci, to utječe i na vrijednosti sey i F. Kolinearnost bi trebala biti relativno rijetka u praksi. Međutim, jedan je slučaj u kojem je vjerojatnije da će se pojaviti kada neki stupci X sadrže samo vrijednosti 0 i 1 kao pokazatelje je li predmet u eksperimentu član određene grupe ili nije. Ako je konst = TRUE ili je izostavljen, funkcija LINEST zapravo umeće dodatni stupac X od svih 1 vrijednosti da bi modelirala sjecište. Ako imate stupac s 1 za svaki predmet ako je muškarac ili 0, a imate i stupac s 1 za svaki predmet ako je ženski ili 0 ako nije, taj je potonji stupac suvišan jer se unosi u njemu mogu dobiti oduzimanjem unosa u stupcu "muški pokazatelj" od unosa u dodatni stupac svih 1 vrijednosti koje je dodala funkcija LINEST .
-
Vrijednost df izračunava se kako slijedi ako se stupci X ne uklanjanju iz modela zbog kolinearnosti: ako postoje stupci k s varijablama poznati_x i konst = TRUE ili izostavljen, df = n – k – 1. Ako je konst = FALSE, df = n - k. U oba slučaja, svaki stupac X koji je uklonjen zbog kolinearnosti povećava vrijednost varijable df za 1.
-
Pri unosu konstante polja (primjerice poznati_x) kao argumenta, koristite zareze da biste odvojili vrijednosti sadržane u istom redu i točke sa zarezom da biste odvojili retke. Znakovi razdjelnika ovise o regionalnim postavkama.
-
Primijetite da vrijednosti y predviđene jednadžbom regresije ne moraju biti valjane ako su izvan raspona vrijednosti y upotrijebljenih prilikom definiranja jednadžbe.
-
Algoritam u osnovi funkcije LINEST razlikuje se od algoritma koji se koristi za funkcije SLOPE i INTERCEPT. Razlika između ovih algoritama može dovesti do različitih rezultata ako su podaci neodređeni i kolinearni. Ako su, primjerice, točke podataka argumenta poznati_y 0 te ako su točke podataka argumenta poznati_x 1:
-
LINEST vraća vrijednost 0. Algoritam funkcije LINEST dizajniran je za vraćanje razumnih rezultata za kolinearne podatke te je, u ovom slučaju, moguće pronaći barem jedan odgovor.
-
SLOPE i INTERCEPT vraćaju #DIV/0! pogreška. Algoritam funkcija SLOPE i INTERCEPT osmišljen je tako da potraži samo jedan odgovor, a u ovom slučaju može biti više odgovora.
-
-
Osim korištenja funkcije LOGEST za izračun statistike za druge vrste regresije, možete koristiti funkciju LINEST za izračun raspona drugih vrsta regresije unosom funkcija varijabli x i y kao nizova x i y za funkciju LINEST. Primjerice, sljedeća formula:
=LINEST(yvrijednosti; xvrijednosti^COLUMN($A:$C))
funkcionira kad imate jedan stupac vrijednosti y i jedan stupac vrijednosti x za izračun kubne (polinom 3. reda) aproksimacije oblika:
y = m1*x + m2*x^2 + m3*x^3 + b
Ovu formulu možete prilagoditi za izračun drugih vrsta regresije, ali u nekim slučajevima bit će potrebno usklađivanje izlaznih vrijednosti i ostalih statističkih podataka.
-
Vrijednost F-testa koju vraća funkcija LINEST razlikuje se od vrijednosti F-testa koju vraća funkcija FTEST. LINEST vraća F statistiku, a FTEST vjerojatnost.
Primjeri
Prvi primjer – nagib i sjecište osi y
Ogledne podatke kopirajte u sljedeću tablicu i zalijepite ih u ćeliju A1 novog radnog lista programa Excel. Da biste koristili formule za prikaz rezultata, odaberite ih pa pritisnite tipku F2, a zatim Enter. Ako je potrebno, prilagodite širine stupaca da biste vidjeli sve podatke.
|
Poznati y |
Poznati x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Rezultat (nagib) |
Rezultat (sjecište osi y) |
|
2 |
1 |
|
Formula (formula polja u ćelijama A7:B7) |
|
|
=LINEST(A2:A5;B2:B5;;FALSE) |
Drugi primjer – jednostavna linearna regresija
Ogledne podatke kopirajte u sljedeću tablicu i zalijepite ih u ćeliju A1 novog radnog lista programa Excel. Da biste koristili formule za prikaz rezultata, odaberite ih pa pritisnite tipku F2, a zatim Enter. Ako je potrebno, prilagodite širine stupaca da biste vidjeli sve podatke.
|
Mjesec |
Prodaja |
|---|---|
|
1 |
15.500 kn |
|
2 |
22.500 kn |
|
3 |
22.000 kn |
|
4 |
27.000 kn |
|
5 |
37.500 kn |
|
6 |
40.500 kn |
|
Formula |
Rezultat |
|
=SUM(LINEST(B1:B6; A1:A6)*{9,1}) |
55 000 kn |
|
Izračunava procjenu prodaje u devetom mjesecu na temelju prodaje od prvog do šestog mjeseca. |
Treći primjer – višestruka linearna regresija
Ogledne podatke kopirajte u sljedeću tablicu i zalijepite ih u ćeliju A1 novog radnog lista programa Excel. Da biste koristili formule za prikaz rezultata, odaberite ih pa pritisnite tipku F2, a zatim Enter. Ako je potrebno, prilagodite širine stupaca da biste vidjeli sve podatke.
|
Površina kata (x1) |
Uredi (x2) |
Ulazi (x3) |
Starost (x4) |
Procijenjena vrijednost (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
710 000 kn |
|
2333 |
2 |
2 |
12 |
720 000 kn |
|
2356 |
3 |
1,5 |
33 |
755 000 kn |
|
2379 |
3 |
2 |
43 |
750 000 kn |
|
2402 |
2 |
3 |
53 |
695 000 kn |
|
2425 |
4 |
2 |
23 |
845 000 kn |
|
2448 |
2 |
1,5 |
99 |
630 000 kn |
|
2471 |
2 |
2 |
34 |
714 500 kn |
|
2494 |
3 |
3 |
23 |
815 000 |
|
2517 |
4 |
4 |
55 |
845 000 kn |
|
2540 |
2 |
3 |
22 |
745 000 kn |
|
- 234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formula (formula dinamičkog polja unesena u ćeliju A19) |
||||
|
=LINEST(E2:E12;A2:D12;TRUE;TRUE) |
Četvrti primjer – korištenje statistike F i r2
U prethodnom je primjeru koeficijent određivanja ili r2 0,99675 (vidi ćeliju A17 u rezultatu za LINEST), što bi naznačilo snažan odnos između nezavisnih varijabli i prodajne cijene. Možete koristiti statistiku F da biste odredili jesu li ti rezultati, s tako visokom vrijednošću r2, dobiveni slučajno.
Pretpostavimo na trenutak da nema povezanosti između varijabli, ali da imate rijedak uzorak od 11 poslovnih zgrada koji u statističkoj analizi pokazuje jaku povezanost. Izraz "Alfa" se koristi za vjerojatnost pogrešnog zaključka da postoji povezanost.
Vrijednosti F i df u izlazu iz funkcije LINEST mogu se koristiti za procjenu vjerojatnosti pojave veće F vrijednosti slučajno. F se može usporediti s kritičnim vrijednostima u objavljenim tablicama F-raspodjele ili funkciji FDIST u programu Excel može se koristiti za izračun vjerojatnosti veće F vrijednosti koja se pojavljuje slučajno. Odgovarajuća F raspodjela ima v1 i v2 stupnjeva slobode. Ako je n broj točaka podataka i konst = TRUE ili izostavljen, tada je v1 = n – df – 1 i v2 = df. (Ako je konst = FALSE, tada je v1 = n – df i v2 = df.) Funkcija FDIST – s sintaksom FDIST(F,v1,v2) vratit će vjerojatnost veće F vrijednosti koja se pojavljuje slučajno. U ovom primjeru df = 6 (ćelija B18) i F = 459,753674 (ćelija A18).
Uz pretpostavku alfa vrijednosti 0,05, v1 = 11 – 6 – 1 = 4 i v2 = 6, kritična razina F je 4,53. Budući da je F = 459,753674 mnogo veća od 4,53, malo je vjerojatno da je F vrijednost ova visoka dogodila slučajno. (Uz Alfa = 0,05, hipoteza da ne postoji odnos između known_y-a i known_x-a treba odbaciti kada F prekorači kritičnu razinu, 4,53.) Funkciju FDIST u programu Excel možete koristiti da biste dobili vjerojatnost da je F vrijednost ta visoka slučajno nastala. Na primjer, FDIST(459,753674, 4, 6) = 1,37E-7, vrlo mala vjerojatnost. Možete zaključiti, bilo pronalaženjem kritične razine F u tablici ili pomoću funkcije FDIST , da je regresijski jednadžba korisna u predviđanju procijenjene vrijednosti uredskih zgrada u ovom području. Imajte na umu da je ključno koristiti točne vrijednosti v1 i v2 koje su izračunate u prethodnom odlomku.
Peti primjer – izračun t-statistike
Drugom provjerom hipoteze odredit ćete je li svaki koeficijent nagiba koristan za određivanje procijenjene vrijednosti poslovne zgrade u primjeru 3. Da biste, primjerice, testirali statističku značajnost koeficijenta starosti, podijelite -234,24 (koeficijent nagiba dobi) s 13,268 (procijenjena standardna pogreška koeficijenata dobi u ćeliji A15). Opažena t-vrijednost iznosi:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Ako je apsolutna vrijednost t dovoljno visoka, moguće je zaključiti da je koeficijent nagiba koristan za određivanje procijenjene vrijednosti poslovne zgrade u primjeru 3. U sljedećoj tablici prikazane su apsolutne vrijednosti 4 opažene t vrijednosti.
Ako konzultirate tablicu u statističkom priručniku, vidjet ćete da je kritična t vrijednost s dva kraka i 6 stupnjeva slobode i vrijednošću Alfa = 0,05 jednaka 2,447. Tu kritičnu vrijednost možete pronaći i pomoću funkcije TINV u programu Excel. TINV(0.05,6) = 2,447. Budući da je apsolutna vrijednost t (17,7) veća od 2,447, dob je važna varijabla pri određivanju procijenjene vrijednosti poslovne zgrade. Na sličan način moguće je testirati statističku važnost svake od preostalih varijabli. U nastavku navodimo opažene t-vrijednosti za svaku nezavisnu varijablu.
|
Varijabla |
Opažena varijabla t |
|---|---|
|
Količina prostora |
5,1 |
|
Broj ureda |
31,3 |
|
Broj ulaza |
4,8 |
|
Starost |
17,7 |
Ove vrijednosti imaju apsolutnu vrijednost veću od 2,447, pa možemo zaključiti kako su sve varijable u regresijskoj jednadžbi korisne u predviđanju procijenjene vrijednosti poslovnih zgrada na tom području.









