
Az Excelben több millió sort tartalmazó adatmodelleket hozhat létre, majd hatékony adatelemzést végezhet ezeken a modelleken. Az adatmodellek a Power Pivot bővítménnyel és anélkül is létrehozhatók, így egy munkafüzetben tetszőleges számú kimutatást, diagramot és Power View nézetet tartalmazó megjelenítést támogatnak.
Habár az Excelben könnyedén hozhat létre hatalmas adatmodelleket, számos ok szól azért, mert ez nem lehetséges. Először is, a nagyméretű modellek, amelyek sok táblázatot és oszlopot tartalmaznak, a legtöbb elemzésnél túlzások, és nehézkessé teszik a mezőlistát. Másodszor, a nagy modellek értékes memóriát foglalnak el, ami negatívan befolyásolja azokat az alkalmazásokat és jelentéseket, amelyek ugyanazon rendszererőforrásokon osztoznak. Végezetül, a Microsoft 365-ben a SharePoint Online és az Excel Web App is 10 MB-ra korlátozza az Excel-fájlok méretét. A több millió sort tartalmazó munkafüzet adatmodelljei esetén hamar eléri a 10 MB-os korlátot. Lásd : Az adatmodell specifikációja és korlátai.
Ebből a cikkből megtudhatja, hogyan hozhat létre egy szorosan felépített, könnyebben használható és kevesebb memóriát használó modellt. Ha időt szán a hatékony modelltervezéssel kapcsolatos gyakorlati tanácsok elsajátítására, az bármilyen létrehozott és használt modell esetében megtérül, akár az Excelben, akár a Microsoft 365 SharePoint Online-ban, egy Office Web Apps Serveren vagy a SharePointban tekinti meg azt.
Érdemes lehet futtatni a Munkafüzetméret-optimalizálót is. A funkció elemzi az Excel-munkafüzetet, és ha lehetséges, tovább tömöríti. Töltse le a Munkafüzetméret-optimalizálót.
Tartalom
Semmi sem múlja felül egy nem létező oszlopot a kevés memóriahasználat esetén
Mi van, ha szükségünk van az oszlopra; Csökkenthetjük-e még a helyköltségét?
A tömörítési arányok és a memóriában működő elemzőmotor
Az Excel adatmodelljei a memórián belüli elemzési motor segítségével tárolják az adatokat a memóriában. A motor hatékony tömörítési technikákat alkalmaz a tárolási igények csökkentése érdekében, és az eredeti méretének töredékére zsugorítja az eredményhalmazt.
Átlagosan számíthat arra, hogy egy adatmodell 7–10-szer kisebb lesz a származási helyen érvényes ugyanezen adatoknál. Ha például 7 MB adatot importál egy SQL Server-adatbázisból, az adatmodell az Excelben könnyen 1 MB vagy annál kisebb is lehet. A ténylegesen elért tömörítési fok elsősorban az egyes oszlopokban lévő egyedi értékek számától függ. Minél több egyedi érték, annál több memóriára van szükség a tárolásukhoz.
Miért beszélünk tömörítésről és egyedi értékekről? Egy hatékony, a memóriahasználatot minimálisra csökkentő modell felépítése ugyanis a tömörítés maximalizálásáról szól, és ennek legegyszerűbb módja, ha megszabadul a szükségtelen oszlopoktól, különösen ha ezekben az oszlopokban sok egyedi érték található.
Megjegyzés
Az egyes oszlopok tárolási követelményei óriási különbségek lehetnek. Bizonyos esetekben célszerűbb több oszlopot használni, amelyekben kevés egyedi érték található, mint egy oszlop sok egyedi értékkel. A Datetime ciklus optimalizálásáról szóló rész részletesen ismerteti ezt a módszert.
Semmi sem múlja felül egy nem létező oszlopot a kevés memóriahasználat esetén
A legmemóriahatékonyabb oszlop az, amelyet eleve soha nem importált. Ha hatékony modellt szeretne felépíteni, az egyes oszlopokat áttekintve tegye fel a kérdést, hogy azok hozzájárulnak-e az elvégzendő elemzéshez. Ha nem, vagy nem biztos benne, hagyja ki. Később is bármikor felvehet új oszlopokat, ha szüksége van rájuk.
Két példa oszlopokra, amelyeket mindig ki kell hagyni
Az első példa egy adattárházból származó adatokra vonatkozik. Egy adattárházban gyakran találhatók olyan ETL-folyamatok összetevői, amelyek betöltik és frissítik az adatokat a raktárban. A "létrehozás dátuma", a "frissítés dátuma" és az "ETL-futtatás" oszlop az adatok betöltésekor jön létre. Ezekre az oszlopokra nincs szükség a modellben, és az adatok importálásakor el kell távolítani a jelölésüket.
A második példa az elsődleges kulcs oszlopának kihagyására vonatkozik egy ténytábla importálásakor.
Számos tábla, beleértve az adattáblákat is, rendelkezik elsődleges kulccsal. A legtöbb tábla, például az ügyfelek, alkalmazottak és értékesítések adatait tartalmazó táblák esetében meg kell adni a tábla elsődleges kulcsát, mert segítségével kapcsolatokat hozhat létre a modellben.
Az adattáblák eltérőek. A ténytáblákban az elsődleges kulcs határozza meg egyedileg az egyes sorokat. Bár normalizálási célokból szükséges, kevésbé hasznos olyan adatmodellekben, amelyekben csak ezeket az oszlopokat szeretné elemzésre vagy táblakapcsolatok létrehozására használni. Emiatt amikor ténytáblából importál egy elsődleges kulcsot, ne vegye fel az importálás elsődleges kulcsát. A ténytáblában szereplő elsődleges kulcsok óriási helyet foglalnak el a modellben, de nem nyújtanak előnyöket, mivel nem használhatók kapcsolatok létrehozására.
Megjegyzés
Az adattárakban és a többdimenziós adatbázisokban a többnyire numerikus adatokat tartalmazó nagy táblákat gyakran "ténytábláknak" nevezik. Az adattáblák általában üzleti teljesítmény- vagy tranzakciós adatokat, például értékesítési és költségadatokat tartalmaznak, amelyeket összesítve szervezeti egységekhez, termékekhez, piaci szegmensekhez, földrajzi régiókhoz stb. igazítunk. Az adatelemzés támogatása érdekében az adattábla összes olyan oszlopát, amely üzleti adatokat tartalmaz, vagy azokat, amelyek más táblákban tárolt adatokra kereszthivatkozásra használhatók, szerepeltetni kell a modellben. A kizárni kívánt oszlop a ténytábla elsődlegeskulcs-oszlopa, amely olyan egyedi értékekből áll, amelyek csak a ténytáblában léteznek, és máshol nem. Mivel a ténytáblák hatalmasak, a legnagyobb növekedést a modell hatékonyságában az adja, ha kizárja a sorokat vagy oszlopokat a ténytáblákból.
Felesleges oszlopok kizárása
A hatékony modellek csak azokat az oszlopokat tartalmazzák, amelyekre ténylegesen szüksége lesz a munkafüzetben. Ha szabályozni szeretné, hogy mely oszlopok szerepeljenek a modellben, az Excel "Adatimportálás" párbeszédpanelje helyett a Power Pivot bővítmény Tábla importálása varázslójával kell importálnia az adatokat .
A Tábla importálása varázsló elindításakor kiválaszthatja az importálni kívánt táblákat.
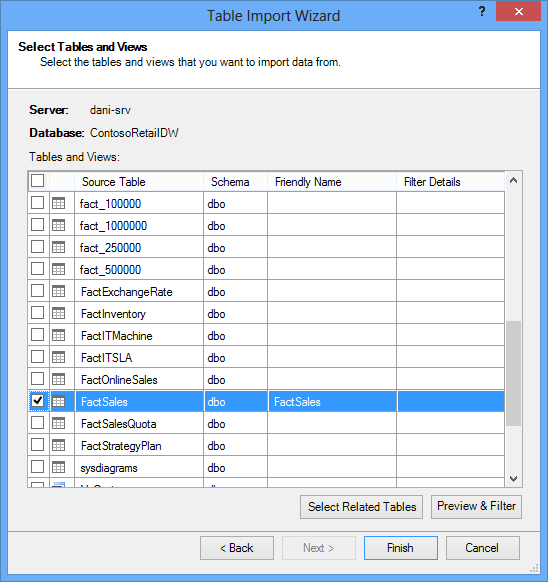
Az egyes táblák Előnézet & Szűrés gombjára kattintva kiválaszthatja a táblázatnak azokat a részeit, amelyekre valóban szüksége van. Azt javasoljuk, hogy először törölje az összes oszlop jelölését, majd folytassa a kívánt oszlopok ellenőrzésével, miután átgondolta, hogy szükségesek-e az elemzéshez.

Mi a helyzet, ha csak a szükséges sorokat szeretné szűrni?
A vállalati adatbázisok és adattárházak számos táblája hosszú időn belül felhalmozódott múltbeli adatokat tartalmaz. Emellett előfordulhat, hogy a szóban forgó táblák olyan információkat tartalmaznak az üzletágról, amelyek nem szükségesek az adott elemzéshez.
A Tábla importálása varázslóval kiszűrheti az előzményadatokat vagy a nem kapcsolódó adatokat, és így sok helyet takaríthat meg a modellben. Az alábbi képen egy dátumszűrővel csak az aktuális évre vonatkozó adatokat tartalmazó sorokat olvashatja be, kizárva azokat az előzményadatokat, amelyekre már nincs szükség.

Mi van, ha szükségünk van az oszlopra; Csökkenthetjük-e még a helyköltségét?
Létezik néhány további technika, amellyel alkalmasabbá teheti az oszlopok tömörítését. Ne feledje, hogy az oszlop egyetlen jellemzője, amely a tömörítést befolyásolja, az az egyedi értékek száma. Ebben a szakaszban megtudhatja, hogy miként módosíthatók egyes oszlopok az egyedi értékek számának csökkentése érdekében.
Dátum/idő oszlopok módosítása
A Dátum/idő oszlopok sok esetben sok helyet foglalnak el. Szerencsére számos módon lehet csökkenteni az ilyen típusú adatok tárolási követelményeit. A technikák attól függően változnak, hogy hogyan használja az oszlopot, és mennyire magabiztosan készíti az SQL-lekérdezéseket.
A dátum- és időoszlopok egy dátumrészt és egy időpontot tartalmaznak. Amikor felteszi magának a kérdést, hogy szükség van-e egy oszlopra, tegye fel ugyanazt a kérdést többször egy Datetime oszlopra vonatkozóan:
- Szükségem van az időrészre?
- Szükség van-e az időrészre az órák szintjén? , percben? , Másodperc? , ezredmásodperc?
- Több Dátum/idő oszloppal rendelkezem, mert a köztük lévő különbséget szeretném kiszámítani, vagy csak összesíteni szeretném az adatokat év, hónap, negyedév stb. szerint?
A kérdések megválaszolása határozza meg a Dátum/idő oszlop kezelésének lehetőségeit.
Mindezek a megoldások egy SQL-lekérdezés módosítását igénylik. A lekérdezések módosításának megkönnyítése érdekében minden táblából ki kell szűrnie legalább egy oszlopot. Egy oszlop kiszűrésével a lekérdezés konstrukcióját rövidített formátumról (SELECT *) módosítja egy teljesen minősített oszlopneveket tartalmazó SELECT utasításra, amely sokkal könnyebben módosítható.
Tekintse át az Önnek létrehozott lekérdezéseket. A Tábla tulajdonságai párbeszédpanelről átválthat a Lekérdezésszerkesztőre, és megtekintheti az egyes táblák aktuális SQL-lekérdezéseit.
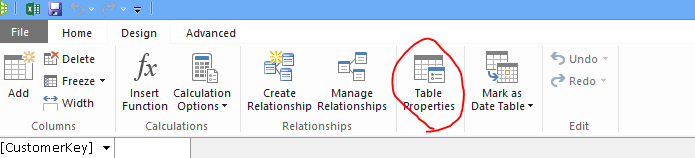
A Táblázat tulajdonságai párbeszédpanelen válassza a Lekérdezésszerkesztő elemet.

A Lekérdezésszerkesztő a tábla feltöltéséhez használt SQL-lekérdezést jeleníti meg. Ha kiszűrt egy oszlopot az importálás során, a lekérdezés teljesen minősített oszlopneveket fog tartalmazni:

Ezzel szemben, ha teljes egészében importált egy táblát anélkül, hogy törölte volna egy oszlop jelölését vagy szűrőt alkalmazna, akkor a lekérdezés "Kijelölés * ettől ", ezt a módosítást nehezebb fogja látni: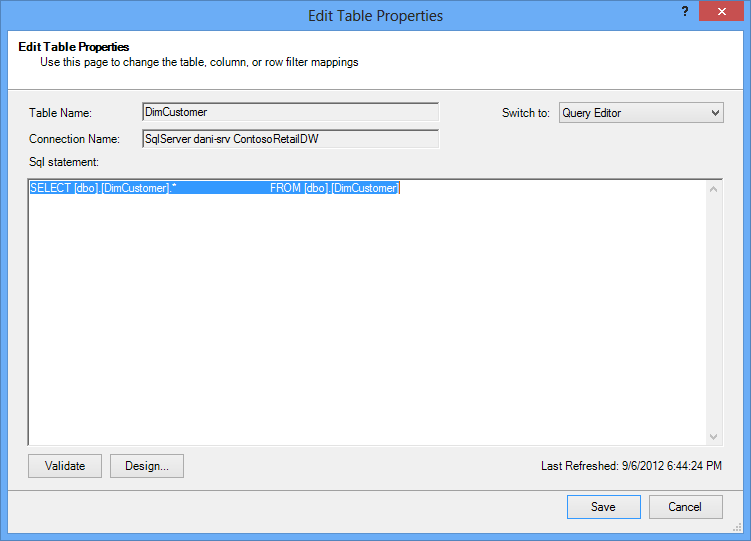
|
|---|
Az SQL-lekérdezés módosítása
Most, hogy már tudja, hogyan találhatja meg a lekérdezést, módosíthatja azt, hogy tovább csökkentse a modell méretét.
- Pénznem vagy tizedes tört adatokat tartalmazó oszlopok esetében, ha nincs szüksége a tizedesekre, a következő szintaxist használva megszabadulhat a tizedesektől:
"SELECT ROUND([Decimal_column_name],0)... .”
Ha centekre van szüksége, de nem a cent törtrészeire, cserélje le a 0-t 2-re. Negatív számok használata esetén kerekíthet egységekre, tízesre, százra stb. - Ha van egy dbo nevű Datetime oszlop. Nagytábla. [Dátum és idő] formátumban, és nincs szüksége az időrészre, akkor az alábbi szintaxist használva megszabadulhat az időtől:
"SELECT CAST (dbo. Nagytábla. [Dátum és idő] as dátum) AS [Dátum és idő]) " - Ha van egy dbo nevű Datetime oszlop. Nagytábla. [Date Time] (Dátum és idő) együtt, és a Dátum és az Idő részre egyaránt szükség van, használjon több oszlopot az SQL-lekérdezésben egyetlen Datetime oszlop helyett:
"SELECT CAST (dbo. Nagytábla. [Date Time] as date ) AS [Date Time],
DatePart(óó; dbo. Nagytábla. [Dátum és idő]) mint [Dátum Idő Óra],
DatePart(mi; dbo. Nagytábla. [Dátum és idő]) mint [Dátum Idő Perc],
DatePart(SS; DBO. Nagytábla. [Dátum és idő]) mint [Dátum és idő másodperc],
DatePart(MS; DBO. Nagytábla. [Dátum és idő]) as [Dátum és idő ezredmásodperc]"
Az egyes részek külön oszlopokban való tárolásához annyi oszlopot használjon, amennyi szükséges. - Ha órákra és percekre van szüksége, és együtt, egyetlen időpontot tartalmazó oszlopként szeretné őket használni, használja az alábbi szintaxist:
Timefromparts(Datepart(óóó, dbo. Nagytábla. [Date Time]), Datepart(mm; dbo. Nagytábla. [Dátum és idő])) as [Dátum Idő ÓraPerc] - Ha két dátum/idő oszlop van (például [Kezdés időpontja] és [Befejezés időpontja]), és valójában a köztük lévő időkülönbségre van szüksége másodpercben [Időtartam] nevű oszlopban, távolítsa el mindkét oszlopot a listából, és vegye fel a következőt:
"datediff(ss;[Kezdő dátum];[Záró dátum]) As [Időtartam]"
Ha az ms kulcsszót használja az ss helyett, az időtartamot ezredmásodpercben adja meg
Számított DAX-mértékek használata oszlopok helyett
Ha korábban már használta a DAX kifejezésnyelvét, akkor bizonyára már tudja, hogy a számított oszlopok a modell más oszlopai alapján származtatják az új oszlopokat, míg a számított mértékeket a modellben egyszer definiálja, de a kimutatásban vagy más jelentésben történő felhasználás esetén értékeli ki.
A memóriatakarékossági módszerek egyike a normál vagy számított oszlopok számított mértékekre cserélése. A klasszikus példa az Egységár, a Mennyiség és az Összesen. Ha mindhárom megvan, helyet takaríthat meg azzal, hogy csak kettőt tart fenn, a harmadikat pedig a DAX használatával számítja ki.
Melyik 2 oszlopot tartsa meg?
A fenti példában tartsa meg a mennyiséget és az egységárat. E kettő kevesebb értéket tartalmaz, mint az Összeg oszlopé. Az Összeg kiszámításához vegyen fel egy számított mértéket, például:
"TotalSales:=sumx('Sales Table','Sales Table'[Unit Price]*'Sales Table'[Quantity])"
A számított oszlopok hasonlítanak a normál oszlopokhoz, mivel mindkettő helyet foglal el a modellben. Ezzel szemben a számított mértékek kiszámítása azonnal történik, és nem foglal helyet.
Befejezés
Ebben a cikkben több olyan megközelítést ismertetünk, amelyek segíthetnek egy memóriahatékonyabb modell felépítésében. Az adatmodellek fájlméretét és memóriaigényét úgy csökkentheti, hogy csökkenti az oszlopok és sorok számát, és az egyes oszlopokban megjelenő egyedi értékek számát. Íme néhány általunk tárgyalt technika:
- Természetesen az oszlopok eltávolítása a legjobb módja a helymegtakarításnak. Döntse el, hogy mely oszlopokra van igazán szüksége.
- Időnként előfordulhat, hogy eltávolít egy oszlopot, és helyettesíti egy számított mértékkel a táblázatban.
- Előfordulhat, hogy nem kell az összes sort kimásolnia egy táblázatba. A Tábla importálása varázslóban kiszűrheti a sorokat.
- Általánosságban elmondható, hogy egy oszlop több különálló részre való szétbontása jó módszer az egy oszlopban lévő egyedi értékek számának csökkentésére. Az egyes részekhez kis számú egyedi érték tartozik, és az összesített összeg kisebb lesz, mint az eredeti egyesített oszlop.
- Sok esetben szüksége van arra is, hogy a különálló részeket szeletelőként felhasználja a jelentésekben. Ha szükséges, hierarchiákat hozhat létre részekből (például Óra, Perc, Másodperc).
- Gyakran az oszlopok a szükségesnél több információt is tartalmaznak. Tegyük fel például, hogy egy oszlop tizedesjegyeket tárol, de Ön formázással elrejti a tizedeseket. A kerekítés nagyon hatékonyan használható a numerikus oszlopok méretének csökkentésében.
Most, hogy a munkafüzet méretének csökkentése érdekében mindent megtett, érdemes futtatni a Munkafüzetméret-optimalizálót. A funkció elemzi az Excel-munkafüzetet, és ha lehetséges, tovább tömöríti. Töltse le a Munkafüzetméret-optimalizálót.
Kapcsolódó hivatkozások
Az adatmodell specifikációja és korlátozásai
Power Pivot: Hatékony adatelemzés és adatmodellezés az Excelben