
샘플에 따라 표준 편차를 예측합니다(샘플의 논리 값 및 텍스트 무시).
표준 편차를 통해 값이 평균 값에서 벗어나 있는 정도를 알 수 있습니다.
구문
STDEV.S(number1,[number2],...)
STDEV.S 함수 구문에는 다음과 같은 인수가 사용됩니다.
- Number1 필수. 모집단 표본에 해당하는 첫 번째 숫자 인수입니다. 쉼표로 구분된 인수 대신 단일 배열이나 배열에 대한 참조를 사용할 수도 있습니다.
- 번호2, ... 선택적. 모집단 표본에 해당하는 숫자 인수로, 2개에서 254개까지 지정할 수 있습니다. 쉼표로 구분된 인수 대신 단일 배열이나 배열에 대한 참조를 사용할 수도 있습니다.
주의
- STDEV.S 함수는 인수를 모집단의 표본으로 간주합니다. 데이터 집합이 모집단 전체를 나타내면 STDEV.P 함수를 사용하여 표준 편차를 계산해야 합니다.
- 표준 편차는 "n-1" 방법을 사용하여 계산합니다.
- 인수는 숫자이거나 숫자를 포함한 이름, 배열 또는 참조 영역일 수 있습니다.
- 인수 목록에 직접 입력하는 논리값, 텍스트로 나타낸 숫자 등은 계산에 포함됩니다.
- 인수가 배열 또는 참조인 경우 해당 배열 또는 참조의 숫자만 계산됩니다. 배열 또는 참조의 빈 셀, 논리 값, 텍스트 또는 오류 값은 무시됩니다.
- 인수가 오류 값이거나 숫자로 변환할 수 없는 텍스트이면 오류가 발생합니다.
- 참조에 포함된 논리값 및 텍스트로 나타낸 숫자를 계산에 포함하려면 STDEVA 함수를 사용합니다.
- STDEV.S는 다음과 같이 계산됩니다.
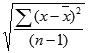
여기에서 x는 표본 평균 AVERAGE(number1,number2,...)이고 n은 표본 크기입니다.
예제
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. ("Data"라는 단어가 포함된 셀은 복사하지 마세요.) 결과를 표시할 수식의 경우 결과를 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
| 데이터 | ||
|---|---|---|
| 강도 | ||
| 1345 | ||
| 1301 | ||
| 1368 | ||
| 1322 | ||
| 1310 | ||
| 1370 | ||
| 1318 | ||
| 1350 | ||
| 1303 | ||
| 1299 | ||
| 수식 | 설명 | 결과 |
| =STDEV.S(A2:A11) | 분쇄 강도의 표준 편차를 반환합니다. | 27.46391572 |