Funkcija GROUPBY ļauj izveidot datu kopsavilkumu, izmantojot formulu. Tā atbalsta grupēšanu vienā asī un saistīto vērtību apkopošanu. Piemēram, ja jums ir pārdošanas datu tabula, varat ģenerēt pārdošanas datu kopsavilkumu pēc gada.
Sintakse
Funkcija GROUPBY ļauj grupēt, apkopot, kārtot un filtrēt datus, pamatojoties uz norādītajiem laukiem.
Funkcijas GROUPBY sintakse ir:
GROUPBY(row_fields,vērtības,funkcija,[field_headers],[total_depth],[sort_order],[filter_array],[field_relationship])
| Arguments | Apraksts |
|---|---|
|
row_fields (obligāts) |
Uz kolonnu orientēts masīvs vai diapazons, kurā ir vērtības, kuras tiek izmantotas rindu grupēšanai un rindu galveņu ģenerēšanai. Masīvā vai diapazonā var būt vairākas kolonnas. Tādā gadījumā izvadei būs vairāki rindu grupu līmeņi. |
|
vērtības (obligāts) |
Uz kolonnu orientēts apkopojamo datu masīvs vai diapazons. Masīvā vai diapazonā var būt vairākas kolonnas. Tādā gadījumā izvadei būs vairāki apkopojumi. |
|
funkcija (obligāts) |
Tiešs vai samazināts lambda (SUM, PERCENTOF, AVERAGE, COUNT utt.), kas tiek izmantots, lai apkopotu vērtības. Var nodrošināt lambdu vektoru. Tādā gadījumā izvadei būs vairāki apkopojumi. Vektora orientācija noteiks, vai tie ir izvietoti rindas vai kolonnas veidā. |
| field_headers | Skaitlis, kas norāda, vai row_fields un vērtībām ir galvenes un vai lauku galvenes ir jāatgriež rezultātos. Tālāk norādītas iespējamās vērtības. Trūkst: Automātisks (noklusējums) 0: Nē 1. Jā un nerādīt 2: Nē, bet ģenerēt 3: Jā un rādīt Piezīme. Automātiski pieņem, ka dati satur galvenes, pamatojoties uz vērtību argumentu. Ja 1. vērtība ir teksts un 2. vērtība ir skaitlis, tad tiek pieņemts, ka datiem ir galvenes. Lauku galvenes tiek rādītas, ja ir vairāki rindu vai kolonnu grupu līmeņi. |
| total_depth | Nosaka, vai rindu galvenēs jābūt kopsummām. Tālāk norādītas iespējamās vērtības. Trūkst: Automātiski: gala summas un, ja iespējams, starpsummas (noklusējums) 0: Bez kopsummām 1: Gala summas 2: gala summas un starpsummas -1: gala summas augšpusē -2: gala summas un starpsummas augšdaļā Piezīme. Starpsummu laukos ir jābūt vismaz 2 kolonnām. Skaitļi, kas lielāki par 2, tiek atbalstīti, ja laukā ir pietiekami daudz kolonnu. |
| sort_order | Skaitlis, kas norāda, kā jākārto rindas. Skaitļi atbilst kolonnām row_fields , kam seko vērtību kolonnas. Ja skaitlis ir negatīvs, rindas tiek kārtotas dilstošā un apgrieztā secībā. Kārtojot pēc row_fields, var norādīt skaitļu vektoru. |
| filter_array | Uz kolonnu orientēts Būla vērtību 1D masīvs, kas norāda, vai jāņem vērā atbilstošā datu rinda. Piezīme. Masīva garumam jāatbilst row_fields nodrošināto masīvu garumam. |
| field_relationship | Ja row_fields ir nodrošinātas vairākas kolonnas, norāda relāciju laukus. Tālāk norādītas iespējamās vērtības. 0: Hierarhija (noklusējums) 1: tabula Ar hierarhijas lauku relāciju (0), kārtojot vēlākas lauka kolonnas, tiek ņemta vērā iepriekšējo kolonnu hierarhija. Izmantojot tabulas lauku relāciju (1), katras lauka kolonnas kārtošana tiek veikta neatkarīgi. Starpsummas netiek atbalstītas, jo tās ir atkarīgas no datiem ar hierarhiju. |
Piemēri
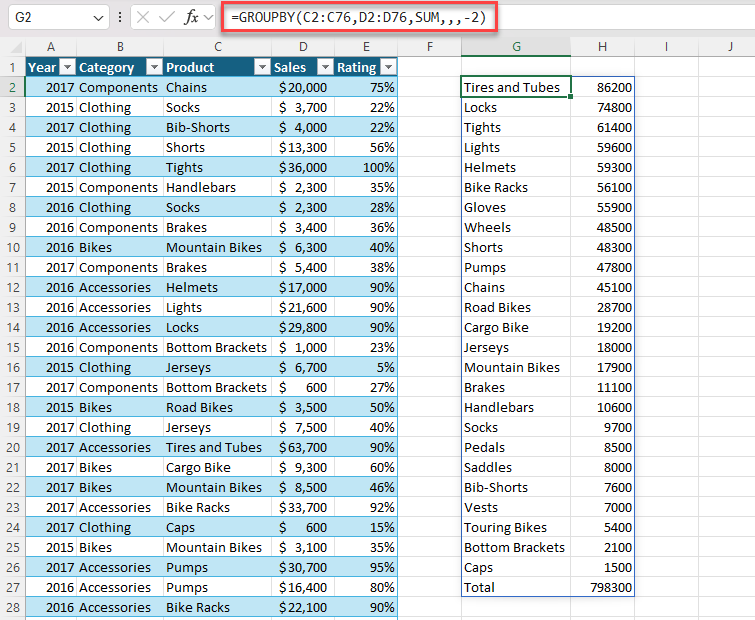
1. piemērs. Izmantojiet funkciju GROUPBY , lai ģenerētu kopsavilkumu par kopējo pārdošanas apjomu pa gadiem.

2. piemērs. Izmantojiet funkciju GROUPBY , lai ģenerētu kopsavilkumu par kopējo pārdošanas apjomu pēc produkta. Kārtot dilstošā secībā pēc pārdošanas apjoma.