
Ko ste svoje podatke preselili iz Accessa v SQL Server, imate na voljo zbirko podatkov odjemalca/strežnika, ki je lahko v prostorih podjetja ali kot hibridna rešitev v oblaku Azure. Access tako postane predstavitveni sloj, SQL Server pa podatkovni sloj. Zdaj je pravi čas, da ponovno razmislite o vidikih svoje rešitve, zlasti glede učinkovitosti poizvedb, varnosti in kontinuitete poslovanja, da boste lahko izboljšali in prilagodili rešitev zbirke podatkov.
 Če želite, da accessov uporabnik najprej izpolnjuje zahteve SQL Server in Azure lahko zdi zahtevno. Potrebovali bi vodnika, ki bi vas popeljal skozi vse pomembne teme. Ko dokončate ta izlet, boste pripravljeni, da raziščete napredek v tehnologiji zbirke podatkov in se odpravite na daljše potovanje.
Če želite, da accessov uporabnik najprej izpolnjuje zahteve SQL Server in Azure lahko zdi zahtevno. Potrebovali bi vodnika, ki bi vas popeljal skozi vse pomembne teme. Ko dokončate ta izlet, boste pripravljeni, da raziščete napredek v tehnologiji zbirke podatkov in se odpravite na daljše potovanje.
V tem članku
Zagotavljanje neprekinjenega poslovanja
Pri rešitvi za Access želite, da je zbirka podatkov dostopna in na voljo brez večjih prekinitev, toda možnosti za zaledne zbirke podatkov za Access so omejene. Če želite zaščititi svoje podatke, varnostno kopirajte zbirko podatkov za Access. Vendar boste v tem primeru morali prekiniti povezavo med uporabniki in zbirko podatkov. Nato je tu še nepredvideni izpad zaradi vzdrževanja strojne/programske opreme, izpadov omrežja ali električne energije, okvar strojne opreme, kršitev varnosti ali celo kibernetskih napadov. Če želite skrajšati čas izpada in zmanjšati učinek, ki ga povzroči nerazpoložljivost storitve na podjetje, lahko zbirko podatkov strežnika SQL Server varnostno kopirate med uporabo. SQL Server prav tako omogoča strategije visoke razpoložljivosti (HA) in strategije vnovične vzpostavitve po katastrofi (DR). Ti dve tehnologiji skupno imenujemo HADR. Če želite več informacij, glejte Neprekinjeno poslovanje in obnovitev zbirke podatkov ter Zagotavljanje neprekinjenega poslovanja SQL Server (e-knjiga).
Varnostno kopiranje med uporabo
SQL Server uporablja postopek spletnega varnostnega kopiranja, ki ga lahko zaženete med delovanjem zbirke podatkov. Odločite se lahko za celotno ali delno varnostno kopijo oziroma za varnostno kopijo datotek. Pri varnostnem kopiranju sistem kopira podatke in dnevnike transakcij ter tako zagotovi celovit postopek obnovitve. Zlasti pri rešitvi na mestu uporabe se seznanite z razlikami med možnostmi preproste in celotne obnovitve ter kako vplivajo na rast dnevnika transakcij. Če želite več informacij, glejte Modeli obnovitve.
Večina varnostnih kopiranj se izvede nemudoma, razen upravljanja datotek in operacije zmanjševanja zbirke podatkov. Če torej želite ustvariti datoteko zbirke podatkov ali jo izbrisati med varnostnem kopiranjem, tega dejanja ne bo mogoče izvesti. Če želite več informacij, glejte Pregled varnostnega kopiranja.
HADR
Dve najpogostejši tehniki, s katerima dosežete visoko razpoložljivost in neprekinjeno poslovanje, sta zrcaljenje in gručenje. SQL Server združuje tehnologijo zrcaljenja in gručenja z možnostma »Vedno ob izpadu primerkov v gruči« in »Vedno ob skupinah razpoložljivosti«.
Zrcaljenje predstavlja rešitev kontinuitete na ravni zbirke podatkov, ki podira takojšnji nadomestni način delovanja na račun vzdrževanja zbirke podatkov v pripravljenosti, celotne kopije ali zrcaljenja aktivne zbirke podatkov v ločeni strojni opremi. Deluje lahko v sinhronem načinu (z visoko varnostjo), pri čemer je dohodna transakcija potrjena v vseh strežnikih hkrati, oziroma v asinhronem načinu (z visoko zmogljivostjo), pri čemer je dohodna transakcija potrjena v aktivno zbirko podatkov in nato ob vnaprej določenem trenutku kopirana v zrcalno različico. Zrcaljenje je rešitev na ravni zbirke podatkov in deluje samo z zbirkami podatkov, ki uporabljajo model popolne obnovitve.
Gručenje predstavlja rešitev na ravni strežnika, kjer so strežniki združeni v eno shrambo podatkov, ki je uporabniku prikazana kot en primerek. Uporabniki se povežejo s primerkom in jim ni treba vedeti, kateri strežnik primerka je trenutno aktiven. Če en strežnik ne uspe ali ga je zaradi vzdrževanja treba vzeti brez povezave, se uporabniška izkušnja ne spremeni. Vsak strežnik v gruči nadzoruje upravitelj gruče s signalom obveščanja. Tako zazna, ko se prekine povezava s trenutno aktivnim strežnikom v gruči, in poskuša nemoteno preklopiti na naslednji strežnik v gruči. V tem primeru pride do spremenljive časovne zamude med preklopom na drug strežnik.
Če želite več informacij, glejte Vedno vklopljeni primerki gruče za preklop ob izpadu in Vedno vklopljene skupine razpoložljivosti: rešitev z visoko razpoložljivostjo in po katastrofi.
Varnost strežnika SQL Server
Čeprav lahko Accessovo zbirko podatkov zaščitite tako, da jo šifrirate v središču zaupanja, ima SQL Server na voljo naprednejše varnostne funkcije. O poglejmo tri zmogljivosti, ki izstopajo za Accessovega uporabnika. Če želite več informacij, glejte Zaščita SQL Server.
Preverjanje pristnosti zbirke podatkov
V strežniku SQL Server so na voljo štirje načini za preverjanje pristnosti zbirke podatkov – vsakega lahko določite v nizu povezave ODBC. Če želite več informacij, preberite Povezovanje ali uvoz podatkov iz zbirke podatkov strežnika Azure SQL Server. Vsak način ima svoje prednosti.
Integrirano preverjanje pristnosti sistema Windows Uporabite poverilnice sistema Windows za preverjanje veljavnosti uporabnikov, varnostne vloge in omejevanje uporabnikov na funkcije in podatke. V programu lahko uporabite poverilnice domene in upravljate uporabnikove pravice. Po želji lahko vnesete glavna imena storitve (SPN-je). Če želite več informacij, glejte Izbira načina preverjanja pristnosti.
SQL Server preverjanja pristnosti Morajo uporabniki vzpostaviti povezavo s poverilnicami, ki so nastavljene v zbirki podatkov, tako da vnesete ID za prijavo in geslo, ko prvič dostopajo do zbirke podatkov v seji. Če želite več informacij, glejte Izbira načina preverjanja pristnosti.
Azure preverjanje pristnosti imenika Active Directory Vzpostavite povezavo z Azure SQL Server podatkov z uporabo Azure Active Directory. Ko konfigurirate preverjanje pristnosti imenika Azure Active Directory, vam ni treba vnesti dodatnega uporabniškega imena in gesla. Če želite več informacij, glejte Vzpostavljanje povezave z zbirko podatkov SQL z uporabo preverjanja Azure imenika Active Directory.
Preverjanje pristnosti gesla imenika Active Directory Povežite se s poverilnicami, ki so nastavljene v imeniku Azure Active Directory, tako da vnesete uporabniško ime in geslo. Če želite več informacij, glejte Vzpostavljanje povezave z zbirko podatkov SQL z uporabo preverjanja Azure imenika Active Directory.
Nasvet Z zaznavanjem groženj prejemajte opozorila o nenavadni dejavnosti zbirke podatkov, ki označuje morebitne varnostne grožnje za Azure SQL Server zbirko podatkov. Če želite več informacij, glejte Zaznavanje groženj zbirke podatkov SQL.
Varnost programov
SQL Server ima vgrajeni dve varnostni funkciji na ravni programa, ki jih lahko uporabite z Accessom.
Dinamično maskiranje podatkov Prikrijte občutljive informacije tako, da jih zakrijete pred uporabniki, ki imajo pravice. Tako lahko na primer deloma ali v celoti prekrijete številko socialnega zavarovanja.
 maska Delna podatkovna maska
maska Delna podatkovna maska |
 – polna podatkovna maska
– polna podatkovna maska |
|---|
Na voljo je več načinov, s katerimi lahko določite podatkovno masko in jo uporabite pri različnih vrstah podatkov. Maskiranje podatkov upravlja pravilnik na ravni tabele in stolpca za določen nabor uporabnikov in se sproti uporabi pri poizvedbi. Če želite več informacij, glejte Dinamično maskiranje podatkov.
Varnost na ravni vrstice Dostop do določenih vrstic zbirke podatkov z občutljivimi podatki na podlagi uporabniških značilnosti lahko nadzirate z Row-Level varnosti. Sistem zbirk podatkov uporabi omejitve dostopa, zaradi česar je bolj zanesljiv in vzdržljiv.
 Obstajata dve vrsti varnostnih predikatov:
Obstajata dve vrsti varnostnih predikatov:
- Predikat filtra filtrira vrstice v poizvedbi. Filter je prosojen in končni uporabnik se ne zaveda, da je bil uporabljen kateri koli filter.
- Predikat bloka preprečuje nepooblaščeno dejanje in vrne izjemo, če dejanja ni mogoče izvesti.
Če želite več informacij, glejte Varnost na ravni vrstice.
Zaščita podatkov s šifriranjem
Zaščitite podatke v mirovanju, med selitvijo ali pri uporabi, ne da bi vplivali na učinkovitost delovanja zbirke podatkov. Če želite več informacij, glejte SQL Server šifriranje.
Šifriranje v mirovanju Če želite zaščititi osebne podatke pred napadi predstavnosti brez povezave na fizični plasti za shranjevanje, uporabite šifriranje v mirovanju, imenovano tudi prosojno šifriranje podatkov (TDE). Vaši podatki bodo tako zaščiteni, tudi če je bila fizična predstavnost ukradena ali razkrita na nepravilen način. TDE izvaja sprotno šifriranje in dešifriranje zbirk podatkov, varnostnih kopij in dnevnikov transakcij brez potrebe po spreminjanju vaših programov.
Šifriranje med prevozom Za zaščito pred vohanje in »napadi sredine« lahko šifrirate podatke, prenesene po omrežju. SQL Server podpira varnost na transportni ravni (TLS) 1.2 in tako omogoča izjemno varno komunikacijo. Protokol tabelaričnega podatkovnega toka (TDS) se prav tako uporablja za zaščito komunikacije prek omrežij, ki niso vredna zaupanja.
Šifriranje, ki se uporablja v odjemalcu Za zaščito osebnih podatkov med uporabo je »Always Encrypted« funkcija, ki jo želite. Osebne podatke šifrira in dešifrira gonilnik v odjemalskem računalniku, pri tem pa šifrirnih ključev ne razkrije mehanizmu zbirke podatkov. Šifrirani podatki so tako vidni le osebam, odgovornim za upravljanje teh podatkov, ne pa tudi drugim visoko privilegiranim uporabnikom, ki ne bi smeli imeti dostopa. Možnost »Vedno šifrirano« lahko omeji nekatere funkcije zbirke podatkov, kot so iskanje, dodajanje v skupine in indeksiranje šifriranih stolpcev, kar je odvisno od izbrane vrste šifriranja.
Pomisleki glede zasebnosti
Pomisleki glede varnosti so tako pogosti, da je Evropska Unija s Splošno uredbo o varstvu podatkov (GDPR) poskrbela za opredelitev pravnih zahtev. Zaledni strežnik SQL Server je na srečo dovolj prilagodljiv, da se je lahko odzval na nove zahteve. Uvajanje uredbe GDPR si zamislite v treh korakih.
 , 1. korak: ocenjevanje in upravljanje tveganja
, 1. korak: ocenjevanje in upravljanje tveganja
Uredba GDPR zahteva, da prepoznate in popišete osebne podatke, shranjene v tabelah ter datotekah. Ti podatki lahko vključujejo imena, fotografije, e-poštne naslove, podatke o banki, objave na spletnih mestih družabnih omrežij, zdravniške informacije ali celo naslove IP.
Z novim orodjem SQL Data Discovery and Classification, vgrajenim v SQL Server Management Studio lahko odkrijete, razvrstite, označite in prijavite podatke v storitvi občutljivi podatki tako, da v stolpcih uporabite dva atributa metapodatkov:
- Oznake Določanje občutljivosti podatkov.
- Vrste informacij Če želite zagotoviti dodatno razdrobljenost glede vrst podatkov, shranjenih v stolpcu.
Mehanizem za odkrivanje, ki ga prav tako lahko uporabite, je iskanje po celotnem besedilu, ki vključuje uporabo predikatov »CONTAINS« in »FREETEXT«, ter funkcije, ovrednotene z naborom vrstic, kot sta »CONTAINSTABLE« in »FREETEXTTABLE«, za uporabo v izjavi SELECT. Če uporabite funkcijo iskanja po celotnem besedilu, lahko v tabelah poiščete besede, besedne zveze ali različice besed, kot so sopomenke ali različni skloni. Če želite več informacij, glejte Iskanje v celozaslonskem besedilu.
2. korak: Zaščita osebnih podatkov
Uredba GDPR zahteva, da zaščitite osebne podatke in omejite dostop do njih. Poleg izvedenih običajnih korakov za upravljanje dostopa do omrežja in virov, kot so nastavitve požarnega zidu, lahko z varnostnimi funkcijami strežnika SQL Server nadzorujete dostop do podatkov:
- Preverjanje pristnosti strežnika SQL Server za upravljanje identitet uporabnikov in preprečevanje nepooblaščenega dostopa.
- Varnost na ravni vrstice za omejitev dostopa do vrstic v tabeli glede na relacijo med uporabnikom ter podatki.
- Dinamično maskiranje podatkov za omejitev izpostavljenosti osebnih podatkov, ki jih skrijete pred uporabniki z neustreznimi pravicami.
- Šifriranje za zagotavljanje zaščite osebnih podatkov med prenosom in shranjevanjem ter za zaščito pred tveganji, tudi na strani strežnika.
Če želite več informacij, preberite Varnost strežnika SQL Server.
3. korak: Učinkovito odzivanje na zahteve
Uredba GDPR zahteva, da ohranjate zapise o obdelavi osebnih podatkov, ki jih na zahtevo predložite nadzornim organom. Če pride do težav, vključno z nenamerno objavo podatkov, se lahko hitro odzovete s funkcijo nadzora zaščite. Podatki morajo biti hitro na voljo, ko je zahtevano poročanje. Uredba GDPR na primer zahteva, da se kršitev osebnih podatkov poroča nadzornemu organu »najpozneje 72 ur po tem, ko je seznanjena z njim«.
S strežnikom SQL Server 2017 lahko izvedete opravila poročanja na več načinov:
- SQL Server nadzor vam pomaga zagotoviti, da obstajajo trajni zapisi o dostopu do zbirke podatkov in obdelavi. Storitev omogoča podroben nadzor za spremljanje dejavnosti zbirke podatkov, s katerim lažje razumete in prepoznate morebitna tveganja, sum zlorabe ali varnostne kršitve. Nemudoma lahko izvedete forenziko podatkov.
- Začasne tabele strežnika SQL Server so uporabniške tabele s sistemskimi različicami, zasnovane na način, ki zagotavlja celotno zgodovino sprememb podatkov. Uporabite jih lahko za preprosto poročanje in časovne analize.
- Z oceno ranljivosti STREŽNIKA SQL lahko zaznate težave z varnostjo in dovoljenji. Ko sistem zazna težavo, lahko podrobneje raziščete poročila o pregledih zbirke podatkov in poiščete ustrezne rešitve.
Če želite več informacij, glejte Ustvarjanje platforme zaupanja (e-knjiga) in Zagotavljanje skladnosti s predpisi uredbe GDPR.
Ustvarjanje posnetkov zbirke podatkov
Posnetek zbirke podatkov predstavlja statičen pogled zbirke podatkov v strežniku SQL Server ob določenem času, ki je na voljo samo za branje. Čeprav lahko kopirate datoteko Accessove zbirke podatkov in učinkovito ustvarite posnetek zbirke podatkov, Access nima vgrajene metodologije, kot jo ima denimo SQL Server. Posnetek zbirke podatkov lahko uporabite za pisanje poročil, ki vključujejo podatke ob času nastanka posnetka zbirke podatkov. Posnetek zbirke podatkov lahko uporabite tudi za vzdrževanje zgodovinskih podatkov, na primer za posamezna četrtletja poslovnega leta, ki jih uporabljate za pripravo končnih poročil. Priporočamo naslednje najboljše prakse:
- Poimenovanje posnetka Vsak posnetek zbirke podatkov zahteva enolično ime zbirke podatkov. Imenu dodajte namen in časovni okvir za lažjo identifikacijo. Če želite na primer za zbirko podatkov AdventureWorks ustvariti posnetek trikrat dnevno na vsakih šest ur med 6.00 in 18.00 (glede na 24-urni zapis časa), posnetke poimenujte AdventureWorks_posnetek_0600, AdventureWorks_posnetek_1200 in AdventureWorks_posnetek_1800.
- Omejite število posnetkov Vsak posnetek zbirke podatkov se ohrani, dokler ga izrecno ne izpustite. Ker bo velikost posameznih posnetkov stalno naraščala, priporočamo, da izbrišete starejši posnetek, po tem ko ste ustvarili nov posnetek, da boste prihranili nekaj prostora na disku. Če denimo ustvarjate dnevna poročila, ohranite posnetek zbirke posnetkov za 24 ur, nato pa ga opustite in zamenjajte z novejšim.
- Povezovanje s pravilnim posnetkom Če želite uporabiti posnetek zbirke podatkov, mora Accessov ospredje poznati pravilno mesto. Ko obstoječi posnetek zamenjate z novim, Access preusmerite na novi posnetek. V osprednji Accessov strežnik dodajte logiko – na ta način se boste prepričali, da se povezujete s pravilnim posnetkom zbirke podatkov.
Posnetek zbirke podatkov ustvarite tako:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Če želite več informacij, glejte Posnetki zbirke podatkov (SQL Server).
Sočasni nadzor
Če želi več oseb hkrati spremeniti podatke v zbirki podatkov, potrebujete nadzorni sistem, da spremembe ene osebe ne bodo neugodno vplivale na spremembe druge osebe. Temu pravimo sočasni nadzor in na voljo sta dve osnovni strategiji zaklepanja – pesimistična in optimistična. S funkcijo zaklepanja lahko uporabnikom preprečite spreminjanje podatkov na način, ki vpliva na druge uporabnike. Z zaklepanjem lahko prav tako zagotovite celovitost zbirke podatkov, zlasti pri poizvedbah, ki bi v nasprotnem primeru lahko vrnile nepričakovane rezultate. Obstajajo pomembne razlike v načinu, kako Access in SQL Server uvajata strategije sočasnega nadzora.
V Accessu je privzeta strategija zaklepanja optimistična in podeli lastništvo ključavnice prvi osebi, ki poskuša zapisati zapis. Access drugi osebi, ki poskuša hkrati zapisati zapis, prikaže pogovorno okno Spor pri pisanju. Druga oseba lahko spor razreši tako, da shrani zapis, ga kopira v odložišče ali opusti spremembe.
Prav tako lahko uporabite lastnost RecordLocks, s katero spremenite strategijo sočasnega nadzora. S to lastnostjo, ki ima na voljo tri nastavitve, vplivate na obrazce, poročila in poizvedbe:
- Brez zaklepanja V obrazcu lahko uporabniki poskušajo hkrati urejati isti zapis, vendar se lahko prikaže pogovorno okno Spor pri pisanju. V poročilu zapisi niso zaklenjeni, ko je poročilo odprto za predogled ali tiskanje. Med izvajanjem poizvedbe zapisi niso zaklenjeni. To je način, kako Access uvaja strategijo optimističnega zaklepanja.
- All Records Vsi zapisi v temeljni tabeli ali poizvedbi so zaklenjeni, ko je obrazec odprt v pogledu obrazca ali podatkovnega lista, medtem ko je poročilo odprto v predogledu ali tiskanju ali med izvajanjem poizvedbe. Uporabniki lahko preberejo zaklenjene zapise.
- Urejen zapis Za obrazce in poizvedbe je stran z zapisi zaklenjena takoj, ko začne kateri koli uporabnik urejati katero koli polje v zapisu in ostane zaklenjena, dokler se uporabnik ne premakne v drug zapis. To pomeni, da lahko vsak zapis hkrati ureja le en uporabnik. To je način, kako Access uvaja strategijo pesimističnega zaklepanja.
Če želite več informacij, glejte Pogovorno okno »Spor pri pisanju«in Lastnost RecordLocks.
V strežniku SQL Server sočasni nadzor deluje na naslednji način:
- Pesimistični Ko uporabnik izvede dejanje, ki povzroči, da se zaklene, drugi uporabniki ne morejo izvesti dejanj, ki bi bila v sporu z zaklepanjem, dokler lastnik ne sprosti zaklepanja. Ta sočasni nadzor se v glavnem uporablja v okoljih, kjer je veliko sporov za podatke.
- Optimistični Pri optimističnem sočasnem nadzoru uporabniki ne zaklenejo podatkov, ko jih preberejo. Ko uporabnik posodobi podatke, sistem preveri, ali je drug uporabnik morda spremenil podatke po branju. Če je drug uporabnik posodobil podatke, se prikaže napaka. Uporabnik, ki prejme napako, običajno povrne transakcijo na prejšnje stanje in začne znova. Ta sočasni nadzor se v glavnem uporablja v okoljih, kjer je malo sporov za podatke.
Vrsto sočasnega nadzora določite tako, da izberete več ravni izolacije transakcije, s katerimi opredelite raven zaščite transakcije pred spremembami, opravljenimi z drugimi transakcijami, z izjavo SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}
| Raven izolacije | Opis |
|---|---|
| Preberi neizvedeno | Transakcije so izolirane le toliko, da sistem ne prebere poškodovanih podatkov. |
| Preberi izvedeno | Transakcije lahko preberejo podatke, ki jih je prej prebrala druga transakcija, brez čakanja, da se dokonča prva transakcija. |
| Ponovljeno branje | V izbranih podatkih se pojavijo zaklepi za branje in pisanje, dokler se transakcija ne konča. Lahko pa pride do fantomskega branja. |
| Posnetek | Uporablja različico vrstice za zagotavljanje skladnosti branja na ravni transakcije. |
| Je mogoče serializirati | Transakcije so popolnoma izolirane druga od druge. |
Če želite več informacij, glejte Vodnik za zaklepanje transakcij in shranjevanje različic vrstic.
Izboljšanje učinkovitosti poizvedb
Ko ste pravilno nastavili Accessovo prepustno poizvedbo, izkoristite prefinjene načine, kako lahko SQL Server omogoči učinkovitejše izvajanje poizvedbe.
V primerjavi z Accessovo zbirko podatkov SQL Server omogoča vzporedno pošiljanje poizvedb, s katerimi lahko optimizirate izvajanje poizvedb in indeksiranje v računalnikih z več mikroprocesorji (CPE). Ker lahko SQL Server z več delovnimi niti sistema vzporedno izvede poizvedbo ali indeksiranje, je mogoče operacijo izvesti hitreje in učinkoviteje.
Poizvedbe predstavljajo kritične komponente za izboljšanje splošne učinkovitosti za vašo rešitev zbirke podatkov. Slabe poizvedbe se lahko izvajajo v nedogled, lahko poteče njihova časovna omejitev in uporabljajo vire, kot so enote CPE, pomnilnik in pasovno širino omrežja. To pa preprečuje razpoložljivost kritičnih poslovnih informacij. Celo ena slaba poizvedba lahko povzroči resne težave z učinkovitostjo delovanja vaše zbirke podatkov.
Če želite več informacij, glejte Hitrejše poizvediranje SQL Server (e-knjiga).
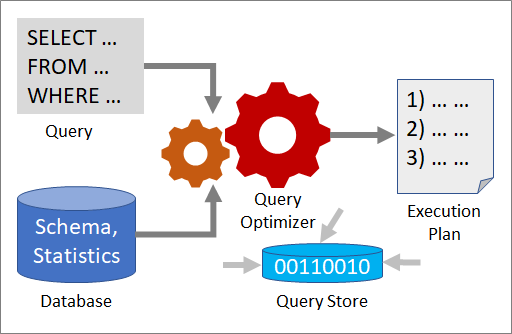
Optimizacija poizvedbe
Z več orodji lahko analizirate učinkovitost delovanja poizvedbe in jo izboljšate: optimizator poizvedb, načrti izvajanja in trgovina poizvedb.
 poizvedb
poizvedb
Optimizator poizvedb je eno najpomembnejših komponent strežnika SQL Server. Optimizator poizvedb uporabite za analiziranje poizvedbe in določevanje najučinkovitejšega načina za dostopanje do zahtevanih podatkov. Vnos optimizatorja poizvedb sestoji iz poizvedbe, sheme zbirke podatkov (definicije tabele in indeksa) ter statistike zbirke podatkov. Rezultat optimizatorja poizvedb je načrt izvajanja.
Če želite več informacij, glejte SQL Server optimizator poizvedb.
Načrt izvajanja
Načrt izvajanja omogoča vrstni red dostopa do izvirnih tabel in načine za izvlečenje podatkov iz posameznih tabel. Optimizacija predstavlja postopek izbire načrta izvajanja med več različnimi načrti. Vsak načrt izvajanja ima povezane stroške v obliki uporabljenih računalniških virov, optimizator poizvedb pa izbere tistega z najnižjimi predvidenimi stroški.
SQL Server se prav tako mora dinamično prilagajati na spreminjajoče se pogoje v zbirki podatkov. Regresije pri načrtih za izvajanje poizvedb lahko v veliki meri vpliva na učinkovitost delovanja. Nekatere spremembe zbirke podatkov lahko povzročijo neučinkovito delovanje ali celo neveljavnost načrta izvajanja, kar je odvisno od novega stanja zbirke podatkov. SQL Server zazna spremembe, zaradi katerih se stanje načrta izvajanja spremeni v neveljavno, in označi načrt kot neveljavnega.
Sistem mora nato ustvariti nov paket za naslednjo povezavo, ki bo izvedla poizvedbo. Pogoji, zaradi katerih načrt postane neveljaven, vključujejo:
- Spremembe v tabeli ali pogledu, na katerega se sklicuje poizvedba (ALTER TABLE in ALTER VIEW).
- Spremembe indeksov, ki jih uporablja načrt izvajanja.
- Posodobitve statistike, ki jih uporablja načrt izvajanja in jih je izrecno ustvarila izjava, kot je UPDATE STATISTICS, oz. so bile ustvarjene samodejno.
Če želite več informacij, glejte Načrti izvajanja.
Shramba poizvedb
V shrambi poizvedb je na voljo vpogled v izbrani načrt izvajanja in učinkovitost delovanja. Omogoča lažje odpravljanje težav, saj vam pomaga hitro najti razlike v učinkovitosti delovanja, nastale zaradi sprememb načrta izvajanja. Shramba poizvedb zbira telemetrične podatke, kot so zgodovina poizvedb, načrte, statistiko izvajanja in statistiko čakanja. Če želite uveljaviti shrambo poizvedb, uporabite izjavo ALTER DATABASE:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Če želite več informacij, glejte Nadzorovanje učinkovitosti delovanja s shrambo poizvedb.
Samodejni popravek načrta
Morda je najpreprostejši način za izboljšanje učinkovitosti delovanja poizvedb s samodejnim popravkom načrta, ki je funkcija zbirke podatkov Azure SQL. Vklopite funkcijo in jo pustite, da se izvaja. Funkcija neprekinjeno nadzoruje in analizira načrt izvajanja, zaznava problematične načrte izvajanja in samodejno odpravlja težave z zmogljivostjo delovanja. V zakulisju funkcija samodejnega popravka načrta uporablja štiristopenjsko strategijo učenja, prilagajanja, preverjanja in ponovitve.
Če želite več informacij, glejte Samodejno prilagajanje.
Prilagodljiva obdelava poizvedb
Poizvedbe lahko pohitrite tudi tako, da nadgradite na SQL Server 2017 z novo funkcijo prilagodljive obdelave poizvedb. SQL Server prilagodi izbire načrtov poizvedb glede na značilnosti izvajalnika.
Funkcija ocene kardinalnosti določi približno število vrstic, ki jih sistem obdela ob vsakem koraku v načrtu izvajanja. Nenatančne ocene lahko povzročijo počasen odzivni čas poizvedbe, nenatančno uporabo virov (pomnilnik, CPE in IO) ter manjšo prepustnost ter sočasnost. Za prilagoditev značilnosti delovne obremenitve se uporabljajo tri tehnike:
- Povratne informacije o povratnih informacijah pomnilnika v paketnem načinu Slabe ocene kardinalnosti lahko povzročijo, da se poizvedbe »prelijejo na disk« ali povzročijo preveč pomnilnika. SQL Server 2017 na podlagi povratnih informacij o izvajanju prilagodi dodelitev pomnilnika, odstrani razlitja na diskih in zboljša prepustnost ponavljajočih se poizvedb.
- Prilagodljiva združevanja v paketnem načinu Prilagodljiva združevanja dinamično izbrali boljšo vrsto notranje združitve (ugnezdene združitve zanke, združevanje združevanj ali združevanje z lojčenjem) med izvajanjem na podlagi dejanskih vnosnih vrstic. Tako lahko načrt dinamično preklopi na boljšo strategijo združevanja med izvajanjem.
- Interleaved izvedba Funkcije z več izjavami v tabeli z vrednostmi so bile običajno s poizvedbo obdelane kot črno polje. SQL Server 2017 lahko bolje oceni število vrstic in tako izboljša strežniške operacije.
Omogočite raven združljivosti z vrednostjo 140 za zbirko podatkov, da bodo obremenitve samodejno primerne za prilagodljivo obdelavo poizvedb:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Če želite več informacij, glejte Pametna obdelava poizvedb v zbirkah podatkov SQL.
Načini pošiljanja poizvedb
V strežniku SQL Server je na voljo več načinov za pošiljanje poizvedb – vsak od njih ima svoje prednosti. Želite izvedeti, katere so te prednosti, da se boste lahko pravilno odločili za svojo rešitev v Accessu. Najboljši način za ustvarjanje poizvedb TSQL je interaktivno urejanje in preskušanje poizvedb z urejevalnikom transact-SQL strežnika SQL Server Management Studio (SSMS), ki ima intellisense za lažje izbiranje pravih ključnih besed in preverjanje napak v sintaksi.
Pogledi
V strežniku SQL Server pogled predstavlja navidezno tabelo, kjer so podatki o pogledu prikazani v eni ali več tabelah oziroma pogledih. Vendar imajo pogledi sklice tako kot tabele in poizvedbe. S pogledi lahko skrijete zapletenost poizvedb in zaščitite podatke tako, da omejite nabor vrstic ter stolpcev. V nadaljevanju si oglejte primer preprostega pogleda:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Če želite doseči optimalno učinkovitost delovanja in urediti rezultate pogleda, ustvarite indeksiran pogled, ki je vključen v zbirko podatkov kot tabela, ima dodeljen pomnilnik in zanj lahko hitro ustvarite poizvedbo, tako kot za poljubno tabelo. Če ga želite uporabiti v Accessu, se povežite s pogledom na enak način, kot bi povezali tabelo. Tukaj je primer indeksiranega pogleda:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Vendar obstajajo omejitve, ki jih je treba upoštevati. Podatkov ni mogoče posodobiti, če to vpliva na več osnovnih tabel ali če pogled vsebuje združevalne funkcije ali stavek DISTINCT. Če SQL Server vrne sporočilo o napaki, v katerem je navedeno, da ne ve, kateri zapis izbrisati, boste morda v pogled morali dodati sprožilec za brisanje. Prav tako ni mogoče uporabiti stavka ORDER BY, kot ga lahko pri Accessovi poizvedbi.
Če želite več informacij, glejte Poglediin Ustvarjanje indeksanih pogledov.
Shranjene procedure
Shranjena procedura je skupina ene ali več izjav TSQL, ki lahko vsebujejo vhodne parametre, vrnejo izhodne parametre in ponazorijo uspeh oz. napako z vrednostjo stanja. Delujejo kot vmesni sloj med Accessovim osprednjim strežnikom in zalednim strežnikom SQL Server. Shranjene procedure so lahko preproste, kot je izjava SELECT, ali zapletene, kot je zapleten poljuben program. Tukaj je primer:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Če v Accessu uporabite shranjeno proceduro, ta običajno vrne rezultat v obliki obrazca ali poročila. Lahko pa izvede druga dejanja, ki ne vrnejo rezultatov, na primer izjave DDL ali DML. Ko uporabite prepustno poizvedbo, se prepričajte, da ste ustrezno nastavili lastnost Vrne zapise.
Če želite več informacij, glejte Shranjene procedure.
Pogosti izrazi za tabele
Pogosti izrazi za tabele (CTE) so podobni začasni tabeli, ki ustvari poimenovani nabor rezultatov. Obstajajo samo za izvajanje posamezne poizvedbe ali izjave DML. Izrazi CTE so vgrajeni v isto vrstico kode kot izjava SELECT oziroma izjava DML, ki jih uporablja; ustvarjanje in uporaba začasne tabele oziroma pogleda pa je običajno dvostopenjski proces. Tukaj je primer:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
Izrazi CTE imajo več prednosti, vključno z naslednjimi:
- Ker so CTE prehodni, vam jih ni treba ustvariti kot trajne predmete zbirke podatkov, kot so pogledi.
- Za isti izraz CTE lahko ustvarite več sklicev v poizvedbi ali izjavi DML, tako da je vašo kodo mogoče lažje upravljati.
- Za določanje kazalca lahko uporabite poizvedbe, ki se sklicujejo na izraz CTE.
Če želite več informacij, glejte S common_table_expression.
Uporabniško določene funkcije
Z uporabniško določeno funkcijo (UFD) lahko izvajate poizvedbe in izračune ter vračate skalarne vrednosti oziroma nabore z rezultati podatkov. Imajo podobno funkcijo kot funkcije v programskih jezikih, v katere lahko posredujete parametre, omogočajo zapletene izračune in vrnejo rezultat dejanja v obliki vrednosti. Tukaj je primer:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
Funkcija UDF ima določene omejitve. Ne more na primer uporabiti določenih nedeterminističnih sistemskih funkcij, izvajati izjav DML ali DDL ali izvajati dinamičnih poizvedb SQL.
Če želite več informacij, glejte Uporabniško določene funkcije.
Dodajanje ključev in indeksov
Ne glede na sistem zbirke podatkov, ki ga uporabljate, so na voljo indeksi in ključi.
Tipke
V strežniku SQL Server se prepričajte, da ustvarite primarne ključe za posamezne tabele in tuje ključe za posamezne povezane tabele. Enakovredna funkcija Accessovi podatkovni vrsti AutoNumber v strežniku SQL je lastnost IDENTITY, s katero lahko ustvarjate vrednosti ključev. Ko uporabite to lastnosti v številskem stolpcu, se spremeni v samo za branje in jo vzdržuje sistem z zbirkami podatkov. Ko v tabelo, ki vsebuje stolpec IDENTITY vstavite zapis, sistem samodejno poviša vrednost stolpca IDENTITY za vrednost 1 (začne pri vrednosti 1), te vrednosti pa lahko nadzorujete z argumenti.
Če želite več informacij, glejte CREATE TABLE, IDENTITY (lastnost).
Indeksi
Izbira indeksov kot običajno določa hitrost poizvedbe in strošek posodobitve. V Accessu je na voljo ena vrsta indeksa, v strežniku SQL Server pa 12. Pri izbiranju indeksov si lahko pomagate z optimizatorjem poizvedb, s katerim boste izbrali najbolj učinkovitega. V storitvi Azure SQL lahko uporabite samodejno upravljanje indeksov – funkcijo samodejnega uglaševanja, ki za vas priporoča dodajanje ali odstranjevanje indeksov. Za razliko od Accessa morate ustvariti lastne indekse za tuje ključe v strežniku SQL Server. V indeksiranem pogledu lahko ustvarite tudi indekse, s katerimi izboljšate učinkovitost delovanja poizvedb. Obrnjena stran indeksanega pogleda je povečana nad glavo, ko spreminjate podatke v osnovnih tabelah pogleda, saj je treba posodobiti tudi pogled. Če želite več informacij, glejte SQL Server Za arhitekturo kazala in Navodila za oblikovanjein Indeksi.
Izvajanje transakcij
Izvajanje postopka spletne transakcije (OLTP) v Accessu je zapleteno, v strežniku SQL Server pa precej preprosto. Transakcija je posamezna enota dela, s katero potrdite vse spremembe podatkov, če je ta uspešna. V nasprotnem primeru pa povrnete na prejšnjo različico, če transakcija ni bila uspešna. Transakcija mora imeti štiri lastnosti, ki jih pogosto imenujemo ACID:
- Atomski način Transakcija mora biti atomska enota dela; ali se izvedejo vse spremembe podatkov ali pa se jih ne izvede.
- Doslednost Ko je transakcija dokončana, morajo biti vsi podatki v doslednem stanju. To pomeni, da so bila uporabljena vsa pravila za integriteto podatkov.
- Izolacija Spremembe, ki jih naredijo sočasne transakcije, so izolirane od trenutne transakcije.
- Trajnost Ko je transakcija dokončana, so spremembe trajne, tudi če pride do okvare sistema.
S transakcijo zagotovite integriteto podatkov, kot je dvig gotovine na bankomatu ali samodejno nakazilo plače. Izvajate lahko eksplicitne, implicitne ali paketne transakcije. V spodnjem razdelku si lahko ogledate dva primera TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Če želite več informacij, glejte Transakcije.
Uporaba omejitev in sprožilcev
Zbirke podatkov imajo različne načine za vzdrževanje celovitosti podatkov.
Omejitve
V Accessu lahko vsilite referenčno integriteto relacije tabele prek ključnih parov tuj ključ–primarni ključ, kaskadnih posodobitev in brisanj ter pravil za preverjanje. Če želite več informacij, glejte Vodnik za relacije tabel in Omejevanje vnosa podatkov s pravili za preverjanje.
V strežniku SQL Server lahko uporabite omejitvi UNIQUE in CHECK, ki predstavljata predmete zbirke podatkov, s katerimi je mogoče vsiliti celovitost podatkov v tabelah strežnika SQL Server. Če želite preveriti veljavnost vrednosti v drugi tabeli, uporabite omejitev tujega ključa. Če želite preveriti, ali je vrednost v stolpcu v določenem razponu, uporabite omejitev za preverjanje. Ti predmeti predstavljajo prvi sloj obrambe in so zasnovani tako, da delujejo učinkovito. Če želite več informacij, glejte Enolične omejitve in Omejitve za preverjanje.
Sprožilci
Access ne uporablja sprožilcev zbirk podatkov. V strežniku SQL Server lahko s sprožilci vsilite pravilna za celovitost zapletenih podatkov in za izvajanje te logike v strežniku. Sprožilec zbirke podatkov je shranjena procedura, ki se izvede ob določenem dejanju v zbirki podatkov. Sprožilec je dogodek, na primer dodajanje zapisa v tabelo ali brisanje zapisa iz nje, ki se aktivira in nato izvede shranjeno proceduro. Čeprav je v Accessovi zbirki podatkov mogoče zagotovi referenčno integriteto, ko uporabnik poskuša posodobiti podatke ali jih izbrisati, imate v strežniku SQL Server na voljo nabor izpopolnjenih sprožilcev. Sprožilec lahko programirate tako, da množično izbriše zapise in zagotovi celovitost podatkov. Sprožilce lahko celo dodate v tabele in poglede.
Če želite več informacij, glejte Sprožilci – DML, Sprožilci – DDL in Načrtovanje sprožilca T-SQL.
Uporaba izračunanih stolpcev
V Accessu lahko ustvarite izračunani stolpec tako, da ga dodate v poizvedbo in nato ustvarite izraz, na primer:
Extended Price: [Quantity] * [Unit Price]
Enakovredno funkcijo v strežniku SQL Server imenujemo izračunan stolpec, ki predstavlja navidezen stolpec, ki ni fizično shranjen v tabeli, razen če je stolpec označen z oznako PERSISTED. Izračunan stolpec v izrazu uporablja podatke iz drugih stolpcev. Če želite ustvariti izračunan stolpec, ga dodajte v tabelo. Primer:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
);
Če želite več informacij, glejte Določanje izračunanih stolpcev v tabeli.
Dodajanje časovnega žiga podatkom
Včasih dodate polje tabele, da zabeležite časovni žig, ko je zapis ustvarjen, da lahko zabeležite vnos podatkov. V Accessu lahko preprosto ustvarite stolpec z datumom s privzeto vrednostjo =Now(). Če želite datum ali čas zabeležiti v SQL Server, uporabite podatkovni tip datetime2 s privzeto vrednostjo za SYSDATETIME().
Opomba Ne zamešajte različice vrstice z dodajanjem časovnega žiga v podatke. Ključna beseda časovni žig je sopomenka za različico vrstice v strežniku SQL Server, vendar uporabite ključno besedo različica vrstice. V strežniku SQL Server je različica vrstice vrsta podatkov, ki razkrije samodejno ustvarjenja enolična dvojiška števila v zbirki podatkov, in se običajno uporablja kot mehanizem za dodeljevanje različic v vrsticah tabele. Vendar pa je vrsta podatkov različica vrstice samo naraščajoče število in ne ohrani datuma oz. časa ter ni namenjeno za dodajanje časovnega žiga v vrstico.
Če želite več informacij, glejte različice vrstic. Če želite izvedeti več o uporabi različice vrstice za minimiziranje sporov med zapisi, preberite Selitev Accessove zbirke podatkov v strežnik SQL Server.
Upravljanje velikih predmetov
V Accessu nestrukturirane podatke, kot so datoteke, fotografije in slike, upravljate z vrsto podatkov »Priloga«. V terminologiji za SQL Server se nestrukturirani podatki imenujejo zbirka dvojiških podatkov (velik dvojiški predmet), na voljo pa je več načinov za delo z njimi:
DATOTEČNI TOK Uporabi podatkovni tip varbinary(max) za shranjevanje nestrukturiranih podatkov v datotečno sistem in ne v zbirko podatkov. Če želite več informacij, glejte Accessovi datotečni podatki DATOTEČNI TOK s transact-SQL-om.
Datotečna tabela Shrani zbirke dvojiških podatkov v posebne tabele, imenovane datotečno tabele, in zagotavlja združljivost z aplikacijami sistema Windows, kot če bi bile shranjene v datotečno sistemom, ne da bi spremenili odjemalske programe. Datotečna tabela zahteva DATOEČNI TOK. Če želite več informacij, glejte Datotene tabele.
Remote BLOB store (RBS) Binarne velike predmete (zbirke dvojiških podatkov) shrani v rešitve shrambe blaga in ne neposredno v strežnik. S tem prihranite prostor in zmanjšate vire strojne opreme. Če želite več informacij, glejte Dvojiški podatki z velikimi predmeti (blob).
Delo s hierarhičnimi podatki
Čeprav so relacijske zbirke podatkov, kot je Access, zelo prilagodljive, delo z hierarhičnimi relacijami predstavlja izjemo in pogosto zahteva zapletene izjave ali kodo SQL. Primeri hierarhičnih podatkov vključujejo: organizacijsko strukturo, datotečni sistem, taksonomijo jezikovnih terminov in grafikon s povezavami do spletnih strani. SQL Server ima vgrajeno vrsto podatkov hierarchyid in nabor hierarhičnih funkcij za preprosto shranjevanje, pošiljanje poizvedb in upravljanje hierarhičnih podatkov.
 Če želite več informacij, glejte Hierarhični podatki in Vadnica: uporaba podatkovnega tipa hierarchyid.
Če želite več informacij, glejte Hierarhični podatki in Vadnica: uporaba podatkovnega tipa hierarchyid.
Spreminjanje besedila JSON
JavaScript Object Notation (JSON) je spletna storitev, ki uporablja berljivo besedilo za prenos podatkov v parih atribut-vrednost pri nesinhroni komunikaciji med brskalnikom in strežnikom. Primer:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access ne omogoča vgrajene funkcionalnosti za upravljanje podatkov JASON, v strežniku SQL Server pa lahko shranjujete, indeksirate, pošiljate poizvedbe in ekstrahirate podatke JSON. Besedilo JSON lahko pretvorite in ga shranite v tabelo oziroma podatke oblikujte kot besedilo JSON. Morda boste rezultate poizvedbe želeli oblikovati v obliki za JSON in jih prikazati v spletni aplikaciji oziroma dodati podatkovne strukture JSON v vrstice ter stolpce.
Opomba Funkcija JSON ni podprta v VBA-ju. Namesto tega lahko v VBA-ju uporabite XML s knjižnico MSXML.
Če želite več informacij, glejte Podatki JSON v SQL Server.
Viri
Zdaj je primeren trenutek, da izveste več o strežniku SQL Server in jeziku Transact SQL (TSQL). Kot ste videli, so na voljo številne funkcije, kot je Access, pa tudi zmogljivosti, ki jih Access preprosto nima. Če želite svoje znanje nadgraditi, si oglejte naslednje vire za učenje:
| Vir | Opis |
|---|---|
| Poizvediranje s transact-SQL-om | Videotečaj |
| Vadnice za mehanizem zbirke podatkov | Vadnice o strežniku SQL Server 2017 |
| Microsoft Learn | Izjemni viri za učenje za Azure |
| SQL Server usposabljanje in certificiranje | Postanite strokovnjak |
| SQL Server 2017 | Glavna ciljna stran |
| SQL Server Dokumentacija | Informacije pomoči |
| Azure dokumentacije zbirke podatkov SQL | Informacije pomoči |
| Osnovni vodnik za podatke v oblaku (e-knjiga) | Pregled oblaka |
| SQL Server 2017 Datasheet | Vizualni povzetek novih funkcij |
| Primerjava različice SQL Server Microsoft | Povzetek funkcij po različicah |
| Izdaje Microsoft SQL Server Express | Prenesite SQL Server Express 2017 |
| Vzorčne zbirke podatkov SQL | Prenesite vzorčne zbirke podatkov |