
Bu makalede, Microsoft Excel'de DOT işlevinin formül söz dizimi ve kullanımı açıklanmaktadır.
Açıklama
DOT işlevi, verilerinize en iyi uyan doğruyu hesaplamak için "en küçük kareler" yöntemini kullanarak doğrunun istatistiğini hesaplar ve ardından doğruyu tanımlayan bir diziyi verir. Ayrıca polinom, logaritma, üstel ve kuvvet serisi de dahil, bilinmeyen parametrelerde doğrusal olan başka model türleri için istatistiği hesaplamak amacıyla DOT işlevini diğer işlevlerle de birleştirebilirsiniz. Bu işlev bir değer dizisi verdiği için dizi formülü olarak girilmiş olmalıdır. Bu makalede, örneklerden sonra yönergeleri bulabilirsiniz.
Doğrunun denklemi:
y = mx + b
– veya –
y = m1x1 + m2x2 + ... + b
birden çok x değeri aralığı varsa, burada bağımlı y değerleri bağımsız x değerlerinin bir işlevidir. m değerleri her x değerine karşılık gelen katsayılardır ve b sabit bir değerdir. y, x ve m değerlerinin vektör olabileceğini unutmayın. DOT işlevinin döndürdüğü dizi: {mn,mn-1,...,m1,b}. DOT ek regresyon istatistikleri de döndürebilir.
Söz dizimi
DOT (Bilinen_y'ler, [bilinen_x'ler], [sabit], [konum])
DOT işlevinin söz diziminde aşağıdaki bağımsız değişkenler bulunur:
Söz dizimi
-
bilinen_y'ler Gerekli. Y = mx + b ilişkisinde önceden bildiğiniz y değerleri kümesi.
-
Bilinen_y'ler aralığı tek bir sütundaysa, bilinen_x'lerin her sütunu ayrı bir değişken olarak yorumlanır.
-
Bilinen_y'ler aralığı tek bir satırda yer alıyorsa, bilinen_x'lerin her satırı ayrı bir değişken olarak yorumlanır.
-
-
bilinen_x'ler İsteğe bağlı. Y = mx + b ilişkisinde önceden bildiğiniz isteğe bağlı x değerleri kümesi.
-
Bilinen_x'ler aralığı bir veya daha fazla değişken kümesi içerebilir. Yalnızca bir değişken kullanılıyorsa, bilinen_y'ler ve bilinen_x'ler eşit boyutlarda olmak koşuluyla herhangi bir şekildeki aralıklar olabilir. Birden fazla değişken kullanılıyorsa, bilinen_y'ler bir vektör olmalıdır (bir satır yüksekliğinde veya bir sütun genişliğinde bir aralık).
-
Bilinen_x'ler belirtilmezse, bilinen_y'lerle aynı büyüklükte olan {1,2,3,...} dizisi olmalıdır.
-
-
Sabit İsteğe bağlı. b sabitinin 0 olup olmayacağını belirten mantıksal bir değerdir.
-
Sabit DOĞRU'ysa veya belirtilmemişse, b normal şekilde hesaplanır.
-
Sabit YANLIŞ ise, b 0'a eşit olarak belirlenir ve m değerleri y = mx denklemine uyacak şekilde ayarlanır.
-
-
Konum İsteğe bağlı. Ek gerileme istatistiklerinin verilip verilmeyeceğini belirleyen mantıksal değer.
-
İstatistikler DOĞRU ise, DOT ek regresyon istatistiklerini verir; sonuç olarak, döndürülen dizi {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Konum YANLIŞ veya atlanırsa, DOT yalnızca m katsayısını ve b sabitini verir.
Ek regresyon istatistikleri aşağıdaki gibi olur.
-
|
İstatistik |
Açıklama |
|---|---|
|
sh1;sh2;...;shn |
m1;m2;...;mn katsayıları için standart hata değerleri. |
|
shb |
b sabiti için standart hata değeri (shb = #YOK sabit YANLIŞ ise). |
|
r2 |
Benzerlik katsayısıdır. Gerçek ve tahmin edilen y değerlerini karşılaştırır 0'dan 1'e kadar değeri düzenler. Değer 1 ise, örnekte mükemmel bir korelasyon vardır (tahmin edilen y değeri ile gerçek y değeri arasında fark yoktur). Diğer uç değerde, benzerlik katsayısı 0 ise, regresyon denklemi öngörülen y değerinde yararlı değildir. 2'nin nasıl hesaplanmış olduğu hakkında bilgi için bu konunun devamında yer alan "Açıklamalar" bölümüne bakın. |
|
shy |
y tahmin değeri için standart hata. |
|
F |
F istatistik veya F gözlenen değer. Rastlantıyla oluşan bağımlı ve bağımsız değişkenler arasındaki ilişkinin gözlenip gözlenmediğini belirlemek için F istatistiğini kullanın. |
|
sd |
Serbestlik derecesi. Serbestlik derecelerini, istatistiksel tabloda F- kritik değerlerini bulmanıza yardım etmesi için kullanın. Modelin güvenlik düzeyini belirlemek için DOT tarafından verilen F istatistik değerleri için tabloda bulduğunuz değerleri karşılaştırın. sd'nin nasıl hesaplandığı hakkında bilgi için bu konu içinde, aşağıdaki "Açıklamalar" bölümüne bakın. Aşağıdaki Örnek 4'te, F ve sd'nin kullanılışı gösterilmektedir. |
|
ssreg |
Regresyon karelerinin toplamı. |
|
ssresid |
Karelerin toplamının artığıdır. ssreg ve ssresid hesaplaması hakkında bilgi edinmek için bu konudaki "Notlar" bölümüne bakın. |
Aşağıdaki örnek ek regresyon istatistiklerinin verildiği sırayı gösterir.

Notlar
-
Herhangi bir düz doğrunun eğimini ve y kesişim noktasını tanımlayabilirsiniz:
Eğim (m):
Genellikle m olarak yazılan bir çizginin eğimini bulmak için, çizgi üzerinde iki nokta alın, (x1,y1) ve (x2,y2); eğim (y2 - y1)/(x2 - x1) değerine eşittir.Y-kesme noktası (b):
Bir çizginin y-kesme noktası, genellikle b olarak yazılır, çizginin y eksenini geçtiği noktadaki y değeridir.Düz çizginin denklemi y = mx + b'dir. m ve b değerlerini bildiğinizde, y veya x değerini bu denkleme takarak satırdaki herhangi bir noktayı hesaplayabilirsiniz. EĞİlİM işlevini de kullanabilirsiniz.
-
Yalnızca bir tane bağımsız x değişkeniniz varsa, aşağıdaki formülleri kullanarak doğrudan eğimi ve y kesişim noktası değerlerini elde edebilirsiniz:
Yamaç:
=İNDİS(DOT(known_y,known_x),1)Y-kesme noktası:
=İNDİS(DOT(known_y,known_x),2) -
DOT tarafından hesaplanan doğrunun doğruluğu verilerinizdeki dağılım derecesine bağlıdır. Veri ne kadar doğrusalsa, DOT modeli o kadar doğru olur. DOT, verilerinize en iyi uyan doğruyu belirlemek için en küçük kareler yöntemini kullanır. Yalnızca bir tane bağımsız x değişkeniniz varsa, m ve b değerlerinin hesaplamaları aşağıdaki formülleri esas alır:
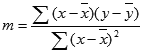
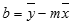
burada x ve y örnek ortalamalardır; yani x = ORTALAMA(bilinen x'ler) ve y = ORTALAMA((bilinen_y'ler).
-
Line ve curve-fit işlevleri DOT ve LOGEST , verilerinize uyan en iyi düz çizgiyi veya üstel eğriyi hesaplayabilir. Ancak, verilerinize en uygun iki sonuçtan hangisinin bulunduğuna karar vermeniz gerekir. Düz bir çizgi için EĞİlİM(known_y,known_x) veya üstel eğri için BÜYÜME(known_y, known_x) hesaplayabilirsiniz. Bu işlevler, new_x bağımsız değişkeni olmadan, gerçek veri noktalarınızda bu çizgi veya eğri boyunca tahmin edilen bir y değerleri dizisi döndürür. Ardından tahmin edilen değerleri gerçek değerlerle karşılaştırabilirsiniz. Görsel karşılaştırma için her ikisini de grafiğini oluşturmak isteyebilirsiniz.
-
Regresyon çözümlemesinde, Excel, her bir nokta için o noktanın tahmin edilen y değeriyle gerçek y değeri arasındaki karesi alınmış farkı hesaplar. Bu kareleri alınmış farkların toplamına kareler toplamının artığı, yani ssresid denir. Daha sonra Excel, toplam kareler toplamı olan sstotal değerini hesaplar. Sabit bağımsız değişken = DOĞRU olduğunda veya atlandığında toplam kareler toplamı, y değerlerinin ortalaması ile gerçek y değerleri arasındaki kareleri alınmış farkların toplamıdır. Sabit bağımsız değişken = YANLIŞ olduğunda toplam kareler toplamı, gerçek y değerlerinin karelerinin toplamıdır (her bir y değerinden ortalama y değerini çıkarmadan). Karelerin regresyon toplamı olan ssreg şöyle bulunabilir: ssreg = sstotal - ssresid. Karelerin artık toplamı ne kadar küçük olursa, toplam kare toplamıyla karşılaştırıldığında, belirleme katsayısının değeri o kadar büyük olur, r2, regresyon analizinden kaynaklanan denklemin değişkenler arasındaki ilişkiyi ne kadar iyi açıkladığının göstergesidir. r2 değeri ssreg/sstotal değerine eşittir.
-
Bazı durumlarda, X sütunlarından biri veya daha fazlası (Y'ler ve X'ler sütunlarda yer alır) diğer X sütunlarının varlığında ek tahmine dayalı değere sahip olmayabilir. Başka bir deyişle, bir veya daha fazla X sütunun ortadan kaldırılması, eşit oranda doğru tahmin edilen Y değerlerine yol açabilir. Bu durumda bu yedekli X sütunları regresyon modelinden atlanmalıdır. Yedekli X sütunları, yedekli olmayan X sütunlarının katlarının toplamı olarak ifade edilebileceğinden bu fenomene "kollineerlik" adı verilir. DOT işlevi, eş doğrusallığı denetler ve bunları tanımladığında regresyon modelinden yedekli X sütunlarını kaldırır. Kaldırılan X sütunları DOT çıkışında 0 se değerine ek olarak 0 katsayıya sahip olarak tanınabilir. Bir veya daha fazla sütun yedekli olarak kaldırılırsa, df tahmine dayalı amaçlar için kullanılan X sütun sayısına bağlı olduğundan bu durumdan etkilenir. df hesaplamasının ayrıntıları için bkz . Örnek 4. Yedekli X sütunları kaldırıldığı için df değiştirilirse sey ve F değerleri de etkilenir. Kolinerite pratikte nispeten nadir olmalıdır. Bununla birlikte, bazı X sütunlarının denemedeki bir konunun belirli bir grubun üyesi olup olmadığının göstergesi olarak yalnızca 0 ve 1 değerleri içermesi durumunda ortaya çıkması daha olasıdır. Const = TRUE ise veya atlanırsa, DOT işlevi kesme noktasını modellemek için 1 değerin tümüne ek bir X sütunu ekler. Erkekse her konu için 1 veya değilse 0 içeren bir sütuna sahipseniz ve ayrıca kadınsa her konu için 1 veya değilse 0 içeren bir sütuna sahipseniz, bu ikinci sütun yedeklidir, çünkü içindeki girdiler" erkek göstergesi" sütunundaki girdinin DOT işlevi tarafından eklenen tüm 1 değerin ek sütunundaki girdiden çıkarılarak elde edilebilir.
-
Eşdoğrusallık nedeniyle modelden hiçbir X sütunu çıkarılmadığında, sd'nin değeri şöyle hesaplanır: k sayıda bilinen_x'ler sütunu varsa ve sabit = DOĞRU ise veya atlanmışsa, sd = n – k – 1 olur. Sabit = YANLIŞ olduğunda, sd = n - k olur. Her iki durumda da, eşdoğrusallık nedeniyle çıkarılan her X sütunu sd'nin sayısını 1 artırır.
-
Dizi sabiti (örneğin bilinen_x'ler) bağımsız değişken olarak girildiğinde, aynı satırda yer alan değerleri ayırmak için virgül ve satırları ayırmak için noktalı virgül kullanın. Ayırıcı karakterler bölgesel ayarlara dayanarak farklı olabilir.
-
Denklemi belirlemek için kullandığınız y değerleri aralık dışındaysa regresyon denklemi tarafından öngörülen y değerlerinin geçerli olmayabileceğini unutmayın.
-
DOT işlevinde kullanılan temel algoritma KESMENOKTASI ve EĞİM işlevlerinde kullanılan temel algoritmadan farklıdır. Bu algoritmalar arasındaki farklılık veri tanımsız ve aynı doğrultu üzerindeyse farklı sonuçlara neden olabilir. Örneğin, bilinen_y'ler bağımsız değişkenine ait veri noktaları 0; bilinen_x'ler bağımsız değişkenine ait veri noktaları da 1 ise:
-
DOT 0 değerini verir. DOT işlevinin algoritması aynı doğrultu üzerindeki verilerin akılcı sonuçlarını vermek için tasarlanmıştır; bu durumda da en az bir yanıt bulunabilir.
-
EĞİM ve KESMENOKTASI #SAYI/0! hatası verir. EĞİM ve KESMENOKTASI işlevlerinin algoritması tek bir yanıt aramak için tasarlanmıştır; bu durumdaysa birden çok yanıt vardır.
-
-
Diğer regresyon türleri için istatistiği hesaplamak amacıyla LOT'u kullanmaya ek olarak, diğer regresyon türlerinin aralığını hesaplamak üzere, DOT için x ve y dizisi olarak x ve y değişkenlerini girerek DOT'u kullanabilirsiniz. Örneğin:
=DOT(ydeğerleri, xdeğerleri^SÜTUN($A:$C))
formun kübik yuvarlamasını hesaplamak için (3 sırasının polinomu) tek y-değerleri sütununuz ve tek x-değerleri sütununuz olduğunda çalışır:
y = m1*x + m2*x^2 + m3*x^3 + b
Bu formülü başka tür regresyonları hesaplamak için uyarlayabilirsiniz, ancak bazı durumlarda çıktı değerlerinin ve başka istatistiklerin uyarlanması gerekir.
-
FTEST işlevinin verdiği F-test değeri DOT işlevinin verdiği F-test değerinden farklıdır. DOT F istatistiğini verirken FTEST de olasılığı verir.
Örnekler
Örnek 1 - Eğim ve Y Kesişim Noktası
Aşağıdaki tabloda yer alan örnek verileri kopyalayın ve yeni bir Excel çalışma sayfasının A1 hücresine yapıştırın. Formüllerin sonuçları göstermesi için, bunları seçip F2 tuşuna basın ve sonra Enter tuşuna basın. Gerekirse, tüm verileri görmek için sütun genişliğini ayarlayabilirsiniz.
|
Bilinen y |
Bilinen x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Sonuç (eğim) |
Sonuç (y-kesişim noktası) |
|
2 |
1 |
|
Formül (A7:B7 hücrelerindeki dizi formülü) |
|
|
=DOT(A2:A5,B2:B5,,YANLIŞ) |
Örnek 2 - Basit Doğrusal Regresyon
Aşağıdaki tabloda yer alan örnek verileri kopyalayın ve yeni bir Excel çalışma sayfasının A1 hücresine yapıştırın. Formüllerin sonuçları göstermesi için, bunları seçip F2 tuşuna basın ve sonra Enter tuşuna basın. Gerekirse, tüm verileri görmek için sütun genişliğini ayarlayabilirsiniz.
|
Ay |
Satış |
|---|---|
|
1 |
3.100 TL |
|
2 |
4.500 TL |
|
3 |
4.400 TL |
|
4 |
5.400 TL |
|
5 |
7.500 TL |
|
6 |
8.100 TL |
|
Formül |
Sonuç |
|
=TOPLA(DOT(B1:B6, A1:A6)*{9,1}) |
11.000 TL |
|
1 - 6 arası aylarda yapılan satışlara dayanarak, dokuzuncu aydaki satış tahminini hesaplar. |
Örnek 3 - Birden Çok Doğrusal Regresyon
Aşağıdaki tabloda yer alan örnek verileri kopyalayın ve yeni bir Excel çalışma sayfasının A1 hücresine yapıştırın. Formüllerin sonuçları göstermesi için, bunları seçip F2 tuşuna basın ve sonra Enter tuşuna basın. Gerekirse, tüm verileri görmek için sütun genişliğini ayarlayabilirsiniz.
|
Kaplanan alan (x1) |
Bürolar (x2) |
Girişler (x3) |
Yaş (x4) |
Biçilen değer (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142.000 TL |
|
2333 |
2 |
2 |
12 |
144.000 TL |
|
2356 |
3 |
1,5 |
33 |
151.000 TL |
|
2379 |
3 |
2 |
43 |
150.000 TL |
|
2402 |
2 |
3 |
53 |
139.000 TL |
|
2425 |
4 |
2 |
23 |
169.000 TL |
|
2448 |
2 |
1,5 |
99 |
126.000 TL |
|
2471 |
2 |
2 |
34 |
142.900 TL |
|
2494 |
3 |
3 |
23 |
163.000 TL |
|
2517 |
4 |
4 |
55 |
169.000 TL |
|
2540 |
2 |
3 |
22 |
149.000 TL |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formül (A19'a girilen dinamik dizi formülü) |
||||
|
=DOT(E2:E12,A2:D12,DOĞRU,DOĞRU) |
Örnek 4 - F ve r2 İstatistiklerini Kullanma
Yukarıdaki örnekte, belirleme katsayısı (r2) 0,99675'tir ( DOT için çıktıdaki A17 hücresine bakın), bu da bağımsız değişkenler ile satış fiyatı arasında güçlü bir ilişki olduğunu gösterir. Rastlantıyla oluşan örneğin büyük r2 değeriyle bu sonuçları belirlemek için F istatistiğini kullanabilirsiniz.
Bir an için aslında değişkenler arasında ilişki olmadığını, ancak güçlü bir ilişkiyi kanıtlamak için istatistiksel çözümlemelere neden olan 11 işyeri binasının nadir örneğini çizdiğinizi varsayın. "Alfa" terimi ilişkisi olan son hatalı olasılık için kullanılır.
DOT işlevinden elde edilen çıktısındaki F ve sd, rastlantıyla daha yüksek bir F değerinin ortaya çıkması olasılığını değerlendirmek için kullanılabilir. F, yayımlanmış F dağılımı tablolarındaki kritik değerlerle karşılaştırılabilir veya rastlantıyla daha büyük bir F değerinin ortaya çıkması olasılığını hesaplamak için Excel'in FDAĞ işlevi kullanılabilir. Uygun F dağılımının serbestlik derecesi v1 ve v2'dir. n, veri noktalarının sayısı ise ve sabit = DOĞRU ise veya atlanmışsa, v1 = n – sd – 1 ve v2 = sd. (Sabit = YANLIŞ ise, v1 = n – sd ve v2 = sd.) FDAĞ(F;v1;v2) söz dizimiyle kullanılan FDAĞ işlevi rastlantıyla daha yüksek bir F değerinin ortaya çıkması olasılığını verir. Bu örnekte, sd = 6 (hücre B18) ve F = 459,753674 (hücre A18).
Alfa değeri olarak 0,05, v1 = 11 – 6 – 1 = 4 ve v2 = 6 kabul edildiğinde, F'nin kritik düzeyi 4,53'tür. F = 459,753674'ün 4,53'ten çok daha yüksek olması nedeniyle, bu kadar yüksek bir F değerinin rastlantıyla ortaya çıkması pek olası değildir. (Alfa = 0,05 olduğunda, bilinen_y'ler ile bilinen _x'ler arasında bir ilişki olmadığı varsayımı, F, kritik düzey değeri 4,53'ü aştığında reddedilir.) Excel'in FDAĞ işlevini kullanarak, bu kadar yüksek bir F değerinin rastlantıyla ortaya çıkması olasılığını elde edebilirsiniz. Örneğin, FDAĞ(459,753674, 4, 6) = 1,37E-7, aşırı ölçüde düşük bir olasılıktır. F'nin kritik düzeyini tabloda bularak veya FDAĞ işlevini kullanarak, bu bölgedeki işyeri binalarının biçilen değerinin tahmin edilmesinde regresyon denkleminin yararlı olduğu sonucuna varabilirsiniz. Önceki paragrafta hesaplanan v1 ve v2 için doğru değerler kullanılmasının kritik olduğunu unutmayın.
Örnek 5 - T-istatistiklerini Hesaplama
Başka varsayım sınaması, Örnek 3'teki işyeri binasının tahmin edilen biçilen değerinde her bir eğim katsayısının yararlı olup olmayacağını belirleyecek. Örneğin, istatistiksel anlamda yaş katsayısını sınamak için -234,24 (yaş eğim katsayısı) 13,268'e (A15 hücresindeki yaş katsayılarının tahmin edilen standart hatası) bölün. Aşağıdaki t gözlenen değerdir:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
t'nin mutlak değeri yeterince yüksekse, eğim katsayısının, Örnek 3'teki işyeri binasının biçilen değerinin tahmininde yararlı olduğu sonucuna varılabilir. Aşağıdaki tablo, 4 t-gözlem değerinin mutlak değerlerini göstermektedir.
İstatistik kılavuzundaki bir tabloya başvurursanız, 6 serbestlik derecesi olan iki kuyruklu t-kritik ve Alfa = 0,05 değerinin 2,447 olduğunu göreceksiniz. Bu kritik değer, Excel'deki TTERS işlevi kullanılarak da bulunabilir. TTERS(0,05,6) = 2,447. T'nin mutlak değeri (17,7) 2,447'den büyük olduğundan, ofis binasının değerlendirilen değeri tahmin edilirken yaş önemli bir değişkendir. Diğer bağımsız değişkenlerin her biri istatistiksel anlamlılık açısından benzer şekilde test edilebilir. Bağımsız değişkenlerin her biri için t gözlemlenen değerler aşağıdadır.
|
Değişken |
t gözlenen değer |
|---|---|
|
Kaplanan alan |
5,1 |
|
Büro sayısı |
31,3 |
|
Giriş sayısı |
4,8 |
|
Yaş |
17,7 |
Bu değerlerin mutlak değeri 2,447'den büyüktür; bu nedenle, regresyon denkleminde kullanılan tüm değişkenler bu alandaki işyeri binalarının öngörülen biçilen değerinde kullanışlı olur.









