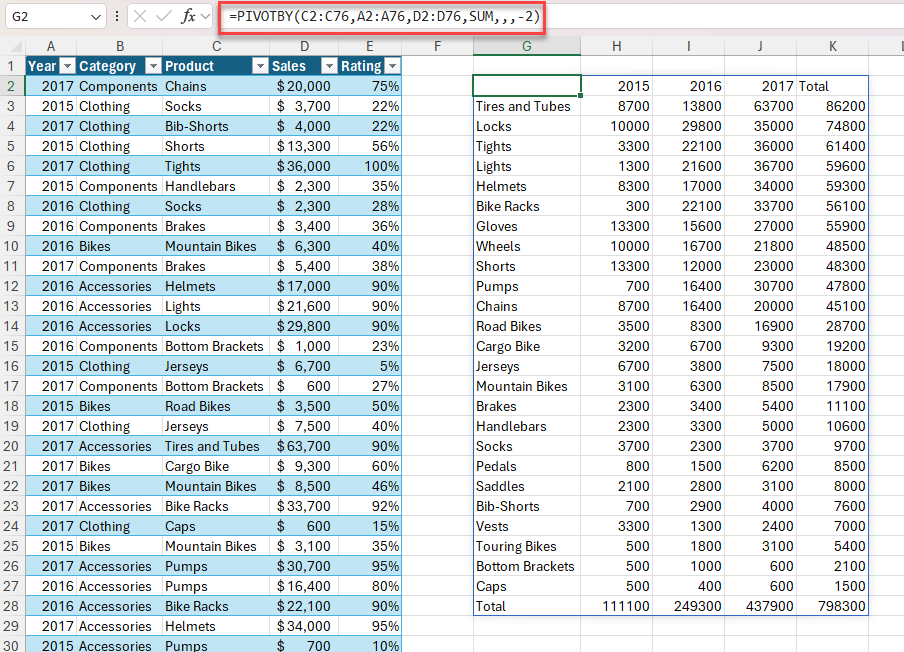
PIVOTBY işlevi, bir formül aracılığıyla verilerinizin özetini oluşturmanıza olanak tanır. İki eksen boyunca gruplandırma ve ilişkili değerleri toplamayı destekler. Örneğin, satış verileri tablosuna sahipseniz, eyalete ve yıla göre satışların bir özetini oluşturabilirsiniz.
Not: PIVOTBY, kılavuza taşabilen bir değer dizisi döndüren bir işlevdir. PIVOTBY ve PivotTable'larla ilgili bir tartışmayı burada bulabilirsiniz.
Söz dizimi
PIVOTBY işlevi, belirttiğiniz satır ve sütun alanlarına göre verileri gruplandırmanıza, toplamanıza, sıralamanıza ve filtrelemenize olanak tanır.
PIVOTBY işlevinin söz dizimi:
PIVOTBY(row_fields,col_fields,değerler,işlev,[field_headers],[row_total_depth],[row_sort_order],[col_total_depth],[col_sort_order],[filter_array])
|
Bağımsız değişken |
Açıklama |
|---|---|
|
row_fields (gerekli) |
Satırları gruplandırmak ve satır üst bilgileri oluşturmak için kullanılan değerleri içeren sütun odaklı bir dizi veya aralık. Dizi veya aralık birden çok sütun içerebilir. Öyleyse, çıkış birden çok satır grubu düzeyine sahip olur. |
|
col_fields (gerekli) |
Sütunları gruplandırmak ve sütun üst bilgileri oluşturmak için kullanılan değerleri içeren sütun odaklı bir dizi veya aralık. Dizi veya aralık birden çok sütun içerebilir. Bu durumda çıkış birden çok sütun grubu düzeyine sahip olur. |
|
Değer (gerekli) |
Toplanan verilerin sütun odaklı dizisi veya aralığı. Dizi veya aralık birden çok sütun içerebilir. Bu durumda, çıkışta birden çok toplama olur. |
|
Işlev (gerekli) |
Değerlerin nasıl toplandığını tanımlayan lambda işlevi veya eta azaltılmış lambda (TOPLA, ORTALAMA, SAY vb.). Lambda vektörleri sağlanabilir. Bu durumda, çıkışta birden çok toplama olur. Vektörün yönü, satır veya sütun açısından yerleştirilip yerleştirilmediklerini belirler. |
|
field_headers |
row_fields, col_fields ve değerlerin üst bilgileri olup olmadığını ve sonuçlarda alan üst bilgilerinin döndürülip döndürülmeyeceğini belirten bir sayı. Olası değerler şunlardır:
Eksik: Otomatik. Not: Otomatik, verilerin değerler bağımsız değişkenine göre üst bilgiler içerdiğini varsayar. 1. değer metin ve 2. değer bir sayıysa, verilerin üst bilgileri olduğu varsayılır. Birden çok satır veya sütun grubu düzeyi varsa alan üst bilgileri gösterilir. |
|
row_total_depth |
Satır üst bilgilerinin toplamlar içerip içermeyeceğini belirler. Olası değerler şunlardır:
Eksik: Otomatik: Genel toplamlar ve mümkün olduğunda alt toplamlar. Not: Alt toplamlar için row_fields en az 2 sütun olmalıdır. Yeterli sütuna sahip row_field 2'den büyük sayılar desteklenir. |
|
row_sort_order |
Satırların nasıl sıralanacağını gösteren bir sayı. Sayılar , row_fields'daki sütunlara karşılık gelir ve ardından değerlerdeki sütunlara karşılık gelir. Sayı negatifse, satırlar azalan/ters sırada sıralanır. Yalnızca row_fields göre sıralama yaparken sayı vektörleri sağlanabilir. |
|
col_total_depth |
Sütun üst bilgilerinin toplamlar içerip içermeyeceğini belirler. Olası değerler şunlardır:
Eksik: Otomatik: Genel toplamlar ve mümkün olduğunda alt toplamlar. Not: Alt toplamlar için col_fields en az 2 sütun olmalıdır. Yeterli sütuna sahip col_field 2'den büyük sayılar desteklenir. |
|
col_sort_order |
Satırların nasıl sıralanacağını gösteren bir sayı. Sayılar , col_fields sütunlarını ve ardından değerlerdeki sütunları gösterir. Sayı negatifse, satırlar azalan/ters sırada sıralanır. Yalnızca col_fields göre sıralama yaparken sayı vektörleri sağlanabilir. |
|
filter_array |
İlgili veri satırının dikkate alınması gerekip gerekmediğini belirten sütun odaklı 1B Boole dizisi. Not: Dizinin uzunluğu, row_fields vecol_fields için sağlananların uzunluğuyla eşleşmelidir. |
Örnekler
Örnek 1: Ürüne ve yıla göre toplam satışların özetini oluşturmak için PIVOTBY kullanın.
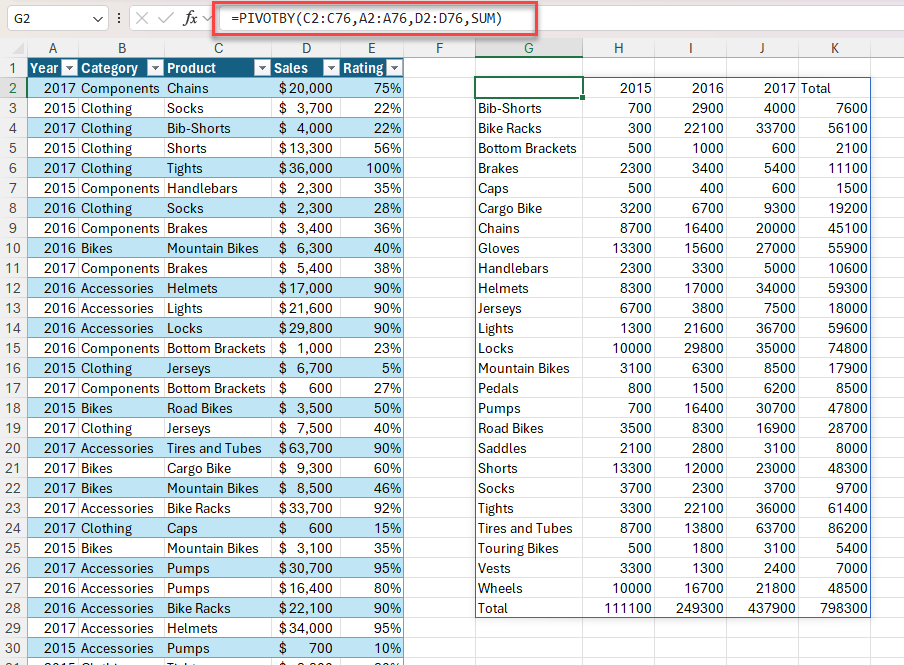
Örnek 2: Ürüne ve yıla göre toplam satışların özetini oluşturmak için PIVOTBY kullanın. Azalan düzende satışlara göre sıralama.