
تصف هذه المقالة بناء جملة صيغة الدالة LINEST واستخدامها في Microsoft Excel.
الوصف
تقوم الدالة LINEST بحساب الإحصاءات لخط باستخدام طريقة "المربعات الصغرى" لحساب خط مستقيم يناسب بياناتك بالشكل الأمثل، ثم تُرجع صفيفاً يصف الخط. يمكنك أيضاً دمج LINEST مع الدالات الأخرى لحساب إحصاءات أنواع أخرى من النماذج الخطية في المعلمات غير المعروفة، بما في ذلك المتسلسلة المتعددة الحدود، واللوغاريتمية، والأسية. ولأن هذه الدالة تقوم بإرجاع صفيف قيم، يجب إدخالها كصيغة صفيف. وتأتي الإرشادات بعد الأمثلة في هذا المقال.
معادلة الخط هي:
y = mx + b
– أو –
y = m1x1 + m2x2 + ... + b
إذا كانت هناك نطاقات متعددة من قيم x، حيث تكون قيم y التابعة هي دالة لقيم x المستقلة. قيم m عبارة عن مُعاملات مطابقة لكل قيمة من قيم x، وتكون b قيمة ثابتة. لاحظ أن y وx وm يمكن أن تكون متجهات. والصفيف الذي تقوم الدالة LINEST بإرجاعه هو {mn,mn-1,...,m1,b}. كما يمكن أن تقوم الدالة LINEST بإرجاع إحصاءات انحدار إضافية.
بناء الجملة
LINEST(known_y's, [known_x's], [const], [stats])
يحتوي بناء جملة الدالة LINEST على الوسيطات التالية:
بناء الجملة
Known_y's مطلوب. مجموعة قيم y التي تعرفها مسبقاً في العلاقة y = mx + b.
- إذا كان نطاق known_y في عمود واحد، يتم تفسير كل عمود من known_x على أنه متغير منفصل.
- إذا كان نطاق known_y مضمنا في صف واحد، يتم تفسير كل صف من known_x كمتغير منفصل.
Known_x's الاختياري. مجموعة قيم x التي تعرفها مسبقاً في العلاقة y = mx + b.
- يمكن أن يتضمن نطاق known_x مجموعة واحدة أو أكثر من المتغيرات. إذا تم استخدام متغير واحد فقط، يمكن أن تكون known_yknown_x نطاقات من أي شكل، طالما أن لها أبعادا متساوية. إذا تم استخدام أكثر من متغير واحد، يجب أن يكون known_y متجها (أي نطاق بارتفاع صف واحد أو عرض عمود واحد).
- إذا تم حذف known_x ، فمن المفترض أن يكون الصفيف {1,2,3,...} الذي هو نفس حجم known_y.
Const الاختياري. قيمة منطقية تحدد ما إذا كان سيتم فرض الثابت b ليساوي 0.
- إذا كان const TRUE أو تم حذفه، يتم حساب b بشكل طبيعي.
- إذا كان const هو FALSE، يتم تعيين b يساوي 0 ويتم ضبط قيم m لتناسب y = mx.
احصائيات الاختياري. قيمة منطقية تحدد ما إذا كان سيتم إرجاع إحصاءات انحدار إضافية.
- إذا كانت الإحصائيات TRUE، فترجع الدالة LINEST إحصائيات الانحدار الإضافية؛ نتيجة لذلك، الصفيف الذي تم إرجاعه هو {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
- إذا كانت الإحصائيات FALSE أو تم حذفها، فترجع LINEST معاملات m فقط والثابت b.
تكون إحصاءات الانحدار الإضافية كما يلي.
| الإحصاء | الوصف |
|---|---|
| se1,se2,...,sen | قيم الخطأ المعيارية للمُعاملات m1,m2,...,mn. |
| seb | قيمة الخطأ القياسية للثابت b (seb = #N/A عندما تكون const FALSE). |
| r2 | مُعامل التحديد. مقارنة قيم y المقدرة والفعلية، وتتراوح بالقيمة من صفر إلى 1. إذا كانت قيمتها 1، يوجد ارتباط تام في العينة — لا يوجد فرق بين قيمة y المقدرة وقيمة y الفعلية. ومن ناحية أخرى، إذا كانت قيمة معامل التحديد 0، فلا تفيد معادلة الانحدار في التكهن بقيمة y. للحصول على معلومات حول كيفية حساب2 ، راجع "ملاحظات"، لاحقا في هذا الموضوع. |
| sey | الخطأ المعياري لتقدير y. |
| F | الإحصائية F، أو قيمة F التي تمت ملاحظتها. استخدم الإحصائية F لتحديد ما إذا كانت العلاقة التي تمت ملاحظتها بين المتغيرات التابعة والمتغيرات المستقلة تحدث بالصدفة. |
| df | درجات الحرية. استخدم درجات الحرية لتساعدك في العثور على قيم F الهامة في جدول إحصائي. قارن القيم التي تجدها في الجدول بالإحصائية F التي تُرجعها الدالة LINEST لتحديد مستوى الثقة للنموذج. لمزيد من المعلومات حول كيفية حساب df، راجع "ملاحظات" لاحقاً في هذا الموضوع. يعرض المثال 4 كيفية استخدام F وdf. |
| ssreg | مجموع الانحدار للمربعات. |
| ssresid | باقي مجموع المربعات. لمزيد من المعلومات حول كيفية حساب ssreg وssresid، راجع "ملاحظات" لاحقاً في هذا الموضوع. |
يعرض الرسم التوضيحي التالي ترتيب إرجاع إحصاءات الانحدار الإضافية.

ملاحظات
يمكنك وصف أي خط مستقيم بالميل وتقاطع y:
المنحدر (m):
للعثور على ميل خط، غالبا ما تتم كتابته ك m، خذ نقطتين على السطر، (x1,y1) و (x2,y2)؛ الميل يساوي (y2 - y1)/(x2 - x1).
Y-intercept (b):
التقاطع ص للخط، الذي يكتب غالبا على أنه b، هو قيمة y عند النقطة التي يعبر فيها الخط المحور ص.
معادلة الخط المستقيم هي y = mx + b. بمجرد معرفة قيم m وb، يمكنك حساب أي نقطة على الخط بواسطة تضمين قيمة y أو x في تلك المعادلة. ويمكنك أيضاً استخدام الدالة TREND.عندما يتوفر لديك متغير x مستقل واحد فقط، يمكنك الحصول على قيم الميل وتقاطع y مباشرةً باستخدام الصيغ التالية:
المنحدر:
=INDEX(LINEST(known_y,known_x),1)
Y-intercept:
=INDEX(LINEST(known_y,known_x),2)تعتمد دقة الخط الذي تم حسابه بواسطة الدالة LINEST على درجة التبعثر في بياناتك. كلما كانت البيانات أكثر خطية، زادت دقة نموذج LINEST. تستخدم LINEST طريقة المربعات الصغرى لتحديد الشكل الأمثل للبيانات. وعندما يتوفر لديك متغير x مستقل واحد فقط، تستند حسابات m وb إلى الصيغ التالية:
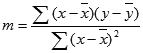
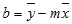
حيث x وy هما وسيلة عينة؛ أي، x = AVERAGE(known x's)وy = AVERAGE(known_y's).يمكن لدالتي ملاءمة الخط والمنحنى LINEST وLOGEST أن تقوما بحساب أفضل خط مستقيم أو منحنى أسي يلائم البيانات. وعلى الرغم من ذلك، يجب عليك أن تقرر أي النتيجتين أمثل للبيانات. يمكنك حساب TREND (known_y،known_x) لخط مستقيم، أو GROWTH(known_y، known_x) للحصول على منحنى أسي. ترجع هذه الدالات، بدون وسيطة new_x ، صفيفا من قيم y المتوقعة على طول هذا الخط أو المنحنى في نقاط البيانات الفعلية. يمكنك بعد ذلك مقارنة القيم التي تم توقعها بالقيم الفعلية. قد تريد رؤية مخطط كل منهما للحصول على مقارنة مرئية.
في تحليل الانحدار، يقوم Excel بحساب الفرق التربيعي لكل نقطة بين قيمة y المقدرة لهذه النقطة وقيمة y الفعلية. يسمى مجموع فروق تلك التربيعات بمجموع المربعات، ssresid. ثم يقوم Excel بحساب إجمالي مجموع المربعات، sstotal. عندما يتم حذف الوسيطة const = TRUE أو، يكون المجموع الإجمالي للمربعات هو مجموع الاختلافات التربيعية بين قيم y الفعلية ومتوسط قيم y. عندما تكون الوسيطة const = FALSE، يكون مجموع المربعات الإجمالي هو مجموع مربعات قيم y الفعلية (دون طرح متوسط القيمة y من كل قيمة ص فردية). يمكن الحصول على انحدار مجموع المربعات، من
: ssreg = sstotal - ssresid . كلما كان مجموع المربعات المتبقي أصغر، مقارنة بالمجموع الإجمالي للمربعات، كلما كانت قيمة معامل التحديد r2 أكبر، وهو مؤشر على مدى جودة تفسير المعادلة الناتجة عن تحليل الانحدار للعلاقة بين المتغيرات. قيمة r2 تساوي ssreg/sstotal.في بعض الحالات، لا يكون لواحد أو أكثر من أعمدة X (افترض أن لكل من Y وX أعمدة) قيمة تنبؤية إضافية في وجود أعمدة X أخرى. بمعنى آخر، قد يؤدي حذف عمود أو أكثر من أعمدة X إلى معرفة قيم Y المتوقعة والتي تكون على نفس مستوى الدقة. وفي هذه الحالة يجب حذف أعمدة X المكررة من نموذج الانحدار. تسمى هذه الظاهرة "القيم الخطية" حيث إنه يمكن التعبير عن أي عمود X مكرر كمجموع ضرب أعمدة X غير المكررة. تقوم الدالة LINEST بالتحقق من القيم الخطية وإزالة أعمدة X المكررة من نموذج الانحدار عند تعريفها. ويمكن التعرف على أعمدة X التي تمت إزالتها في إخراج LINEST عند الحصول على معاملات صفر بالإضافة إلى قيم se الصفرية. في حالة إزالة عمود أو أكثر كأعمدة مكررة، فإن df ستتأثر حيث إنها تعتمد على عدد من أعمدة X المستخدمة بالفعل في أغراض تنبؤية. لمزيد من التفاصيل حول حساب df، راجع المثال 4. إذا تغيرت df بسبب إزالة أعمدة X المكررة، فإن قيم sey وF ستتأثر كذلك. يجب أن تكون القيم الخطية المرتبطة نادرة التكرار في التمرين. على الرغم من ذلك، فإن هناك حالة أكثر عرضة للحدوث وهي احتواء بعض أعمدة X على قيم صفرية وقيم أحادية كمؤشرات حول ما إذا كان الموضوع في التجربة يعتبر أو لا يعتبر جزءاً من مجموعة معينة. إذا كانت const = TRUE أو تم حذفها، فإن الدالة LINEST تدرج بشكل فعال عمود X إضافي من جميع القيم 1 لنمذجة التقاطع. إذا كان لديك عمود به القيمة 1 لكل حالة إذا كانت مذكراً، أو 0 إذا لم تكن كذلك، وكان لديك كذلك عمود به القيمة 1 لكل حالة إذا كانت مؤنثاً أو 0 إذا لم تكن كذلك، فإن العمود الأخير يعتبر مكرراً حيث إن الإدخالات الموجودة به يمكن الحصول عليها من طرح الإدخال في عمود "المؤشر المذكر" من إدخال العمود الإضافي لكافة القيم الأحادية التي أضافتها الدالة LINEST.
يتم حساب قيمة df كما يلي، عندما لا تتم إزالة أي أعمدة X من النموذج بسبب التقارب: إذا كانت هناك أعمدة k من known_x و const = TRUE أو تم حذفها، df = n – k – 1. إذا كانت const = FALSE، df = n - k. وفي كلتا الحالتين، تؤدي إزالة كل عمود من أعمدة X بسبب القيم الخطية إلى زيادة df بمقدار 1.
عند إدخال ثابت صفيف (مثل known_x) كوسيطة، استخدم الفواصل لفصل القيم المضمنة في الصف نفسه والفواصل المنقوعة لفصل الصفوف. يمكن أن تختلف الأحرف الفاصلة حسب الإعدادات الإقليمية.
لاحظ أن قيم y التي توقعتها معادلة الانحدار قد لا تكون صحيحة إذا كانت خارج نطاق قيم y المستخدمة لتحديد المعادلة.
تختلف الخوارزمية الأساسية المستخدمة في دالة LINEST عن الخوارزمية الأساسية المستخدمة في الدالتين SLOPE وINTERCEPT. يمكن أن يؤدي هذا التباين بين الخوارزميات إلى نتائج مختلفة عندما تكون البيانات غير محددة أو محورية. على سبيل المثال، إذا كانت نقاط بيانات وسيطة known_y هي 0 وكانت نقاط بيانات وسيطة known_x هي 1:
- تقوم LINEST بإرجاع القيمة 0. تم تصميم خوارزمية الدالة LINEST لإرجاع نتائج منطقية لبيانات محورية، وفي هذه الحالة يتم العثور على إجابة واحدة على الأقل.
- ترجع الدالة SLOPE و INTERCEPT #DIV/0! #REF!. تم تصميم خوارزمية الدالتين SLOPE و INTERCEPT للبحث عن إجابة واحدة فقط، وفي هذه الحالة يمكن أن يكون هناك أكثر من إجابة واحدة.
بالإضافة إلى استخدام LOGEST لحساب إحصاءات أنواع الانحدار الأخرى، يمكنك استخدام LINEST لحساب نطاق من أنواع الانحدار الأخرى من خلال إدخال دالات المتغيرين x وy كسلسلة x وy للدالة LINEST. على سبيل المثال، الصيغة التالية:
=LINEST(yvalues, xvalues^COLUMN($A:$C))
تعمل عندما يكون لديك عمود واحد لقيم y وعمود واحد لقيم x لحساب التقريب التكعيبي للشكل (متعدد الحدود للترتيب 3).
y = m1*x + m2*x^2 + m3*x^3 + b
يمكنك ضبط هذه الصيغة لحساب أنواع انحدار أخرى، لكن في بعض الحالات، يتطلب ذلك ضبط قيم الإخراج والإحصاءات الأخرى.تختلف قيمة F-test التي يتم إرجاعها بواسطة الدالة LINEST عن قيمة F-test التي يتم إرجاعها بواسطة الدالة FTEST. تُرجع الدالة LINEST إحصائية F، بينما تُرجع الدالة FTEST الاحتمال.
أمثلة
المثال 1: المنحدر وتقاطع Y
انسخ البيانات النموذجية في الجدول التالي، والصقها في الخلية A1 في ورقة عمل Excel جديدة. لعرض نتائج الصيغ، حدد هذه الأخيرة، ثم اضغط على F2، ثم اضغط على Enter. عند الحاجة، يمكنك ضبط عرض العمود لرؤية البيانات كافة.
| معطيات ص | معطيات س |
|---|---|
| 1 | 0 |
| 9 | 4 |
| 5 | 2 |
| 7 | 3 |
| النتيجة (الميل) | النتيجة (التقاطع y) |
| 2 | 1 |
| الصيغة (صيغة الصفيف في الخلايا A7:B7) | |
| =LINEST(A2:A5,B2:B5,,FALSE) |
مثال 2: انحدار خطي بسيط
انسخ البيانات النموذجية في الجدول التالي، والصقها في الخلية A1 في ورقة عمل Excel جديدة. لعرض نتائج الصيغ، حدد هذه الأخيرة، ثم اضغط على F2، ثم اضغط على Enter. عند الحاجة، يمكنك ضبط عرض العمود لرؤية البيانات كافة.
| الشهر | المبيعات |
|---|---|
| 1 | 3100 ر.س. |
| 2 | 4500 ر.س. |
| 3 | 4400 ر.س. |
| 4 | 5400 ر.س. |
| 5 | 7500 ر.س. |
| 6 | 8100 ر.س. |
| الصيغة | النتيجة |
| =SUM(LINEST(B1:B6, A1:A6)*{9,1}) | 11000 ر.س. |
| حساب المبيعات المقدّرة للشهر التاسع، على أساس المبيعات من شهر 1 وحتى شهر 6. |
مثال 3: انحدار خطي متعدد
انسخ البيانات النموذجية في الجدول التالي، والصقها في الخلية A1 في ورقة عمل Excel جديدة. لعرض نتائج الصيغ، حدد هذه الأخيرة، ثم اضغط على F2، ثم اضغط على Enter. عند الحاجة، يمكنك ضبط عرض العمود لمشاهدة كل البيانات.
| مساحة الطابق (x1) | المكاتب (x2) | المداخل (x3) | العمر (x4) | القيمة المقدرة (y) |
|---|---|---|---|---|
| 2310 | 2 | 2 | 20 | 142000 ر.س. |
| 2333 | 2 | 2 | 12 | 144000 ر.س. |
| 2356 | 3 | 1,5 | 33 | 151000 ر.س. |
| 2379 | 3 | 2 | 43 | 150000 ر.س. |
| 2402 | 2 | 3 | 53 | 139000 ر.س. |
| 2425 | 4 | 2 | 23 | 169000 ر.س. |
| 2448 | 2 | 1,5 | 99 | 126000 ر.س. |
| 2471 | 2 | 2 | 34 | 142900 ر.س. |
| 2494 | 3 | 3 | 23 | 163000 ر.س. |
| 2517 | 4 | 4 | 55 | 169000 ر.س. |
| 2540 | 2 | 3 | 22 | 149000 ر.س. |
| -234,2371645 | ||||
| 13,26801148 | ||||
| 0,996747993 | ||||
| 459,7536742 | ||||
| 1732393319 | ||||
| الصيغة (صيغة صفيف ديناميكية تم إدخالها في A19) | ||||
| =LINEST(E2:E12,A2:D12,TRUE,TRUE) |
مثال 4 - استخدام إحصائيات F وr2
في المثال السابق، معامل التحديد، أو r2، هو 0.99675 (راجع الخلية A17 في إخراج LINEST)، مما يشير إلى وجود علاقة قوية بين المتغيرات المستقلة وسعر البيع. يمكنك استخدام إحصائية F لتحديد ما إذا كانت تلك النتائج، مع قيمة r2 العالية هذه، قد حدثت بالصدفة.
افترض الآن أنه لا يوجد بالفعل علاقة بين المتغيرات، بل أنك قد جئت بمجرد عينة من 11 مبنى إداري تؤدي إلى عرض علاقة قوية للتحليل الإحصائي. يُستخدم المصطلح "ألفا" لاحتمال خطأ استنتاج وجود علاقة.
يمكن استخدام قيمتي F و df في ناتج الدالة LINEST لتحديد احتمال حدوث قيمة F العليا بالصدفة. يمكن مقارنة قيمة F مع القيم المهمة الموجودة في جداول توزيع F التي تم نشرها أو يمكن استخدام الدالة FDIST في Excel لحساب احتمال حدوث قيمة F العليا بالصدفة. يكون لتوزيع F المناسب درجتان من الحرية هما v1 وv2. إذا كان n هو عدد نقاط البيانات وكان const = TRUE أو تم حذفها، فإن v1 = n – df – 1 وv2 = df. (إذا كانت const = FALSE، ثم v1 = n – df وv2 = df.) الدالة FDIST - مع بناء جملة FDIST(F,v1,v2) - سترجع احتمال حدوث قيمة F أعلى بالصدفة. في هذا المثال، df = 6 (الخلية B18) و F = 459.753674 (الخلية A18).
بفرض أن قيمة ألفا هي 0.05، وv1 = 11 – 6 – 1 = 4 وv2 = 6، يكون المستوى المهم للقيمة F هو 4.53. ولأن F = 459.753674 أكبر بكثير من 4.53، فمن غير المحتمل أن تكون قيمة F العالية قد حدثت بالصدفة. (باستخدام Alpha = 0.05، يجب رفض فرضية عدم وجود علاقة بين known_y و known_x عندما يتجاوز F المستوى الحرج، 4.53.) يمكنك استخدام الدالة FDIST في Excel للحصول على احتمال حدوث قيمة F بهذا الارتفاع بالصدفة. فعلى سبيل المثال، FDIST(459.753674, 4, 6) = 1.37E-7، هي احتمال ضئيل للغاية. يمكنك الاستنتاج إما بالحصول على المستوى المهم لقيمة F في جدول أو باستخدام الدالة FDIST، وتفيد معادلة الانحدار في التنبؤ بالقيم المقدرة للمباني الإدارية في هذه المنطقة. تذكر أنه من الضروري استخدام القيم الصحيحة المحسوبة للقيمتين v1 و v2 في الفقرة السابقة.
مثال 5 ـ حساب إحصاءات t
يحدد اختبار افتراضي آخر ما إذا كان كل معامل ميل مفيداً في تقدير القيمة المقدرة لمبنى إداري في المثال 3. فعلى سبيل المثال، لاختبار معامل العمر للأهمية الإحصائية، اقسم -234.24 (معامل ميل العمر) على 13.268 (الخطأ المعياري المقدر لمعاملات العمر في الخلية A15). ما يلي قيمة t الملحوظة:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
إذا كانت القيمة المطلقة لـ t مرتفعة بشكل كاف، يمكن استنتاج أن معامل الميل مفيد في تقدير القيمة المقدرة لمبنى إداري في المثال 3. يعرض الجدول التالي القيم المطلقة لقيم t الأربعة الملاحظة.
إذا قمت بمراجعة جدول في دليل إحصاءات، فستجد أن قيمة t الحرجة ثنائية الطرف، مع 6 درجات للحرية وألفا=0.05 تكون 2.447. كما يمكن الحصول على هذه القيمة الحرجة باستخدام الدالة TINV في Excel. TINV (0.05,6) = 2.447. لأن القيمة المطلقة لـ t، وهي (17.7) أكبر من 2.447، يصبح العمر متغيراً مهماً عند تقدير القيمة المقدرة لمبنى إداري. يمكن اختبار كل متغير من المتغيرات المستقلة الأخرى لمعرفة الأهمية الإحصائية بطريقة مماثلة. فيما يلي قيم t الملاحظة لكل من المتغيرات المستقلة.
| المتغير | قيمة t الملحوظة |
|---|---|
| مساحة الطابق | 5,1 |
| عدد المكاتب | 31,3 |
| عدد المداخل | 4,8 |
| العمر | 17,7 |
تحتوي كافة تلك القيم على قيم مطلقة أكبر من 2.447؛ لذلك فإن كافة المتغيرات المستخدمة في معادلة الانحدار مفيدة في توقع القيمة المقدرة للمباني الإدارية في هذه المنطقة.