Funkce PIVOTBY umožňuje vytvořit souhrn dat pomocí vzorce. Podporuje seskupení podél dvou os a agregaci přidružených hodnot. Pokud byste například měli tabulku dat o prodeji, mohli byste vygenerovat souhrn prodeje podle státu a roku.
Poznámka: PIVOTBY je funkce, která vrací pole hodnot, které mohou přesahovat do mřížky. Diskuzi o funkci PIVOTBY a kontingenčních tabulkách najdete tady.
Syntaxe:
Funkce PIVOTBY umožňuje seskupit, agregovat, řadit a filtrovat data na základě zadaných polí řádků a sloupců.
Syntaxe funkce PIVOTBY je:
PIVOTBY(row_fields;col_fields;hodnoty;funkce;[field_headers],[row_total_depth],[row_sort_order],[col_total_depth],[col_sort_order],[filter_array])
|
Argument |
Popis |
|---|---|
|
row_fields (povinné) |
Sloupcově orientovaná matice nebo oblast obsahující hodnoty, které se používají k seskupení řádků a generování záhlaví řádků. Matice nebo oblast může obsahovat více sloupců. Pokud ano, výstup bude mít více úrovní skupiny řádků. |
|
col_fields (povinné) |
Sloupcově orientované pole nebo oblast obsahující hodnoty, které se používají k seskupení sloupců a generování záhlaví sloupců. Matice nebo oblast může obsahovat více sloupců. Pokud ano, výstup bude mít více úrovní skupiny sloupců. |
|
Hodnoty (povinné) |
Sloupcově orientované pole nebo oblast dat, která se mají agregovat. Matice nebo oblast může obsahovat více sloupců. Pokud ano, výstup bude mít více agregací. |
|
Funkce (povinné) |
Funkce lambda nebo redukovaná lambda (SUMA, PRŮMĚR, POČET atd.), která definuje, jak se mají hodnoty agregovat. Lze poskytnout vektor lambda. Pokud ano, výstup bude mít více agregací. Orientace vektoru určuje, jestli jsou rozložené podle řádků nebo sloupců. |
|
field_headers |
Číslo, které určuje, jestli row_fields, col_fields a hodnoty mají záhlaví a jestli mají být záhlaví polí vrácena ve výsledcích. Možné hodnoty jsou:
Chybí: Automaticky. Poznámka: Automaticky předpokládá, že data obsahují hlavičky na základě argumentu values. Pokud je první hodnota text a druhá hodnota je číslo, předpokládá se, že data mají záhlaví. Záhlaví polí se zobrazí, pokud existuje více úrovní skupin řádků nebo sloupců. |
|
row_total_depth |
Určuje, zda záhlaví řádků mají obsahovat součty. Možné hodnoty jsou:
Chybí: Automaticky: Celkové součty a tam, kde je to možné, mezisoučty. Poznámka: Pro mezisoučty musí mít row_fields aspoň 2 sloupce. Čísla větší než 2 jsou podporována za předpokladu , že row_field má dostatek sloupců. |
|
row_sort_order |
Číslo označující, jak mají být řádky seřazeny. Čísla odpovídají sloupcům v row_fields následovaných sloupci v hodnotách. Pokud je číslo záporné, řádky se seřadí sestupně nebo v opačném pořadí. Vektor čísel lze poskytnout při řazení na základě pouze row_fields. |
|
col_total_depth |
Určuje, zda záhlaví sloupců mají obsahovat součty. Možné hodnoty jsou:
Chybí: Automaticky: Celkové součty a tam, kde je to možné, mezisoučty. Poznámka: Pro mezisoučty musí mít col_fields aspoň 2 sloupce. Čísla větší než 2 se podporují za předpokladu , že col_field má dostatek sloupců. |
|
col_sort_order |
Číslo označující, jak mají být řádky seřazeny. Čísla odpovídají sloupcům v col_fields následované sloupci v hodnotách. Pokud je číslo záporné, řádky se seřadí sestupně nebo v opačném pořadí. Vektor čísel lze zadat při řazení na základě pouze col_fields. |
|
filter_array |
Sloupcově orientované 1D pole logických hodnot, které označují, jestli se má vzít v úvahu odpovídající řádek dat. Poznámka: Délka pole musí odpovídat délce polí zadaných pro row_fields a col_fields. |
Příklady
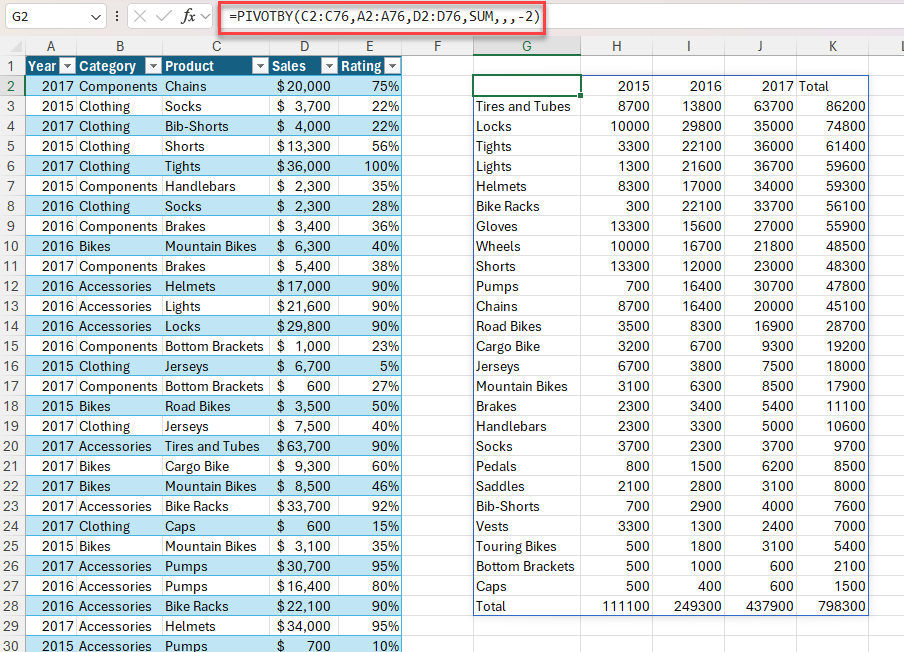
Příklad 1: Pomocí funkce PIVOTBY vygenerujte souhrn celkových prodejů podle produktu a roku.
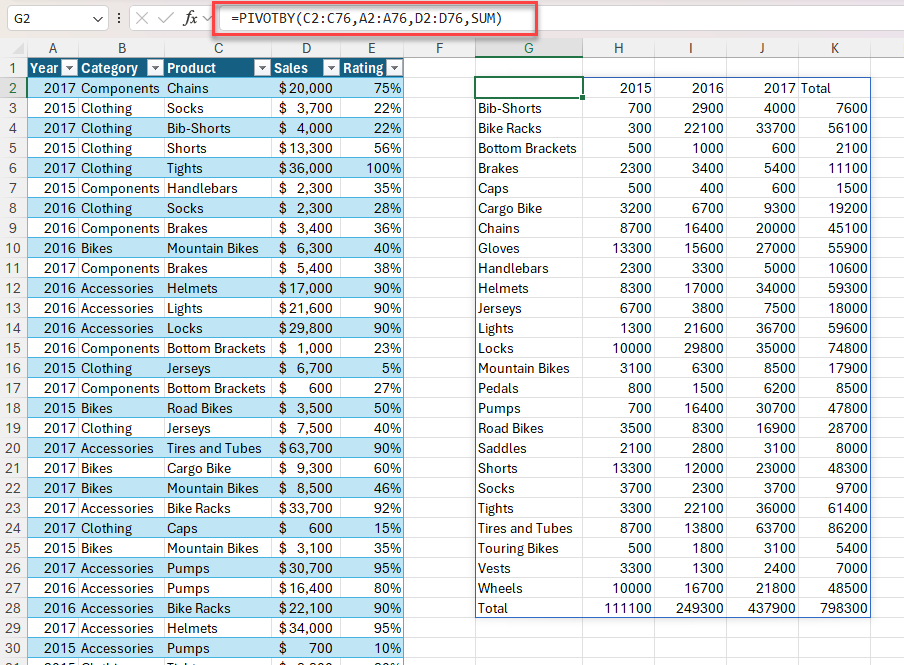
Příklad 2: Použití funkce PIVOTBY k vygenerování souhrnu celkových prodejů podle produktu a roku Seřadit sestupně podle prodeje.