Med funktionen PIVOTBY kan du oprette en oversigt over dine data via en formel. Det understøtter gruppering langs to akser og sammenlægning af de tilknyttede værdier. Hvis du f.eks. havde en tabel over salgsdata, kan du oprette en oversigt over salg efter stat og år.
Bemærk!: PIVOTBY er en funktion, der returnerer en matrix med værdier, der kan løbe over i gitteret. Du kan finde en diskussion om PIVOTBY og pivottabeller her.
Syntaks
Med funktionen PIVOTBY kan du gruppere, aggregere, sortere og filtrere data baseret på de række- og kolonnefelter, du angiver.
Syntaksen for funktionen PIVOTBY er:
PIVOTBY(row_fields,col_fields,værdier,funktion,[field_headers],[row_total_depth],[row_sort_order],[col_total_depth],[col_sort_order],[filter_array])
|
Argument |
Beskrivelse |
|---|---|
|
row_fields (påkrævet) |
En kolonneorienteret matrix eller et kolonneområde, der indeholder de værdier, der bruges til at gruppere rækker og oprette rækkeoverskrifter. Matrixen eller området kan indeholde flere kolonner. Hvis det er tilfældet, har outputtet flere rækkegrupperingsniveauer. |
|
col_fields (påkrævet) |
En kolonneorienteret matrix eller et område, der indeholder de værdier, der bruges til at gruppere kolonner og oprette kolonneoverskrifter. Matrixen eller området kan indeholde flere kolonner. Hvis det er tilfældet, har outputtet grupperingsniveauer for flere kolonner. |
|
Værdier (påkrævet) |
En kolonneorienteret matrix eller et område af de data, der skal aggregeres. Matrixen eller området kan indeholde flere kolonner. Hvis det er tilfældet, vil outputtet have flere sammenlægninger. |
|
Funktion (påkrævet) |
En lambda-funktion eller eta-reduceret lambda (SUM, MIDDEL, TÆL osv.), der definerer, hvordan værdierne skal aggregeres. Der kan leveres en vektor af lambdas. Hvis det er tilfældet, vil outputtet have flere sammenlægninger. Vektorens retning afgør, om de er lagt ud række- eller kolonnevis. |
|
field_headers |
Et tal, der angiver, om row_fields, col_fields og værdier har overskrifter, og om feltoverskrifter skal returneres i resultaterne. De mulige værdier er:
Mangler: Automatisk. Bemærk!: Automatisk antager, at dataene indeholder overskrifter baseret på værdiargumentet. Hvis den første værdi er tekst, og den anden værdi er et tal, antages dataene at have overskrifter. Feltoverskrifter vises, hvis der er flere grupperingsniveauer for rækker eller kolonner. |
|
row_total_depth |
Bestemmer, om rækkeoverskrifterne skal indeholde totaler. De mulige værdier er:
Mangler: Automatisk: Hovedtotaler og, hvor det er muligt, subtotaler. Bemærk!: For subtotaler skal row_fields have mindst 2 kolonner. Tal, der er større end 2, understøttes , row_field har tilstrækkelige kolonner. |
|
row_sort_order |
Et tal, der angiver, hvordan rækker skal sorteres. Tal svarer til kolonner i row_fields efterfulgt af kolonnerne i værdier. Hvis tallet er negativt, sorteres rækkerne i faldende/omvendt rækkefølge. Der kan angives en vektor af tal, når der kun sorteres baseret på row_fields. |
|
col_total_depth |
Bestemmer, om kolonneoverskrifterne skal indeholde totaler. De mulige værdier er:
Mangler: Automatisk: Hovedtotaler og, hvor det er muligt, subtotaler. Bemærk!: For subtotaler skal col_fields have mindst 2 kolonner. Tal, der er større end 2, understøttes , col_field har tilstrækkelige kolonner. |
|
col_sort_order |
Et tal, der angiver, hvordan rækker skal sorteres. Tal svarer til kolonner i col_fields efterfulgt af kolonnerne i værdier. Hvis tallet er negativt, sorteres rækkerne i faldende/omvendt rækkefølge. Der kan angives en vektor af tal, når der kun sorteres baseret på col_fields. |
|
filter_array |
En kolonneorienteret 1D-matrix med booleske værdier, der angiver, om den tilsvarende række med data skal overvejes. Bemærk!: Matrixens længde skal svare til længden af dem, der leveres til row_fields og col_fields. |
Eksempler
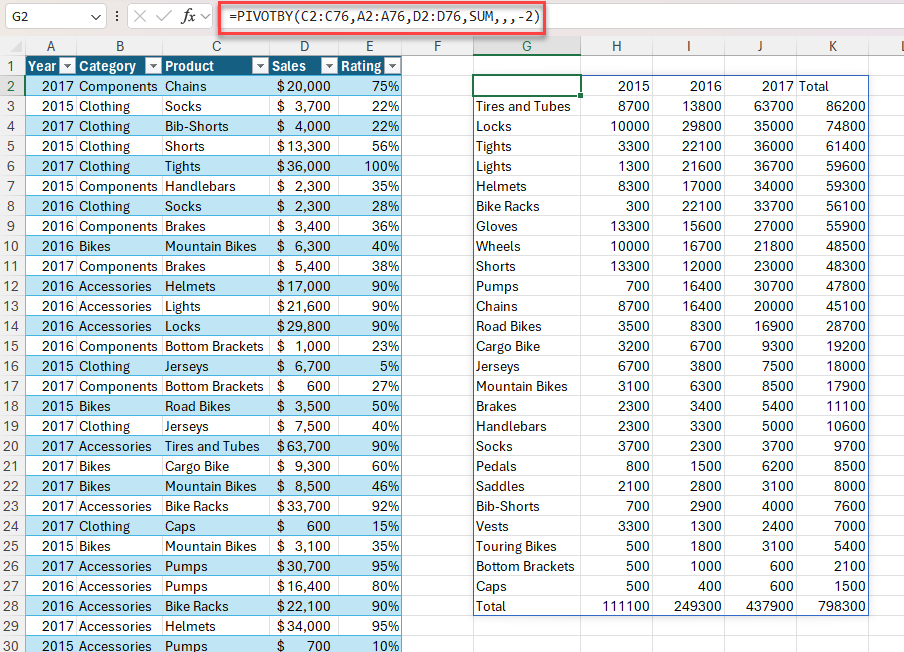
Eksempel 1: Brug PIVOTBY til at generere en oversigt over det samlede salg efter produkt og år.
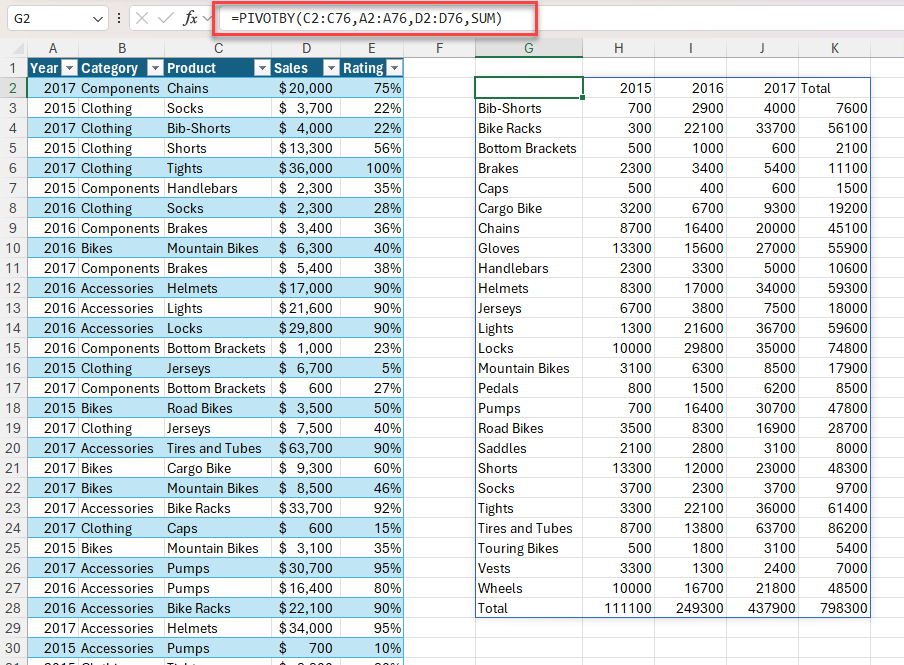
Eksempel 2: Brug PIVOTBY til at generere en oversigt over det samlede salg efter produkt og år. Sortér faldende efter salg.