
I denne artikel beskrives formelsyntaksen for og brugen af funktionen LINREGR i Microsoft Excel.
Beskrivelse
Funktionen LINREGR beregner en linjes stikprøvefunktioner ved at bruge de mindste kvadraters metode til beregning af den lige linje med den bedste tilnærmelse til dataene, og returnerer derefter en matrix, der beskriver linjen. Du kan også kombinere funktionen LINREGR med andre funktioner for at beregne statistikken for andre typer modeller, der er lineære, i de ukendte parametre, herunder polynomiske, logaritmiske og eksponentielle serier og potensserier. Da denne funktion returnerer en matrix med værdier, skal den angives som en matrixformel. Vejledningen følger eksemplerne i denne artikel.
Ligningen for linjen er:
y = mx + b
– eller –
y = m1x1 + m2x2 + ... + b
Hvis der er flere intervaller for x-værdier, hvor de afhængige y-værdier er en funktion af de uafhængige x-værdier. M-værdierne er koefficienter svarende til hver x-værdi, og b er en konstant værdi. Bemærk, at y, x og m kan være matrixer. Den matrix, funktionen LINREGR returnerer, er {mn;mn-1;...;m1;b}. LINREGR kan også returnere andre regressionsspecifikke stikprøvefunktioner.
Syntaks
LINREGR(kendte_y'er;[kendte_x'er];[konstant];[statistik])
Syntaksen for funktionen LINREGR har følgende argumenter:
Syntaks
-
kendte_y'er Påkrævet. Det sæt y-værdier, som du eventuelt allerede kender fra forholdet y = mx + b.
-
Hvis området med kendte_y'er findes i en enkelt kolonne, fortolkes hver kolonne med kendte_x'er som en separat variabel.
-
Hvis området med kendte_y'er er placeret i en enkelt række, fortolkes hver række med kendte_x'er som en separat variabel.
-
-
kendte_x'er Valgfrit. Et sæt x-værdier, som du eventuelt allerede kender fra forholdet y = mx + b.
-
Området med known_x kan indeholde et eller flere sæt variabler. Hvis der kun bruges én variabel, kan known_y ogknown_x være områder af enhver form, så længe de har samme dimensioner. Hvis der bruges mere end én variabel, skal known_y være en vektor (dvs. et område med en højde på én række eller en bredde på én kolonne).
-
Hvis kendte_x'er udelades, antages matrixen {1;2;3;...}, der har samme størrelse som kendte_y'er.
-
-
konstant Valgfrit. En logisk værdi, der angiver, om konstanten b skal være lig med 0.
-
Hvis konstant er SAND eller udelades, beregnes b på normal vis.
-
Hvis konstant er FALSK, defineres b som lig med 0, og m-værdierne justeres til y = mx.
-
-
statistik Valgfrit. En logisk værdi, der angiver, om der skal returneres regressionsspecifikke stikprøvefunktioner.
-
Hvis statistik er SAND, returnerer LINREGR de yderligere regressionsstatistikker. som et resultat er den returnerede matrix {mn;mn-1,...,m1;b; sen,sen-1,...,se1,seb; r2,5; F,f; ssreg,ssresid}.
-
Hvis statistik er FALSK eller udelades, returnerer LINREGR kun m-koefficienterne og konstanten b.
De andre regressionsspecifikke stikprøvefunktioner er som følger:
-
|
Statistik |
Beskrivelse |
|---|---|
|
sf1;sf2;...;sfn |
Standardfejlværdier for koefficienterne m1;m2;...;mn. |
|
sfb |
Standardfejlværdien for konstanten b (sfb = #I/T, når konstant er FALSK). |
|
r2 |
Determinationskoefficienten. Sammenligner estimerede og faktiske y-værdier og værdier mellem 0 og 1. Hvis værdien er 1, er korrelationen perfekt i stikprøven, og der er ingen forskel mellem den estimerede y-værdi og den faktiske y-værdi. Hvis determinationskoefficienten i det andet grænsetilfælde er 0, kan regressionsligningen ikke anvendes til at beregne en y-værdi. Du kan få mere at vide om, hvordan2 beregnes, under "Bemærkninger" senere i dette emne. |
|
sfy |
Standardfejlen for estimerede y-værdier. |
|
F |
Stikprøvefunktionen F eller den F-observerede værdi. Brug stikprøvefunktionen F til at afgøre, om det observerede forhold mellem de afhængige og uafhængige variabler er en tilfældighed. |
|
fg |
Frihedsgraderne. Brug frihedsgraderne til at finde de F-kritiske værdier i en statistisk tabel. Sammenlign de fundne værdier i tabellen med stikprøvefunktionen F, som returneres af LINREGR, for at bestemme et signifikansniveau for modellen. Oplysninger om beregning af fg finder du under "Bemærk!" nedenfor. I Eksempel 4 vises brugen af F og fg. |
|
ksreg |
Regressionssummen af kvadrater. |
|
ksrest |
Restsummen af kvadrater. Oplysninger om beregning af ksreg and ksrest finder du under "Bemærk!" nedenfor. |
I følgende illustration vises rækkefølgen, hvori de andre regressionsspecifikke stikprøvefunktioner returneres:

Bemærkninger
-
Du kan beskrive en vilkårlig ret linje med hældningskoefficienten og y-skæringspunktet:
Hældningskoefficient (m):
Hvis du vil finde en linjes hældning, ofte skrevet som m, skal du tage to punkter på linjen (x1,y1) og (x2,y2); hældningen er lig med (y2 - y1)/(x2 - x1).Y-skæringspunkt (b):
y-skæringspunktet for en linje, ofte skrevet som b, er værdien af y på det punkt, hvor linjen krydser y-aksen.Ligningen for en ret linje er y = mx + b. Når du kender værdien af m og b, kan du beregne et vilkårligt punkt på linjen ved at indsætte y- eller x-værdien i ligningen. Du kan også bruge funktionen TENDENS.
-
Når der kun er én uafhængig x-variabel, kan du udregne hældningskoefficienten og værdien for y-skæringspunktet direkte med følgende formler:
Skråning:
=INDEKS(LINREGR(known_y'er;known_x'er);1)Y-skæringspunkt:
=INDEKS(LINREGR(known_y'er;known_x'er);2) -
Linjens nøjagtighed, der er beregnet med funktionen LINREGR, afhænger af spredningsgraden for de anvendte data. Jo mere lineære dataene er, jo mere nøjagtig er LINREGR-modellen. LINREGR bruger de mindste kvadraters metode til at bestemme den bedste tilnærmelse til dataene, og returnerer derefter en matrix, der beskriver linjen. Når der kun er én uafhængig x-variabel, baseres beregningerne for m og b på følgende formler:

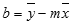
hvor x og y er stikprøvernes middelværdi, dvs. x = MIDDEL(kendte_x'er) og y = MIDDEL(kendte_y'er)).
-
Funktionerne LINREGR og LOGREGR til kurvetilpasning kan beregne den bedste lige kurve eller eksponentialkurve, der passer til dine data. Du skal dog beslutte, hvilke af de to resultater der passer bedst til dine data. Du kan beregne TENDENS(known_y,known_x) for en lige linje eller FORØGELSE(known_y,known_x)for en eksponentialkurve. Uden new_x argument returnerer disse funktioner en matrix med y-værdier, der er forudsagt langs den pågældende linje eller kurve ved de faktiske datapunkter. Du kan derefter sammenligne de forudsagte værdier med de faktiske værdier. Det kan være en god ide at lave et diagram med dem begge for at få en visuel sammenligning.
-
Ved regressionsanalyse beregnes for hvert punkt den kvadrerede forskel mellem den skønnede y-værdi for det pågældende punkt og den faktiske y-værdi. Summen af disse kvadrerede forskelle kaldes kvadraternes restsum, ksrest. Derefter beregnes den totale sum af kvadrater, sstotal. Når argumentet konstant = SAND eller er udeladt, er den totale sum af kvadrater lig med summen af de kvadrerede forskelle mellem de faktiske y-værdier og gennemsnitsværdien for y-værdierne. Når argumentet konstant = FALSK, er den totale sum af kvadrater lig med summen af kvadrater af de faktiske y-værdier (uden at trække den gennemsnitlige y-værdi fra hver individuel y-værdi). Derefter kan regressionssummen af kvadrater, ksreg, findes ud fra: ksreg = sstotal - ksrest. Jo mindre restsummen af kvadrater er sammenlignet med den samlede sum af kvadrater, jo større er værdien af determinationskoefficienten r2, hvilket er en indikator for, hvor godt ligningen som følge af regressionsanalysen forklarer forholdet mellem variablerne. Værdien af r2 er lig med ssreg/sstotal.
-
I nogle tilfælde har en eller flere af X-kolonnerne (antag, at Y’er og X’er er i kolonner) ingen ekstra skønnet værdi ved tilstedeværelse af de andre X-kolonner. Med andre ord kan udeladelse af en eller flere X-kolonner føre til skønnede Y-værdier, der er lige præcise. I dette tilfælde skal disse redundante X-kolonner udelades fra regressionsmodellen. Dette fænomen kaldes “kollinearitet”, fordi eventuelle redundante X-kolonner kan udtrykkes som en sum af multipler af de ikke-redundante X-kolonner. Funktionen LINREGR kontrollerer, om der er kollinearitet og fjerner eventuelle redundante X-kolonner fra regressionsmodellen, når de identificeres. Fjernede X-kolonner kan genkendes i LINREGR-output, derved at de har både 0-koefficienter og 0 se-værdier. Hvis en eller flere kolonner fjernes som redundante, berøres fg, fordi fg afhænger af antallet af X-kolonner, der faktisk bruges til skønsformål. Yderligere oplysninger om beregning af fg findes i Eksempel 4 nedenfor. Hvis fg ændres, fordi redundante X-kolonner fjernes, berøres værdierne af sey og F også. Kollinearitet bør i praksis være relativ sjælden. Der er dog ét tilfælde, hvor det mere sandsynligt kan forekomme, nemlig når nogle X-kolonner kun indeholder 0- og 1-værdier som indikatorer for, om et individ i et eksperiment er medlem af en bestemt gruppe eller ej. Hvis konstant = SAND eller udeladt, indsætter funktionen LINREGR effektivt en ekstra X-kolonne for alle 1’er for at beregne skæringspunktet. Hvis du har en kolonne med et 1 for hvert individ, hvis det er hankøn, og 0 hvis ikke, og du også har en kolonne med 1 for hvert individ, hvis det er hunkøn, og 0 hvis ikke, er den sidste kolonne redundant, fordi posterne i den kan udledes ved at trække posten i kolonnen med “hankønsindikator” fra posten i den ekstra kolonne med alle 1’er tilføjet af funktionen LINREGR.
-
Værdien af fg beregnes på følgende måde, når der ikke fjernes X-kolonner fra modellen på grund af kollinearitet: Hvis der er k-kolonner med known_x ogkonstant = SAND eller udelades, fg = n – k – 1. Hvis konstant = FALSK, fg = n - k. I begge tilfælde øger hver X-kolonne, der blev fjernet på grund af kollinearitet, værdien af fg med 1.
-
Når du angiver en matrixkonstant (f.eks. known_x'er) som argument, skal du bruge kommaer til at adskille værdier, der er indeholdt i den samme række og semikolon, til at adskille rækker. Separatortegn kan være forskellige afhængigt af dine internationale indstillinger.
-
Bemærk, at y-værdierne, der er skønsmæssigt beregnet med regressionsligningen, eventuelt ikke er gyldige, hvis de ligger uden for intervallet for de y-værdier, du har anvendt til at udregne ligningen.
-
Den underliggende algoritme, der bruges i funktionen LINREGR , er forskellig fra den underliggende algoritme, der bruges i funktionerne STIGNING og SKÆRING . Forskellen mellem disse algoritmer kan føre til forskellige resultater, når data er ubestemte og ligger på samme linje. Hvis datapunkterne for argumentet known_y f.eks. er 0, og datapunkterne for argumentet known_x er 1:
-
LINREGR returnerer en værdi på 0. Algoritmen for funktionen LINREGR er designet til at returnere rimelige resultater for data på samme linje, og i dette tilfælde kan der findes mindst ét svar.
-
STIGNING og SKÆRING returnerer en #DIV/0! -fejlen. Algoritmen for funktionerne STIGNING og SKÆRING er designet til kun at søge efter ét svar, og i dette tilfælde kan der være mere end ét svar.
-
-
Ud over at bruge LOGREGR til at beregne statistik for andre regressionstyper kan du bruge LINREGR til at beregne en række andre regressionstyper ved at indtaste funktionerne for x- og y-variablerne som x- og y-serien for LINEST, f.eks. følgende formel:
=LINREGR(yværdier; xværdier^KOLONNE($A:$C))
fungerer, hvis du har en enkelt kolonne med y-værdier og en enkelt kolonne med x-værdier til at beregne den kubiske (polynomisk af tredje orden) tilnærmelse af formlen:
y = m1*x + m2*x^2 + m3*x^3 + b
Du kan justere denne formel for at beregne andre regressionstyper, men i nogle tilfælde kræver det, at outputværdierne og anden statistik justeres.
-
Den værdi for F-testen, der returneres af funktionen LINREGR, adskiller sig fra den værdi for F-testen, der returneres af funktionen FTEST. LINREGR returnerer F-statistikken, mens FTEST returnerer sandsynligheden.
Eksempler
Eksempel 1 – Hældningskoefficient og y-skæringspunkt
Kopiér eksempeldataene i følgende tabel, og sæt dem ind i celle A1 i et nyt Excel-regneark. For at få formlerne til at vise resultater skal du markere dem, trykke på F2 og derefter trykke på Enter. Hvis der er brug for det, kan du justere bredden på kolonnerne, så du kan se alle dataene.
|
Kendt y |
Kendt x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Resultat (hældingskoefficient) |
Resultat (y-skæringspunkt) |
|
2 |
1 |
|
Formel (matrixformel i cellerne A7:B7) |
|
|
=LINREGR(A2:A5;B2:B5;FALSK) |
Eksempel 2 – Simpel lineær regression
Kopiér eksempeldataene i følgende tabel, og sæt dem ind i celle A1 i et nyt Excel-regneark. For at få formlerne til at vise resultater skal du markere dem, trykke på F2 og derefter trykke på Enter. Hvis der er brug for det, kan du justere bredden på kolonnerne, så du kan se alle dataene.
|
Måned |
Salg |
|---|---|
|
1 |
kr. 31.000 |
|
2 |
kr. 45.000 |
|
3 |
kr. 44.000 |
|
4 |
kr. 54.000 |
|
5 |
kr. 75.000 |
|
6 |
kr. 81.000 |
|
Formel |
Resultat |
|
=SUM(LINREGR(B1:B6; A1:A6)*{9;1}) |
DKK 11.000 |
|
Beregner det anslåede salg i niende måned på basis af salget i måned 1 til og med 6. |
Eksempel 3 – Flerlineær regression
Kopiér eksempeldataene i følgende tabel, og sæt dem ind i celle A1 i et nyt Excel-regneark. For at få formlerne til at vise resultater skal du markere dem, trykke på F2 og derefter trykke på Enter. Hvis der er brug for det, kan du justere bredden på kolonnerne, så du kan se alle dataene.
|
Gulvareal (x1) |
Kontorer (x2) |
Indgange (x3) |
Alder (x4) |
Ejendomsværdi (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
DKK 142.000 |
|
2333 |
2 |
2 |
12 |
DKK 144.000 |
|
2356 |
3 |
1,5 |
33 |
DKK 151.000 |
|
2379 |
3 |
2 |
43 |
DKK 150.000 |
|
2402 |
2 |
3 |
53 |
DKK 139.000 |
|
2425 |
4 |
2 |
23 |
DKK 169.000 |
|
2448 |
2 |
1,5 |
99 |
DKK 126.000 |
|
2471 |
2 |
2 |
34 |
DKK 142.900 |
|
2494 |
3 |
3 |
23 |
DKK 163.000 |
|
2517 |
4 |
4 |
55 |
DKK 169.000 |
|
2540 |
2 |
3 |
22 |
DKK 149.000 |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formel (dynamisk matrixformel, der er angivet i A19) |
||||
|
=LINREGR(E2:E12;A2:D12;SAND;SAND) |
Eksempel 4 – Brug af statistikkerne F og r2
I det foregående eksempel er determinationskoefficienten r 0,99675 (se celle A17 i outputtet for LINREGR), hvilket indikerer en stærk forbindelse mellem de uafhængige variabler og salgsprisen. Du kan bruge stikprøvefunktionen F til at afgøre, om disse resultater med så høj en r2-værdi er tilfældige.
Antag, at der faktisk ikke er en forbindelse mellem variablerne, men at du har udtaget en usædvanlig stikprøve på 11 kontorbygninger, som bevirker, at den statistiske analyse viser en nær forbindelse. Sandsynligheden for, at du fejlagtigt konkluderer, at der foreligger en forbindelse, kaldes Alpha.
Værdierne F og fg i output fra funktionen LINREGR kan bruges til at vurdere sandsynligheden for, at en højere F-værdi opstår tilfældigt. F kan sammenlignes med kritiske værdier i udgivne F-fordelingstabeller, eller funktionen FFORDELING i Excel kan bruges til at beregne sandsynligheden for, at en større F-værdi opstår tilfældigt. Den passende F-fordeling har v1 og v2 frihedsgrader. Hvis n er antallet af datapunkter, og konstant = SAND eller er udeladt, er v1 = n – fg – 1 og v2 = fg. (Hvis konstant = FALSK, er v1 = n – fg og v2 = fg). Funktionen FFORDELING med syntaksen FFORDELING(F,v1,v2) returnerer sandsynligheden for, at en større F-værdi opstår tilfældigt. I eksempel 4 er fg = 6 (celle B18) og F = 459,753674 (celle A18).
Hvis alphaværdien er 0,05, v1 = 11 – 6 – 1 = 4, og v2 = 6, er det kritiske niveau af F 4,53. Da F = 459,753674 er meget højere end 4,53, er det yderst usandsynligt, at en F-værdi, der er så høj, er tilfældig. (Med Alpha = 0,05 skal hypotesen om, at der ikke er nogen sammenhæng mellem known_y ogknown_x, afvises , når F overskrider det kritiske niveau, 4,53). Du kan bruge funktionen FFORDELING i Excel til at opnå sandsynligheden for, at en F-værdi, der er så høj, er opstået tilfældigt. FFORDELING(459,753674; 4, 6) = 1,37E-7, en meget lille sandsynlighed. Du kan enten ved at finde det kritiske niveau for F i en tabel eller ved hjælp af funktionen FFORDELING konkludere, at regressionsligningen er nyttig til at forudsige den vurderede værdi af kontorbygninger i dette område. Husk, at det er vigtigt at bruge de korrekte værdier af v1 og v2, der blev beregnet i det foregående afsnit.
Eksempel 5 – Beregning af t-statistikken
En anden hypotesetest vil afgøre, om hver hældningskoefficient er nyttig til at vurdere den vurderede værdi af en kontorbygning i eksempel 3. Hvis du f.eks. vil teste alderskoefficienten for statistisk betydning, skal du dividere -234,24 (alderskoefficient) med 13,268 (den anslåede standardfejl for alderskoefficienter i celle A15). Følgende er den t-observerede værdi:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Hvis den absolutte værdi af t er tilstrækkelig stor, kan det konkluderes, at hældningskoefficienten er nyttig til at beregne den skønsmæssige ejendomsværdi for en kontorbygning i Eksempel 3. I følgende tabel vises de absolutte værdier af de 4 t-observerede værdier.
Hvis du konsulterer en tabel i en statistikmanual, vil du opdage, at t-kritisk, to sidet, med 6 frihedsgrader og Alpha = 0,05 er 2,447. Denne kritiske værdi kan også findes ved hjælp af funktionen TINV i Excel. TINV(0,05;6) = 2,447. Da den absolutte værdi af t (17,7) er større end 2,447, er alder en vigtig variabel ved beregning af den vurderede værdi af en kontorbygning. Hver af de andre uafhængige variabler kan testes for statistisk betydning på en lignende måde. Følgende er de t-observerede værdier for hver af de uafhængige variabler.
|
Variabel |
t-observeret værdi |
|---|---|
|
Gulvareal |
5,1 |
|
Antal kontorer |
31,3 |
|
Antal indgange |
4,8 |
|
Alder |
17,7 |
Disse værdier har alle en absolut værdi, der er større end 2,447, og alle anvendte variabler i regressionsligningen kan derfor med fordel anvendes til at beregne den skønsmæssige ejendomsværdi for kontorbygninger i dette område.









