
I Excel 2013 eller nyere kan du oprette datamodeller, der indeholder millioner af rækker, og derefter udføre effektive dataanalyser mod disse modeller. Datamodeller kan oprettes med eller uden tilføjelsesprogrammet Power Pivot til at understøtte et vilkårligt antal pivottabeller, diagrammer og Power View visualiseringer i den samme projektmappe.
Bemærk!: I denne artikel beskrives datamodeller i Excel 2013. Men de samme datamodellerings- og Power Pivot-funktioner, der blev introduceret i Excel 2013, gælder også for Excel 2016. Der er faktisk kun lille forskel mellem disse versioner af Excel.
Selvom du nemt kan oprette enorme datamodeller i Excel, er der flere grunde til ikke at gøre det. For det første er store modeller, der indeholder mange tabeller og kolonner, overdrud for de fleste analyser og giver en besværlig feltliste. For det andet bruger store modeller værdifuld hukommelse og påvirker negativt andre programmer og rapporter, der deler de samme systemressourcer. I menuen Microsoft 365begrænser både SharePoint Online og Excel Web App størrelsen af en Excel til 10 MB. For projektmappedatamodeller, der indeholder millioner af rækker, løber du hurtigt ind i grænsen på 10 MB. Se specifikation og begrænsninger for datamodeller.
I denne artikel kan du lære, hvordan du opbygger en tæt opbygget model, der er nemmere at arbejde med og bruger mindre hukommelse. Hvis du bruger tid på at lære de bedste fremgangsmåder i effektivt modeldesign, er det en god ide at bruge en hvilken som helst model, du opretter og bruger, uanset om du får den vist i Excel 2013, Microsoft 365 SharePoint Online, på en Office Online Server eller i SharePoint 2013.
Overvej også at køre Workbook Size Optimizer. Det analyserer din Excel-projektmappe og komprimerer den yderligere, hvis det er muligt. Download Workbook Size Optimizer.
Denne artikel indeholder
Komprimeringsforhold og I-hukommelsesanalyseprogrammet
Datamodeller i Excel bruger I-hukommelsesanalyseprogrammet til at gemme data i hukommelsen. Programmet implementerer effektive komprimeringsteknikker for at reducere krav til lagerplads, hvilket reducerer et resultatsæt, indtil det får en brøkdel af den oprindelige størrelse.
Du kan i gennemsnit forvente, at en datamodel er 7 til 10 gange mindre end de samme data på dets oprindelsespunkt. Hvis du f.eks. importerer 7 MB data fra en SQL Server-database, kan datamodellen i Excel nemt være 1 MB eller mindre. Den grad af komprimering, der faktisk opnås, afhænger primært af antallet af entydige værdier i hver kolonne. Jo flere entydige værdier, jo mere hukommelse kræves der for at gemme dem.
Hvorfor taler vi om komprimering og unikke værdier? Da det at opbygge en effektiv model, der minimerer hukommelsesforbruget, handler det om komprimeringsmaksimering, og den nemmeste måde at gøre det på er at fjerne kolonner, du ikke har brug for, især hvis disse kolonner indeholder et stort antal entydige værdier.
Bemærk!: Forskellene i krav til lagerplads for individuelle kolonner kan være enormt store. I nogle tilfælde er det bedre at have flere kolonner med et lavt antal entydige værdier i stedet for én kolonne med et stort antal entydige værdier. Afsnittet om Datetime-optimeringer dækker denne teknik i detaljer.
Intet slår en ikke-eksisterende kolonne for lavt hukommelsesforbrug
Den mest hukommelseseffektiv kolonne er den, du aldrig importerede i første omgang. Hvis du vil oprette en effektiv model, skal du kigge på hver kolonne og spørge dig selv, om den bidrager til den analyse, du vil udføre. Hvis det ikke sker, eller du ikke er sikker, kan du lade det være. Du kan altid tilføje nye kolonner senere, hvis du har brug for dem.
To eksempler på kolonner, der altid skal udelades
Det første eksempel relaterer til data, der stammer fra et datalager. I et datalager er det normalt at finde artefakter af ETL-processer, der indlæser og opdaterer data på lageret. Kolonner som "opret dato", "opdateringsdato" og "ETL-kørsel" oprettes, når dataene indlæses. Ingen af disse kolonner er nødvendige i modellen og bør fravælges, når du importerer data.
Det andet eksempel indebærer udeladelse af kolonnen med den primære nøgle, når du importerer en faktatabel.
Mange tabeller, herunder faktatabeller, har primære nøgler. For de fleste tabeller, f.eks. dem, der indeholder kunde-, medarbejder- eller salgsdata, skal du bruge tabellens primære nøgle, så du kan bruge den til at oprette relationer i modellen.
Faktatabeller er forskellige. I en faktatabel bruges den primære nøgle til entydigt at identificere hver række. Selvom det er nødvendigt til normaliseringsformål, er det mindre nyttigt i en datamodel, hvor du kun vil bruge de kolonner, der bruges til analyse eller til at etablere tabelrelationer. Når du importerer fra en faktatabel, skal du derfor ikke medtage den primære nøgle. Primære nøgler i en faktatabel forbruger enorme mængder plads i modellen, men giver ingen fordel, da de ikke kan bruges til at oprette relationer.
Bemærk!: I datalagre og multidimensionelle databaser kaldes store tabeller, der består af primært numeriske data, ofte for "faktatabeller". Faktatabeller omfatter typisk virksomhedens ydeevne eller transaktionsdata, f.eks. salgs- og omkostningsdatapunkter, der er aggregeret og justeret efter organisationsenheder, produkter, markedssegmenter, geografiske områder osv. Alle kolonnerne i en faktatabel, der indeholder forretningsdata, eller som kan bruges til at krydsreferencedata, der er gemt i andre tabeller, skal medtages i modellen for at understøtte dataanalyse. Den kolonne, du vil udelade, er den primære nøglekolonne i faktatabellen, som består af entydige værdier, der kun findes i faktatabellen og ikke andre steder. Da faktatabeller er så store, er nogle af de største gevinster i modeleffektiviteten afledt af at udelukke rækker eller kolonner fra faktatabeller.
Sådan udelader du unødvendige kolonner
Effektive modeller indeholder kun de kolonner, du rent faktisk skal bruge i din projektmappe. Hvis du vil styre, hvilke kolonner der er inkluderet i modellen, skal du bruge guiden Tabelimport i Power Pivot-tilføjelsesprogrammet til at importere dataene i stedet for dialogboksen "Importér data" i Excel.
Når du starter guiden Tabelimport, skal du vælge, hvilke tabeller der skal importeres.
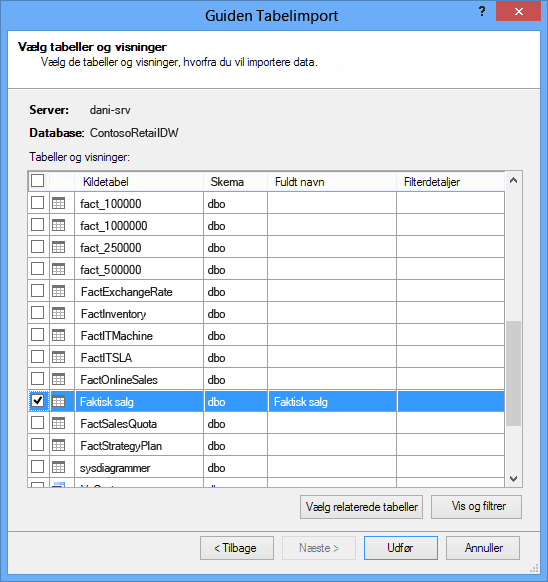
For hver tabel kan du klikke på knappen & Filtrér og vælge de dele af tabellen, du virkelig har brug for. Vi anbefaler, at du først fjerner markeringen af alle kolonner og derefter fortsætter med at kontrollere de ønskede kolonner, efter at du har overvejet, om de er nødvendige for analysen.
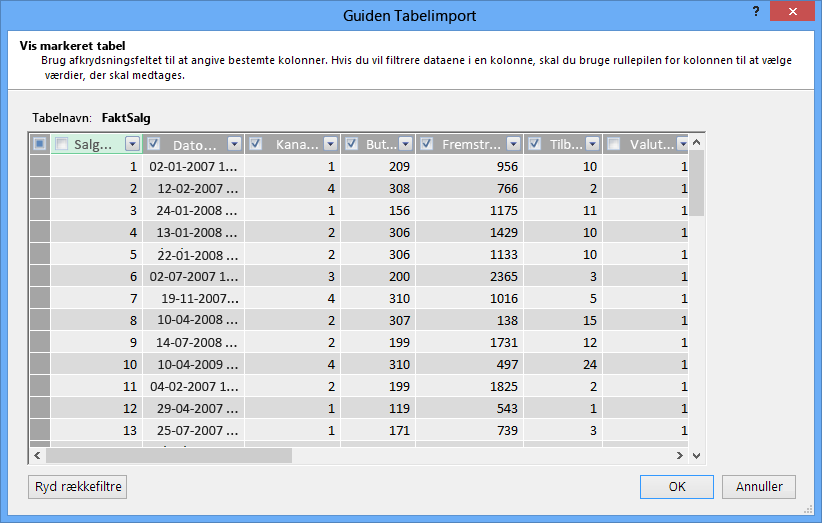
Hvad med filtrering af netop de nødvendige rækker?
Mange tabeller i virksomhedsdatabaser og datalagre indeholder historiske data, der er akkumuleret i længere tid. Desuden kan du opleve, at de tabeller, du er interesseret i, indeholder oplysninger om områder af virksomheden, der ikke er nødvendige for din specifikke analyse.
Ved hjælp af guiden Tabelimport kan du filtrere historiske eller ikke-relaterede data, og dermed spare en masse plads i modellen. På følgende billede bruges et datofilter til kun at hente rækker, der indeholder data for det aktuelle år, undtagen historiske data, der ikke er nødvendige.
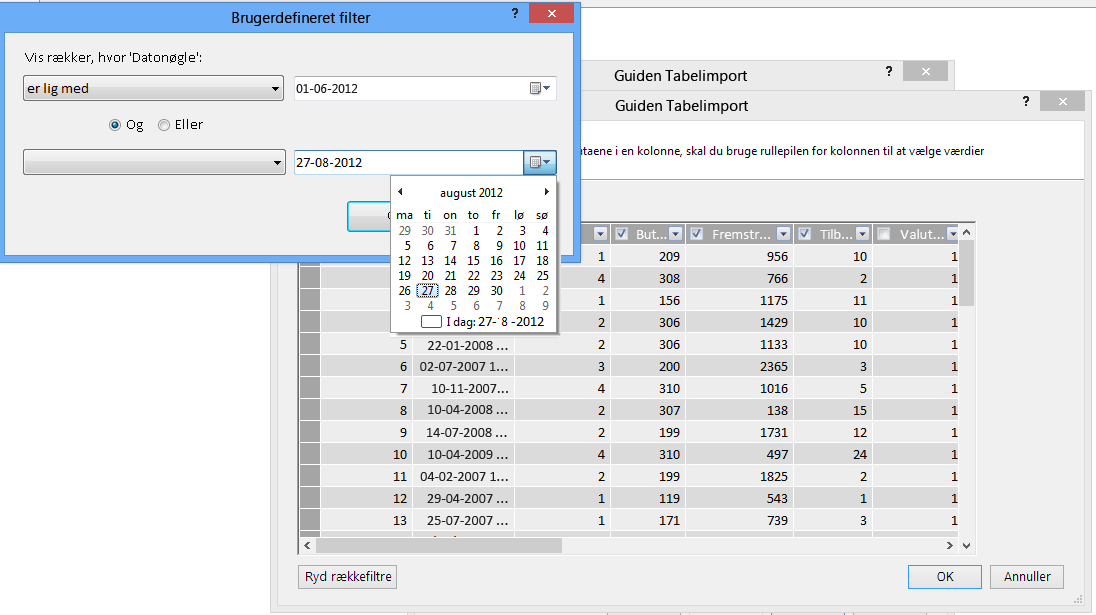
Hvad gør vi, hvis vi har brug for kolonnen? kan vi stadig reducere dens omkostninger til plads?
Der er et par yderligere teknikker, du kan anvende til at gøre en kolonne til en bedre komprimeringskandidat. Husk, at den eneste egenskab ved kolonnen, der påvirker komprimering, er antallet af entydige værdier. I dette afsnit kan du se, hvordan nogle kolonner kan ændres for at reducere antallet af entydige værdier.
Ændring af Datetime-kolonner
I mange tilfælde tager Datetime-kolonnerne en masse plads. Der er heldigvis en række måder, hvorpå du kan reducere lagerpladskravene for denne datatype. Teknikkerne varierer, afhængigt af hvordan du bruger kolonnen, og dit komfortniveau til SQL forespørgsler.
Datetime-kolonner omfatter en datodel og et klokkeslæt. Når du spørger dig selv, om du skal bruge en kolonne, kan du stille det samme spørgsmål flere gange for en Datetime-kolonne:
-
Skal jeg bruge tidsdelen?
-
Har jeg brug for tidsdelen på timeniveau? , minutter? , Sekunder? , millisekunder?
-
Har jeg flere Datetime-kolonner, fordi jeg vil beregne forskellen mellem dem eller blot for at aggregere dataene efter år, måned, kvartal osv.
Hvordan du besvarer hvert af disse spørgsmål, bestemmer dine muligheder for at håndtere kolonnen Datetime.
Alle disse løsninger kræver ændring af en SQL forespørgsel. For at gøre det nemmere at ændre forespørgsler skal du frafiltrere mindst én kolonne i hver tabel. Ved at filtrere en kolonne fra ændrer du forespørgselskonstruktion fra et forkortet format (SELECT *) til en SELECT-sætning, der indeholder fuldt kvalificerede kolonnenavne, som er meget nemmere at ændre.
Lad os se nærmere på de forespørgsler, der er oprettet til dig. Fra dialogboksen Egenskaber for tabel kan du skifte til Forespørgselseditor og se den aktuelle SQL for hver tabel.
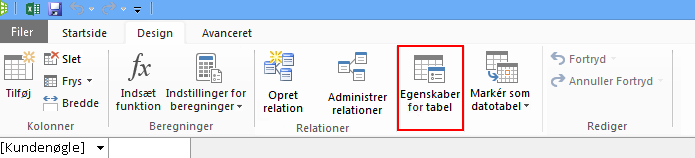
Vælg Forespørgselseditor under Egenskaber for tabel.
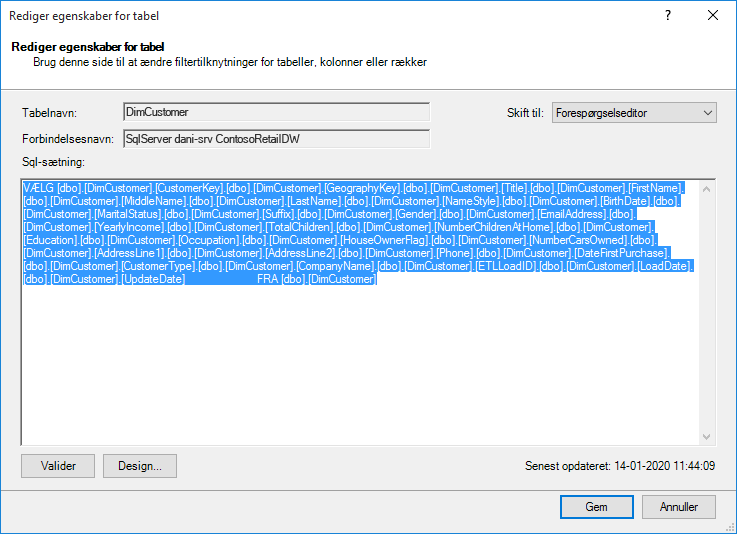
Forespørgselseditor viser den SQL, der bruges til at udfylde tabellen. Hvis du filtrerede en kolonne fra under importen, indeholder din forespørgsel fuldt kvalificerede kolonnenavne:
|
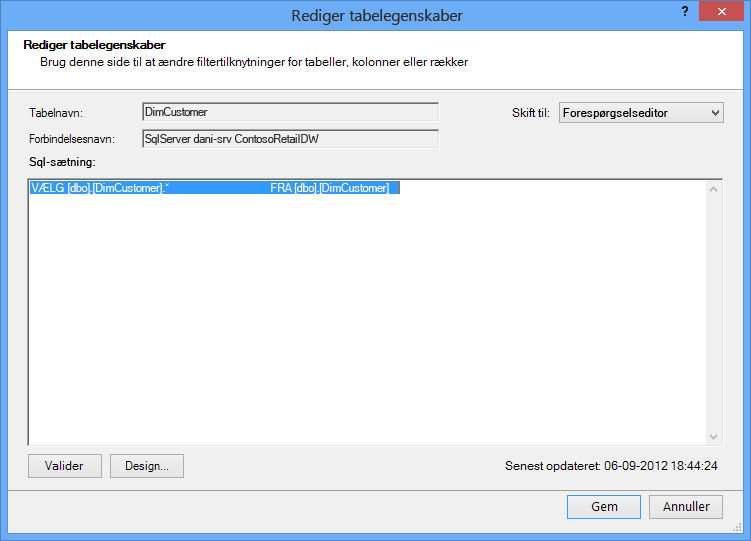
Hvis du derimod har importeret en tabel i sin helhed uden at fjerne markeringen af nogen kolonne eller anvende et filter, vises forespørgslen som "Vælg * fra", hvilket vil være sværere at ændre:
|
Ændring af SQL forespørgsel
Nu hvor du ved, hvordan du finder forespørgslen, kan du ændre den for yderligere at reducere størrelsen på modellen.
-
Hvis du ikke har brug for decimaler i kolonner, der indeholder valuta eller decimaldata, skal du bruge denne syntaks til at fjerne decimalerne:
"VÆLG AFRUND([Decimal_column_name],0)... .”
Hvis du skal bruge centne, men ikke brøkdele af cent, skal du erstatte 0 med 2. Hvis du bruger negative tal, kan du afrunde til enheder, tiere, hundredvis osv.
-
Hvis du har en Datetime-kolonne med navnet dbo. Stor kant. [Datotid] og du ikke behøver delen Tid, kan du bruge syntaksen til at fjerne klokkeslæt:
"SELECT CAST (dbo. Stor kant. [Dato klokkeslæt] som dato) AS [Dato klokkeslæt]) "
-
Hvis du har en Datetime-kolonne med navnet dbo. Stor kant. [Datotid], og du skal bruge både dato- og klokkeslætsdelen, skal du bruge flere kolonner i SQL i stedet for den enkelte Datetime-kolonne:
"SELECT CAST (dbo. Stor kant. [Dato klokkeslæt] som dato ) AS [Dato klokkeslæt],
datepart(hh, dbo. Stor kant. [Dato klokkeslæt]) som [Datotidstimer],
datepart(mi, dbo. Stor kant. [Dato klokkeslæt]) som [Datotidsminutter],
datepart(ss,dbo. Stor kant. [Dato klokkeslæt]) som [Datotidssekunder],
datepart(ms, dbo. Stor kant. [Dato klokkeslæt]) as [Date Time Milliseconds]"
Brug så mange kolonner, som du har brug for til at gemme hver del i separate kolonner.
-
Hvis du har brug for timer og minutter, og du foretrækker dem sammen som én tidskolonne, kan du bruge syntaksen:
Timefromparts(datepart(hh, dbo. Stor kant. [Dato klokkeslæt]), datodel(mm, dbo. Stor kant. [Dato klokkeslæt])) som [Datotidstimeminute]
-
Hvis du har to datetime-kolonner, f.eks. [Starttid] og [Sluttidspunktet], og det, du i virkeligheden har brug for, er tidsforskellen mellem dem i sekunder som en kolonne, der hedder [Varighed], skal du fjerne begge kolonner fra listen og tilføje:
"datediff(ss,[Startdato],[Slutdato]) som [Varighed]"
Hvis du bruger nøgleordet ms i stedet for ss, får du varigheden i millisekunder
Bruge DAX-beregnede mål i stedet for kolonner
Hvis du har arbejdet med DAX-udtrykssproget før, ved du måske allerede, at beregnede kolonner bruges til at udlede nye kolonner, der er baseret på en anden kolonne i modellen, mens beregnede mål defineres én gang i modellen, men evalueres kun, når de bruges i en pivottabel eller en anden rapport.
En hukommelsesbesparende metode er at erstatte almindelige eller beregnede kolonner med beregnede mål. Det klassiske eksempel er Enhedspris, Antal og Total. Hvis du har alle tre, kan du spare plads ved kun at vedligeholde to og beregne det tredje ved hjælp af DAX.
Hvilke to kolonner skal bevares?
I eksemplet ovenfor skal du beholde Antal og Enhedspris. Disse to har færre værdier end Totalen. For at beregne total skal du tilføje en beregnet måling som:
"TotalSalg:=sumx('Tabellen Salg','Salgstabel'[Enhedspris]*'Salgstabel'[Antal])"
Beregnede kolonner er ligesom almindelige kolonner på den måde, at de begge udgør en plads i modellen. I modsætning hertil beregnes beregnede mål på farten og tager ikke plads.
Konklusion
I denne artikel har vi talt om flere metoder, der kan hjælpe dig med at opbygge en mere hukommelseseffektiv model. Du kan reducere kravene til filstørrelse og hukommelse i en datamodel ved at reducere det samlede antal kolonner og rækker og antallet af entydige værdier, der vises i hver kolonne. Her er nogle teknikker, vi har dækket:
-
At fjerne kolonner er selvfølgelig den bedste måde at spare plads på. Beslut, hvilke kolonner du virkelig har brug for.
-
Nogle gange kan du fjerne en kolonne og erstatte den med en beregnet måling i tabellen.
-
Du behøver muligvis ikke alle rækkerne i en tabel. Du kan filtrere rækker fra i guiden Tabelimport.
-
Generelt er det en god måde at reducere antallet af entydige værdier i en kolonne ved at bryde fra hinanden i flere forskellige dele. Hver enkelt af delene har et lille antal entydige værdier, og den samlede mængde vil være mindre end den oprindelige samlede kolonne.
-
I mange tilfælde skal du også bruge de særskilte dele, der skal bruges som udsnit i dine rapporter. Når det er relevant, kan du oprette hierarkier fra dele som f.eks. Timer, Minutter og Sekunder.
-
Mange gange indeholder kolonner flere oplysninger, end du også har brug for. Antag f.eks., at en kolonne gemmer decimaler, men du har anvendt formatering for at skjule alle decimaler. Afrunding kan være meget effektiv til at reducere størrelsen på en numerisk kolonne.
Nu hvor du har gjort, hvad du kan for at reducere størrelsen på projektmappen, kan du overveje også at køre Workbook Size Optimizer. Det analyserer din Excel-projektmappe og komprimerer den yderligere, hvis det er muligt. Download Workbook Size Optimizer.
Relaterede links
Specifikation og grænser for datamodel
Power Pivot: Effektiv dataanalyse og datamodellering i Excel









