
Ez a cikk a Microsoft Excel LIN.VONAL függvényének képletszintaxisát és használatát ismerteti.
Leírás
A LIN.ILL függvény a legkisebb négyzetek módszerével kiszámolja a megadott adatokhoz legjobban illeszkedő egyenes egyenletét, és eredményként az egyenest leíró tömböt adja vissza. A LIN.ILL más függvényekkel együtt való használatával kiszámíthatja lineáris ismeretlen paraméterekkel rendelkező, más típusú (például logaritmikus, polinomiális, exponenciális és hatványsor-) modellek statisztikáit is. Mivel ez a függvény tömböt ad eredményül, tömbképletként kell bevinni. A cikkben a példákat útmutató követi.
Az egyenes egyenlete a következő:
y = mx + b
– vagy –
y = m1x1 + m2x2 + ... + b
ha több x értéktartomány is meg van adva, ahol az y értékek a független x értékek függvényei. Az m értékek az egyes x értékek együtthatói, míg a b állandó érték. Az y, az x és az m érték vektor is lehet. A LIN.ILL függvény az {mn;mn-1;...;m1;b} tömböt adja eredményül. A LIN.ILL függvény egyéb regressziós statisztikai adatokat is vissza tud adni.
Szintaxis
LIN.ILL(ismert_y; [ismert_x]; [konstans]; [stat])
A LIN.ILL függvény szintaxisa az alábbi argumentumokat foglalja magában:
Szintaxis
-
ismert_y: Megadása kötelező. Az y = mx + b összefüggésből már ismert y értékek.
-
Ha az ismert_y értékek tartománya egyetlen oszlop, akkor az ismert_x értékek minden egyes oszlopát különböző változóként értelmezi a függvény.
-
Ha az ismert_y értékek tartománya egyetlen sor, akkor az ismert_x értékek minden egyes sorát különböző változóként értelmezi a függvény.
-
-
ismert_x: Megadása nem kötelező. Az y = mx + b összefüggésből már ismert x értékek.
-
Az ismert_x értékek tartománya egy vagy több különböző változó értékeit tartalmazhatja. Ha csak egy változót használ, akkor az ismert_y és az ismert_x tetszőleges alakú, egyenlő dimenziójú tartomány lehet. Ha egynél több változót használ, akkor az ismert_y tartománynak vektornak kell lennie (amely egyetlen sor magasságú vagy egyetlen oszlop szélességű tartomány).
-
Ha az ismert_x argumentumot nem adja meg, akkor a függvény az {1. 2. 3. ...} tömböt használja, amely az ismert_x tömbbel azonos méretű.
-
-
konstans: Megadása nem kötelező. Logikai érték, amely azt határozza meg, hogy a b értéke mindenképpen 0 legyen-e.
-
Ha a konstans értéke IGAZ vagy hiányzik, akkor a függvény a b értéket korlátozás nélkül számolja ki.
-
Ha a konstans értéke HAMIS, akkor a b értéke 0 lesz, az m értékeket pedig az y = mx egyenlet alapján számolja ki a függvény.
-
-
stat: Megadása nem kötelező. Logikai érték, amely azt határozza meg, hogy a függvény kiegészítő regressziós statisztikai adatokat is számoljon-e.
-
Ha a statisztikák ÉRTÉKE IGAZ, akkor a LIN.T a további regressziós statisztikákat adja vissza; Ennek eredményeként a visszaadott tömb { mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Ha a stat argumentum értéke HAMIS vagy hiányzik, akkor a LIN.ILL csak az m együtthatókat és a b állandót adja eredményül.
A kiegészítő regressziós adatok a következők:
-
|
Adat |
Leírás |
|---|---|
|
se1, se2, ..., sen |
Az m1, m2, ..., mn együtthatók standard hibáinak értékei. |
|
seb |
A b állandó standard hibájának értéke (seb = #HIÁNYZIK, ha a konstans értéke HAMIS). |
|
r2 |
A meghatározási együttható. Összehasonlítja a becsült és a tényleges y értékeket, valamint a 0 és 1 közötti értéktartományokat. Ha 1, akkor a mintában tökéletes korreláció van – nincs különbség a becsült y érték és a tényleges y érték között. Ha a meghatározási együttható 0, a regressziós egyenlet nem hasznos az y érték előrejelzésében. A2 számításának módjáról a jelen témakör "Megjegyzések" című szakaszában olvashat bővebben. |
|
sey |
Az y becsléséhez tartozó standard hiba. |
|
F |
Az F-próba eredményeként kapott érték. Az F-próba segítségével megállapítható, hogy a független és a függő változók között megfigyelt kapcsolat véletlenszerű-e. |
|
df |
A szabadság foka. A szabadságfokok segítségével megtalálhatja az F-kritikus értékeket egy statisztikai táblában. Hasonlítsa össze a táblázatban található értékeket a LIN.T által visszaadott F statisztikai adatokkal a modell megbízhatósági szintjének meghatározásához. A df kiszámításáról a jelen témakör "Megjegyzések" című szakaszában olvashat bővebben. A 4. példa az F és a df használatát mutatja be. |
|
ssreg |
A regressziós négyzetösszeg. |
|
ssresid |
A maradék négyzetösszeg. Az ssreg és ssresid kiszámításának módját a „Megjegyzések” szakasz ismerteti. |
A következő táblázat azt mutatja be, hogy a függvény milyen sorrendben adja meg a kiegészítő regressziós statisztikai adatokat.

Megjegyzések
-
Minden egyenes egyenlete megadható meredekségének és az y tengellyel való metszéspontjának segítségével:
Meredekség (m):
A gyakran m-ként írt egyenes meredekségének megkereséséhez vegyen két pontot a vonalon (x1,y1) és (x2,y2); a meredekség egyenlő (y2 - y1)/(x2 - x1).Y-metszéspont (b):
Egy vonal y-metszete, amelyet gyakran b-ként írnak, az y értéke azon a ponton, ahol a vonal átlépi az y tengelyt.Az egyenes egyenlete y = mx + b. Ha ismeri az m és a b értéket, akkor az egyenes tetszőleges pontjának koordinátái kiszámíthatók az ismert x vagy y érték behelyettesítésével. Emellett használhatja a TREND függvényt is.
-
Ha csak egyetlen független x-változóval dolgozik, akkor a meredekséget és az egyenes y tengellyel való metszéspontját a következő függvények felhasználásával kaphatja meg közvetlenül:
Lejtő:
=INDEX(LIN.ILL(known_y;known_x);1)Y-metszéspont:
=INDEX(LIN.ILL(known_y;known_x);2) -
A LIN.ILL függvénnyel kiszámolt egyenes pontossága függ a felhasznált adatok szórásának nagyságától. A függő és a független változók kapcsolata minél inkább közelít a lineárishoz, annál pontosabb a LIN.ILL modell. A LIN.ILL a legkisebb négyzetek módszerét használja az adatokhoz legjobban illeszkedő egyenes meghatározására. Ha csak egyetlen független x változóval dolgozik, akkor az m és a b érték kiszámítása a következő egyenletek segítségével történik:
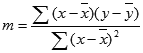
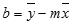
ahol x és y az adatok középértékei, tehát x = ÁTLAG(ismert_ x) és y = ÁTLAG(ismert_y).
-
A LIN.ILL és a LOGEST vonal- és görbeillesztési függvények az adatoknak leginkább megfelelő egyenes vagy exponenciális görbét számíthatják ki. Azonban el kell döntenie, hogy a két eredmény közül melyik felel meg a legjobban az adatainak. Kiszámíthatja a TREND(known_y,known_x) értékét egy egyeneshez, vagy a GROWTH(known_y, known_x) képletet exponenciális görbére. Ezek a függvények a new_x argumentuma nélkül az adott vonal vagy görbe mentén előrejelzett y értékek tömbjét adnak vissza a tényleges adatpontoknál. Ezután összehasonlíthatja az előrejelzett értékeket a tényleges értékekkel. A vizualizációk összehasonlításához érdemes lehet mindkettőt ábrázolni.
-
A regresszióanalízis során a Microsoft Excel kiszámítja az egyes becsült és tényleges y értékek eltéréseinek négyzetét. Ezeknek az eltérésnégyzeteknek az összege a maradék négyzetösszeg, ssresid. Az Excel ezután kiszámítja a négyzetek teljes összegét, az sstotal értéket. Ha a konstans argumentum értéke IGAZ vagy nincs megadva, akkor a teljes négyzetösszeg egyenlő az y értékek átlagának és a tényleges y értékek eltéréseinek négyzetösszegével. Ha a konstans argumentum értéke HAMIS, akkor a teljes négyzetösszeg a tényleges y értékek négyzetösszege (az y értékek átlagának az egyes y értékekből történő kivonása nélkül). A regressziós négyzetösszeg – ssreg – a következőképpen számítható ki: ssreg = sstotal - ssresid. Minél kisebb a négyzetek reziduálisösszege a négyzetek teljes összegével összehasonlítva, annál nagyobb az r2 meghatározási együttható értéke, amely azt jelzi, hogy a regresszióelemzésből származó egyenlet mennyire jól magyarázza a változók közötti kapcsolatot. Az r2 értéke ssreg/sstotal.
-
Bizonyos esetekben előfordulhat, hogy egy vagy több X oszlop (feltételezve, hogy az Y és az X oszlopban található) nem feltétlenül rendelkezik további prediktív értékkel a többi X oszlop jelenlétében. Más szóval egy vagy több X oszlop megszüntetése olyan előrejelzett Y értékekhez vezethet, amelyek egyformán pontosak. Ebben az esetben ezeket a redundáns X oszlopokat ki kell hagyni a regressziós modellből. Ezt a jelenséget "kollinearitásnak" nevezik, mert minden redundáns X oszlop a nem redundáns X oszlopok többszöröseinek összegeként fejezhető ki. A LIN.VONAL függvény ellenőrzi a kollinearitást, és eltávolítja a redundáns X oszlopokat a regressziós modellből, amikor azonosítja őket. Az eltávolított X oszlopok a LINEST kimenetben 0 együtthatóként ismerhetők fel a 0 se értékek mellett. Ha egy vagy több oszlopot redundánsként távolít el, a df az érintett, mert a df a prediktív célokra ténylegesen használt X oszlopok számától függ. A df számításával kapcsolatos részletekért lásd a 4. példát. Ha a redundáns X oszlopok eltávolítása miatt a df módosul, a sey és az F értékei is érintettek lesznek. A kollinearitásnak a gyakorlatban viszonylag ritkanak kell lennie. Az egyik eset azonban, amikor nagyobb a valószínűsége annak, hogy egyes X oszlopok csak 0 és 1 értéket tartalmaznak annak jelzéseként, hogy egy kísérlet tárgya egy adott csoport tagja-e vagy sem. Ha a const = IGAZ vagy nincs megadva, a LIN.ELT függvény hatékonyan beszúr egy további X oszlopot mind az 1 értékből az metszéspont modellezéséhez. Ha egy oszlopban minden tárgyhoz 1 tartozik, ha férfi, vagy 0, ha nem, és van egy oszlopa is, amelyben minden tárgyhoz tartozik egy 1, ha nő, vagy 0, ha nem, ez utóbbi oszlop redundáns, mert a benne lévő bejegyzések a "férfi mutató" oszlop bejegyzésének kivonásából nyerhetők ki a LIN.T függvény által hozzáadott 1 érték további oszlopában lévő bejegyzésből.
-
Ha kollinearitás miatt nem kellett eltávolítani egyetlen X oszlopot sem, akkor a df értékét a következőképpen lehet kiszámolni: ha k darab ismert_x oszlop van és a konstans = IGAZ vagy hiányzik: df = n – k – 1. Ha a konstans = HAMIS: df = n - k. A kollinearitás miatt eltávolított minden egyes oszlop mindkét esetben 1-gyel növeli a df értékét.
-
Ha argumentumként tömböt ad meg (ilyen lehet például az ismert_x értékek tömbje), akkor az egy sorba tartozó értékeket ponttal, az egyes sorokat pontosvesszővel válassza el egymástól. A listaelválasztó karakterek a területi beállításoktól függenek.
-
Ne feledje, hogy a regressziós egyenlet által előre jelzett y értékek nem alkalmazhatók, ha kívül esnek az egyenlet meghatározására megadott y értékek tartományán.
-
A LIN.ILL függvény mögöttes algoritmusa eltér a MEREDEKSÉG és a METSZ függvényétől. Az algoritmusok különbözősége eltérő eredményekhez vezethet, ha az adatok határozatlanok és kollineárisak. Ha például az ismert_y adatpontok 0 értékűek, illetve az ismert_x adatpontjai 1 értékűek:
-
A LIN.ILL függvény értéke 0. A LIN.ILL algoritmus úgy van kialakítva, hogy kollineáris adatok esetén ésszerű eredményeket adjon, és ebben az esetben legalább egy válasz létezik.
-
A MEREDEKSÉG és a METSZ függvény értéke #ZÉRÓOSZTÓ! hiba. A MEREDEKSÉG és a METSZ algoritmus úgy van kialakítva, hogy kizárólag egy választ keressen, és ebben az esetben egynél több válasz lehetséges.
-
-
Azonfelül, hogy a LOG.ILL függvény segítségével statisztikai számításokat végezhet más típusú regressziók esetében, a LIN.ILL segítségével számításokat végezhet sok más regressziótípus esetében, ha az x és y változók függvényét x és y sorozatok formájában megadja a LIN.ILL függvénynek. Például a következő képlet:
=LIN.ILL(yértékek; xértékek^OSZLOP($A:$C))
akkor használható, ha az y és x értékek egy-egy oszlopban találhatók, és a következő egyenlet köbös (harmadrendű polinomiális) közelítését szeretné kiszámítani:
y = m1*x + m2*x^2 + m3*x^3 + b
E képlet módosított változataival kiszámíthat más típusú regressziót is, egyes esetekben azonban módosítani kell a kimeneti értékeket és más statisztikákat.
-
A LIN.ILL függvény által visszaadott F-próba érték eltér az F.PRÓBA függvény által adott F-próba értékétől. A LIN.ILL függvény a statisztikai F értékét adja meg, míg az F.PRÓBA függvény a valószínűséget.
Példák
1. példa: A meredekség és az Y-metszéspont meghatározása
Másolja a mintaadatokat az alábbi táblázatból, és illessze be őket egy új Excel-munkalap A1 cellájába. Ha azt szeretné, hogy a képletek megjelenítsék az eredményt, jelölje ki őket, és nyomja le az F2, majd az Enter billentyűt. Szükség esetén módosíthatja az oszlopok szélességét, hogy az összes adat látható legyen.
|
Ismert y |
Ismert x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Eredmény (meredekség) |
Eredmény (y-metszéspont) |
|
2 |
1 |
|
Képlet (tömbképlet az A7:B7 cellatartományban) |
|
|
=LIN.ILL(A2:A5;B2:B5;;HAMIS) |
2. példa: Egyszerű lineáris regresszió
Másolja a mintaadatokat az alábbi táblázatból, és illessze be őket egy új Excel-munkalap A1 cellájába. Ha azt szeretné, hogy a képletek megjelenítsék az eredményt, jelölje ki őket, és nyomja le az F2, majd az Enter billentyűt. Szükség esetén módosíthatja az oszlopok szélességét, hogy az összes adat látható legyen.
|
Hónap |
Értékesítés |
|---|---|
|
1 |
3100 USD |
|
2 |
4500 USD |
|
3 |
4400 USD |
|
4 |
5400 USD |
|
5 |
7500 USD |
|
6 |
8100 USD |
|
Képlet |
Eredmény |
|
=SZUM(LIN.ILL(B1:B6;A1:A6)*{9;1}) |
1 100 000 Ft |
|
A kilencedik hónap értékesítéseinek becslését számítja ki a 1–6. hónap értékesítési alapján. |
3. példa: Többszörös lineáris regresszió
Másolja a mintaadatokat az alábbi táblázatból, és illessze be őket egy új Excel-munkalap A1 cellájába. Ha azt szeretné, hogy a képletek megjelenítsék az eredményt, jelölje ki őket, és nyomja le az F2, majd az Enter billentyűt. Szükség esetén módosíthatja az oszlopok szélességét, hogy az összes adat látható legyen.
|
Hasznos alapterület (x1) |
Irodák száma (x2) |
Bejáratok száma (x3) |
Az épület kora (x4) |
Az irodaépület becsült értéke (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
14 200 000 Ft |
|
2333 |
2 |
2 |
12 |
14 400 000 Ft |
|
2356 |
3 |
1,5 |
33 |
15 100 000 Ft |
|
2379 |
3 |
2 |
43 |
15 000 000 Ft |
|
2402 |
2 |
3 |
53 |
13 900 000 Ft |
|
2425 |
4 |
2 |
23 |
16 900 000 Ft |
|
2448 |
2 |
1,5 |
99 |
12 600 000 Ft |
|
2471 |
2 |
2 |
34 |
14 290 000 Ft |
|
2494 |
3 |
3 |
23 |
16 300 000 Ft |
|
2517 |
4 |
4 |
55 |
16 900 000 Ft |
|
2540 |
2 |
3 |
22 |
14 900 000 Ft |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Képlet (az A19-ben megadott dinamikus tömbképlet) |
||||
|
=LIN.ILL(E2:E12;A2:D12;IGAZ;IGAZ) |
4. példa – Az F és r2 statisztika használata
Az előző példában a meghatározási együttható (r2) 0,99675 (lásd az A17 cellát a LIN.ILL kimenetében), ami erős kapcsolatot jelez a független változók és az eladási ár között. Az F-próba segítségével megállapíthatja, hogy ezek az eredmények, például a magas r2 érték, véletlenszerűek-e.
Tegyük fel, hogy nincs tényleges kapcsolat a változók között, és hogy csak véletlenül választotta ki pont azt a 11 irodaházat mintaként, amelyek a statisztikai elemzéskor szoros kapcsolatot mutattak. Alfa értéke adja meg, hogy mi a valószínűsége annak, hogy következtetése hibás volt, és az eredmények alapján feltételezett kapcsolat nem létezik.
A LIN.T függvény kimenetében szereplő F és df értékek felhasználhatók annak a valószínűségének felmérésére, hogy egy nagyobb F érték véletlenszerűen következik-e be. Az F összehasonlítható a közzétett F-eloszlási táblázatokban szereplő kritikus értékekkel, vagy az Excel FDIST függvényével kiszámítható, hogy mekkora valószínűséggel fordul elő nagyobb F érték. A megfelelő F eloszlás v1 és v2 szabadságfokkal rendelkezik. Ha n az adatpontok száma, és konstans = IGAZ vagy kihagyva, akkor v1 = n – df – 1 és v2 = df. (Ha const = HAMIS, akkor v1 = n – df és v2 = df.) Az F.ELOSZLÁS függvény – az F.ELOSZLÁS(F;v1;v2) szintaxissal – a véletlen nagyobb F érték valószínűségét adja vissza. Ebben a példában df = 6 (B18 cella) és F = 459,753674 (A18 cella).
Ha az Alfa érték 0,05, v1 = 11 – 6 – 1 = 4 és v2 = 6, az F kritikus szintje 4,53. Mivel az F = 459,753674 sokkal magasabb, mint 4,53, rendkívül valószínűtlen, hogy egy ilyen magas F érték véletlenszerűen következett be. (Alfa = 0,05 esetén az a hipotézis, hogy nincs kapcsolat known_y és known_x között, el kell utasítani, ha az F meghaladja a kritikus szintet, 4,53.) Az Excel F.ELOSZLÁS függvényével megadhatja annak valószínűségét, hogy egy ilyen magas F érték véletlenszerűen következett be. Az F.ELOSZLÁS(459,753674; 4; 6) = 1,37E-7, rendkívül kis valószínűség. Arra a következtetésre juthat, hogy az F kritikus szintjét egy táblázatban vagy az F.ELOSZLÁS függvénnyel állapíthatja meg, hogy a regressziós egyenlet hasznos lehet az ezen a területen található irodaépületek értékelt értékének előrejelzéséhez. Ne feledje, hogy kritikus fontosságú az előző bekezdésben kiszámított v1 és v2 helyes értékeinek használata.
5. példa: A t-próba
Egy másik hipotézisvizsgálat meghatározza, hogy az egyes meredekség-együtthatók hasznosak-e egy irodaépület értékelt értékének becsléséhez a 3. példában. Ha például a kor együtthatóját statisztikai pontosságra szeretné tesztelni, ossza el a -234,24-et (kor meredekségi együtthatóját) 13,268-tal (az A15 cellában található kor együttható becsült szórása). A t-megfigyelt érték a következő:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Ha a t abszolút értéke kellően magas, arra a következtetésre juthat, hogy a meredekség együtthatója hasznos egy irodaépület értékelt értékének becsléséhez a 3. példában. Az alábbi táblázat a 4 t megfigyelt érték abszolút értékeit mutatja be.
Ha egy statisztikai kézikönyvben egy táblázatot tekint meg, akkor azt fogja tapasztalni, hogy a t-kritikus, kétszélű, 6 szabadságfokkal és alfa = 0,05 2,447. Ez a kritikus érték az Excel TINV függvényével is megtalálható. TINV(0,05;6) = 2,447. Mivel a t abszolút értéke (17,7) nagyobb, mint 2,447, az életkor fontos változó egy irodaépület értékelt értékének becslésekor. A többi független változó is hasonló módon tesztelhető statisztikai jelentőséggel. Az alábbiakban az egyes független változók t-megfigyelt értékei szerepelnek.
|
Változó |
Mintából számított t érték |
|---|---|
|
hasznos alapterület |
5,1 |
|
irodák száma |
31,3 |
|
bejáratok száma |
4,8 |
|
az épület kora |
17,7 |
Mindegyik szám abszolút értéke nagyobb 2,447-nél, vagyis a regressziós egyenletben használt változók mindegyike fontos az ebben az övezetben lévő épületek értékének becsléséhez.









