
Az Excel 2013-ban vagy újabb verzióiban több millió sort tartalmazó adatmodelleket hozhat létre, majd hatékony adatelemzést végezhet ezeken a modelleken. Az adatmodellek a Power Pivot bővítménnyel vagy anélkül hozhatók létre, hogy tetszőleges számú kimutatást, diagramot és Power View-vizualizációt támogassanak ugyanabban a munkafüzetben.
Megjegyzés: Ez a cikk az Excel 2013 adatmodelljeit ismerteti. Az Excel 2013-ban bevezetett adatmodellezési és Power Pivot-funkciók azonban a Excel 2016 is érvényesek. Az Excel ezen verziói között gyakorlatilag kevés a különbség.
Bár az Excelben egyszerűen készíthet hatalmas adatmodelleket, több oka is van annak, hogy ne. Először is a sok táblát és oszlopot tartalmazó nagyméretű modellek túlillednek a legtöbb elemzéshez, és nehézkes mezőlistát alkotnak. Másodszor, a nagyméretű modellek értékes memóriát használnak fel, ami negatív hatással van az azonos rendszererőforrásokat használó más alkalmazásokra és jelentésekre. Végül a Microsoft 365-ben a SharePoint Online és az Excel Web App is 10 MB-ra korlátozza az Excel-fájlok méretét. A több millió sort tartalmazó munkafüzet-adatmodellek esetében elég gyorsan eléri a 10 MB-os korlátot. Lásd: Adatmodell specifikációja és korlátai.
Ebből a cikkből megtudhatja, hogyan hozhat létre egy szorosan felépített modellt, amely könnyebben használható és kevesebb memóriát használ. Ha időt vesz igénybe a hatékony modelltervezés ajánlott eljárásainak megismerésére, azzal minden létrehozott és használt modellért kifizetődő lesz, akár az Excel 2013-ban, Microsoft 365 a SharePoint Online-ban, egy Office Web Apps Serveren vagy a SharePoint 2013-ban tekinti meg.
Érdemes lehet futtatni a Munkafüzetméret-optimalizálót is. Elemzi az Excel-munkafüzetet, és ha lehetséges, tovább tömöríti. Töltse le a Munkafüzetméret-optimalizálót.
A témakör tartalma
Tömörítési arányok és a memóriabeli elemzési motor
Az Excel adatmodelljei a memórián belüli elemzési motorral tárolják az adatokat a memóriában. A motor hatékony tömörítési technikákat alkalmaz a tárolási követelmények csökkentése érdekében, és zsugorítja az eredményhalmazt, amíg az eredeti méret töredékére nem kerül.
Az adatmodellek átlagosan 7–10-szer kisebbek lehetnek, mint ugyanazok az adatok a kiindulási helyén. Ha például 7 MB-ot importál egy SQL Server-adatbázisból, az Excel adatmodellje könnyen 1 MB vagy kevesebb lehet. A ténylegesen elért tömörítés mértéke elsősorban az egyes oszlopok egyedi értékeinek számától függ. Minél egyedibb értékekről van szó, annál több memóriára van szükség a tárolásukhoz.
Miért beszélünk tömörítésről és egyedi értékekről? Mivel a memóriahasználatot minimalizáló hatékony modell létrehozása a tömörítés maximalizálásáról szól, és ennek legegyszerűbb módja az, ha megszabadul azoktól az oszlopoktól, amelyekre nincs igazán szüksége, különösen akkor, ha ezek az oszlopok nagyszámú egyedi értéket tartalmaznak.
Megjegyzés: Az egyes oszlopok tárolási követelményeinek eltérései hatalmasak lehetnek. Bizonyos esetekben jobb, ha több, alacsony számú egyedi értékkel rendelkező oszlopot tartalmaz, nem pedig egy nagy számú egyedi értékkel rendelkező oszlopot. A Datetime-optimalizálásról szóló szakasz részletesen ismerteti ezt a technikát.
Semmi sem veri meg a nem létező oszlopot alacsony memóriahasználat esetén
A memóriahatékonyabb oszlop az, amelyet soha nem importált. Ha hatékony modellt szeretne létrehozni, tekintse meg az egyes oszlopokat, és kérdezze meg magától, hogy az hozzájárul-e a végrehajtani kívánt elemzéshez. Ha nem, vagy nem biztos benne, hagyja ki. Később bármikor hozzáadhat új oszlopokat, ha szüksége van rájuk.
Két példa olyan oszlopokra, amelyeket mindig ki kell zárni
Az első példa egy adattárházból származó adatokra vonatkozik. Az adattárházakban gyakran találhatók olyan ETL-folyamatok összetevői, amelyek betöltik és frissítik az adatokat a raktárban. Az adatok betöltésekor olyan oszlopok jönnek létre, mint a "létrehozási dátum", a "frissítés dátuma" és az "ETL-futtatás". Ezen oszlopok egyikére sem van szükség a modellben, és az adatok importálásakor ki kell őket jelölni.
A második példa az elsődleges kulcs oszlop kihagyását foglalja magában egy ténytábla importálásakor.
Számos tábla, beleértve a ténytáblákat is, elsődleges kulcsokkal rendelkezik. A legtöbb tábla, például az ügyfél-, alkalmazott- vagy értékesítési adatokat tartalmazó táblák esetében a tábla elsődleges kulcsára lesz szüksége, hogy a használatával kapcsolatokat hozhasson létre a modellben.
A ténytáblák eltérőek. A ténytáblákban az elsődleges kulcs az egyes sorok egyedi azonosítására szolgál. Bár normalizálási célokra szükséges, kevésbé hasznos olyan adatmodellekben, ahol csak az elemzéshez vagy táblakapcsolatok létesítéséhez használt oszlopokat szeretné használni. Ezért a ténytáblából való importáláskor ne tartalmazza az elsődleges kulcsot. A ténytáblák elsődleges kulcsai hatalmas mennyiségű helyet foglalnak el a modellben, de nem biztosítanak előnyt, mivel nem használhatók kapcsolatok létrehozására.
Megjegyzés: Az adattárházakban és a többdimenziós adatbázisokban a többnyire numerikus adatokat tartalmazó nagy táblákat gyakran "ténytábláknak" is nevezik. A ténytáblák általában üzleti teljesítményt vagy tranzakciós adatokat tartalmaznak, például értékesítési és költségadatokat, amelyek a szervezeti egységekhez, termékekhez, piaci szegmensekhez, földrajzi régiókhoz stb. vannak összesítve és igazítva. Az adatelemzés támogatásához egy ténytábla minden olyan oszlopát bele kell foglalni a modellbe, amely üzleti adatokat tartalmaz, vagy amelyek más táblákban tárolt adatok kereszthivatkozására használhatók. A kizárni kívánt oszlop a ténytábla elsődleges kulcsoszlopa, amely olyan egyedi értékekből áll, amelyek csak a ténytáblában léteznek, és sehol máshol. Mivel a ténytáblák annyira hatalmasak, a modellhatékonyság néhány legnagyobb előnye abból származik, hogy kizárunk sorokat vagy oszlopokat a ténytáblákból.
A szükségtelen oszlopok kizárása
A hatékony modellek csak azokat az oszlopokat tartalmazzák, amelyekre ténylegesen szüksége lesz a munkafüzetben. Ha szabályozni szeretné, hogy mely oszlopok szerepeljenek a modellben, a Power Pivot bővítmény Tábla importálása varázslóját kell használnia az adatok importálásához az Excel "Adatok importálása" párbeszédpanelje helyett.
A Tábla importálása varázsló elindításakor kiválaszthatja, hogy mely táblákat szeretné importálni.
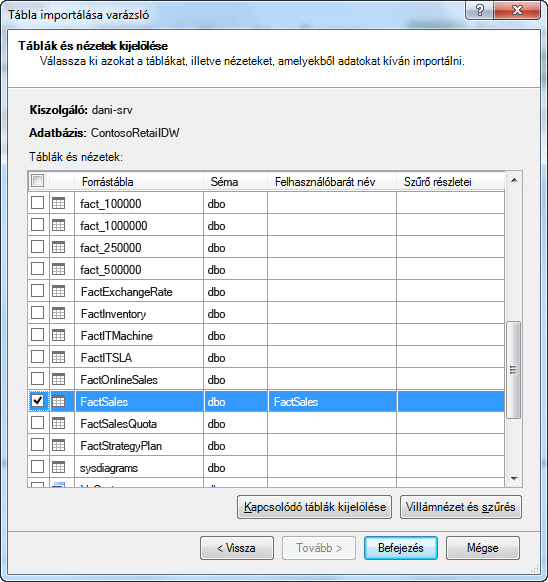
Minden táblához kattintson az Előnézet & Szűrő gombra, és válassza ki a táblázat azon részeit, amelyekre valóban szüksége van. Azt javasoljuk, hogy először törölje az összes oszlop jelölését, majd folytassa a kívánt oszlopok ellenőrzésével, miután megvizsgálta, hogy szükségesek-e az elemzéshez.
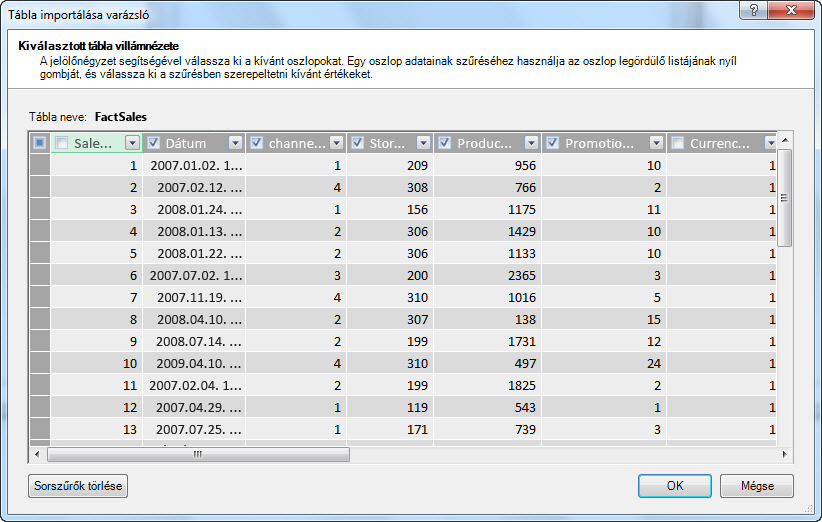
Mi a helyzet azzal, ha csak a szükséges sorokat szűri?
A vállalati adatbázisok és adattárházak számos táblája hosszú idő alatt összegyűjtött előzményadatokat tartalmaz. Emellett azt is tapasztalhatja, hogy a kívánt táblák az adott elemzéshez nem szükséges üzleti területekre vonatkozó információkat tartalmaznak.
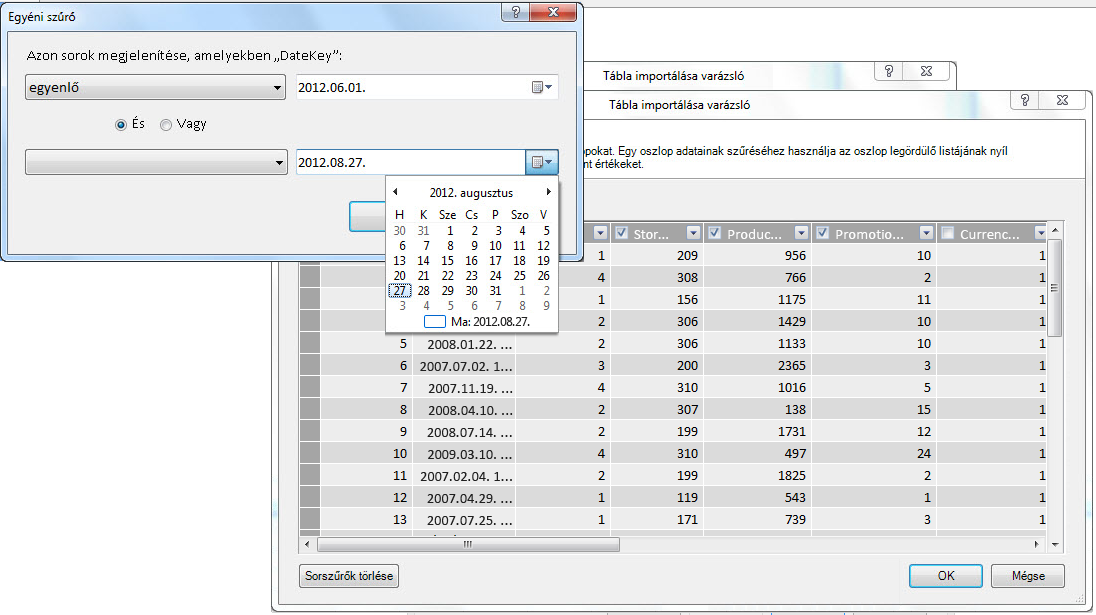
A Tábla importálása varázslóval kiszűrheti az előzményadatokat vagy a nem kapcsolódó adatokat, így sok helyet takaríthat meg a modellben. Az alábbi képen egy dátumszűrővel csak az aktuális évre vonatkozó adatokat tartalmazó sorok kérhetők le, kivéve az előzményadatokat, amelyekre nincs szükség.
Mi van, ha szükségünk van az oszlopra; továbbra is csökkenthetjük a terület költségeit?
Néhány további technikát is alkalmazhat arra, hogy az oszlopokat jobb tömörítési jelöltként használhassa. Ne feledje, hogy a tömörítést befolyásoló oszlop egyetlen jellemzője az egyedi értékek száma. Ebben a szakaszban megtudhatja, hogyan módosíthatók egyes oszlopok az egyedi értékek számának csökkentése érdekében.
Datetime-oszlopok módosítása
A Datetime oszlopok sok esetben sok helyet foglalnak el. Szerencsére számos módon csökkenthetők az adattípus tárolási követelményei. A technikák az oszlop használatának módjától és az SQL-lekérdezések készítésének kényelmi szintjétől függenek.
A datetime oszlopok egy dátumrészt és egy időpontot tartalmaznak. Amikor megkérdezi magától, hogy szüksége van-e egy oszlopra, tegye fel ugyanazt a kérdést többször is egy Datetime oszlop esetében:
-
Szükségem van az idő részre?
-
Szükség van az időrészre az órák szintjén? Perc? Másodperc? Ezredmásodperc?
-
Több Datetime oszlopom van, mert ki szeretném számítani a köztük lévő különbséget, vagy csak az adatok év, hónap, negyedév stb. szerinti összesítésére van szükségem.
Az egyes kérdések megválaszolása határozza meg a Datetime oszlop kezelésének lehetőségeit.
Mindegyik megoldáshoz módosítani kell egy SQL-lekérdezést. A lekérdezés módosításának megkönnyítése érdekében minden tábla legalább egy oszlopát ki kell szűrnie. Egy oszlop szűrésével a lekérdezés szerkezetét rövidített formátumról (SELECT *) egy SELECT utasításra módosítja, amely teljesen minősített oszlopneveket tartalmaz, amelyek sokkal könnyebben módosíthatók.
Vessünk egy pillantást az Ön számára létrehozott lekérdezésekre. A Tábla tulajdonságai párbeszédpanelen átválthat a Lekérdezésszerkesztőre, és megtekintheti az egyes táblák aktuális SQL-lekérdezését.

A Tábla tulajdonságai területen válassza a Lekérdezésszerkesztő lehetőséget.
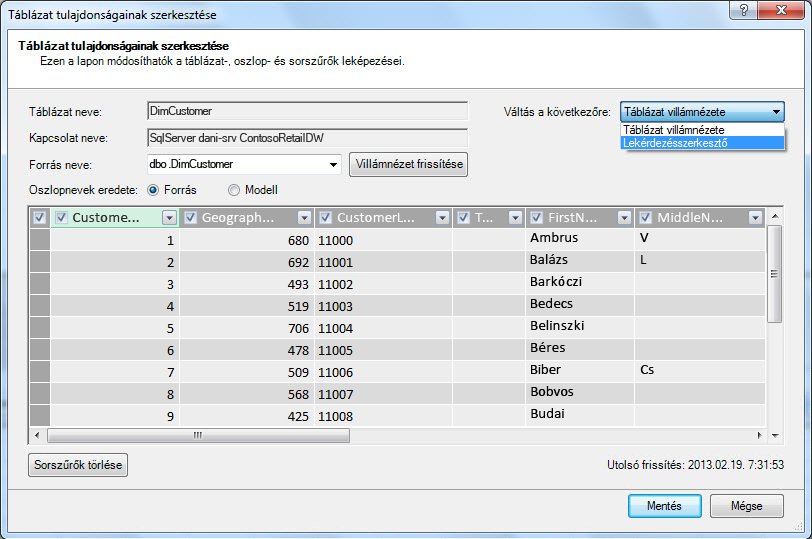
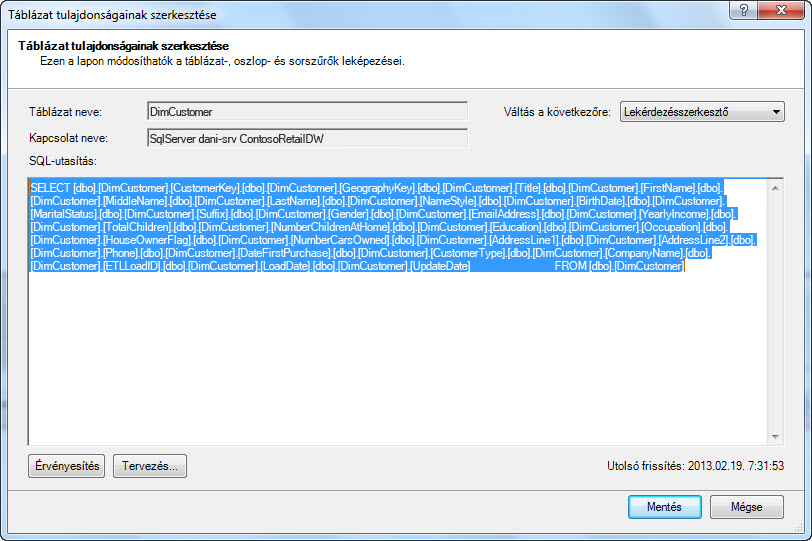
A Lekérdezésszerkesztő a tábla feltöltéséhez használt SQL-lekérdezést jeleníti meg. Ha az importálás során szűrt egy oszlopot, a lekérdezés teljes oszlopneveket tartalmaz:
|
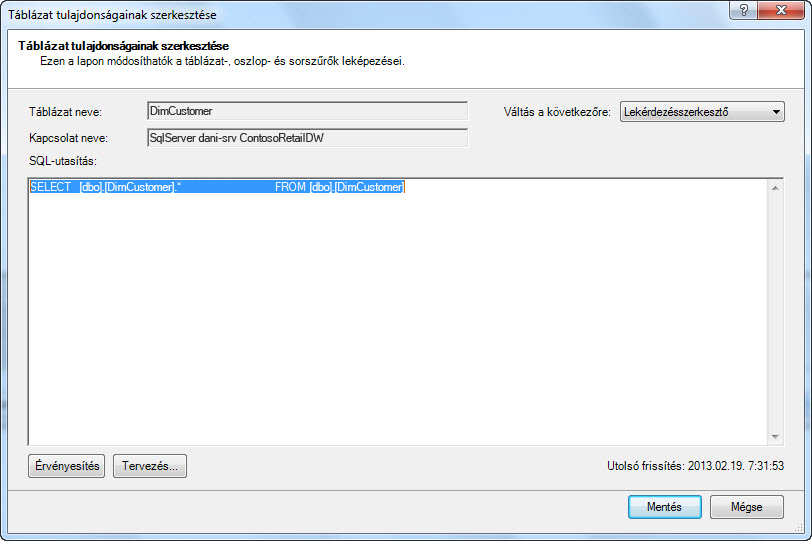
Ezzel szemben, ha egy táblát teljes egészében importált anélkül, hogy egyetlen oszlopot sem jelölne ki, vagy szűrőt alkalmaz, a lekérdezés a következőként jelenik meg: "Select * from ", ami nehezebben módosítható:
|
Az SQL-lekérdezés módosítása
Most, hogy már tudja, hogyan találhatja meg a lekérdezést, módosíthatja a modell méretének további csökkentése érdekében.
-
Pénznemet vagy decimális adatokat tartalmazó oszlopok esetén, ha nincs szüksége a tizedes törtekre, ezzel a szintaxissal szabadulhat meg a tizedesvesszőktől:
"SELECT ROUND([Decimal_column_name],0)... .”
Ha szüksége van a centekre, de a centek törtrészére nem, cserélje le a 0-t 2-re. Ha negatív számokat használ, kerekítheti mértékegységre, tízre, százra stb.
-
Ha van egy dbo nevű Datetime oszlopa. Nagytáblás. [Dátum időpontja] és nincs szüksége az Idő részre, a szintaxis használatával szabadulhat meg az időtől:
"SELECT CAST (dbo. Nagytáblás. [Date time] as date) AS [Date time]) "
-
Ha van egy dbo nevű Datetime oszlopa. Nagytáblás. [Dátum időpontja] és a Dátum és az Idő részre is szüksége van, használjon több oszlopot az SQL-lekérdezésben az egyetlen Datetime oszlop helyett:
"SELECT CAST (dbo. Nagytáblás. [Date Time] as date ) AS [Date Time],
datepart(hh, dbo. Nagytáblás. [Dátum időpontja]) mint [Dátumidő óra],
datepart(mi, dbo. Nagytáblás. [Dátum időpontja]) mint [Dátumidő perc],
datepart(ss, dbo. Nagytáblás. [Dátum időpontja]) mint [Date Time Seconds],
datepart(ms, dbo. Nagytáblás. [Dátum időpontja]) as [Date Time Ezredmásodperc]"
Használjon annyi oszlopot, amennyit csak kell, hogy az egyes részeket külön oszlopokban tárolja.
-
Ha órákra és percekre van szüksége, és egyszerre szeretné őket egy oszlopként használni, használhatja a szintaxist:
Timefromparts(datepart(hh, dbo. Nagytáblás. [Dátumidő]), datepart(mm, dbo. Nagytáblás. [Dátum időpontja])) as [Date Time HourMinute]
-
Ha két datetime oszlopa van, például a [Kezdési idő] és a [Befejezési idő], és valójában az időeltérésre van szüksége másodpercben az [Időtartam] nevű oszlopként, távolítsa el mindkét oszlopot a listából, és adja hozzá a következőt:
"datediff(ss,[Kezdő dátum],[Záró dátum]) mint [Időtartam]"
Ha az ms kulcsszót használja az ss helyett, ezredmásodpercben megkapja az időtartamot
SZÁMÍTOTT DAX-mértékek használata oszlopok helyett
Ha korábban már használta a DAX-kifejezésnyelvet, akkor már tudhatja, hogy a számított oszlopok a modell egy másik oszlopa alapján új oszlopok származtatására szolgálnak, míg a számított mértékek a modellben egyszer vannak meghatározva, de csak akkor lesznek kiértékelve, ha kimutatásban vagy más jelentésben használják.
Az egyik memóriatakarékos módszer a normál vagy számított oszlopok lecserélése számított mértékekkel. A klasszikus példa az Egységár, a Mennyiség és az Összeg. Ha mindháromkal rendelkezik, helyet takaríthat meg, ha csak kettőt tart fenn, és a harmadikat a DAX használatával számítja ki.
Melyik 2 oszlopot kell megtartania?
A fenti példában tartsa meg a Mennyiség és az Egységár elemet. Ez a kettő kevesebb értékkel rendelkezik, mint az Összeg. Az Összeg kiszámításához adjon hozzá egy számított mértéket, például:
"TotalSales:=sumx('Sales Table','Sales Table'[Unit Price]*'Sales Table'[Quantity])"
A számított oszlopok olyanok, mint a normál oszlopok, amelyek mind helyet foglalnak el a modellben. Ezzel szemben a számított mértékeket menet közben számítják ki, és nem foglalnak helyet.
Befejezés
Ebben a cikkben több olyan megközelítésről is szó esett, amelyek segíthetnek egy memóriahatékonyabb modell létrehozásában. Az adatmodell fájlméret- és memóriaigényének csökkentésének módja az oszlopok és sorok teljes számának, valamint az egyes oszlopokban megjelenő egyedi értékek számának csökkentése. Az alábbiakban bemutatunk néhány technikát:
-
Az oszlopok eltávolítása természetesen a legjobb módszer a helytakarékosságra. Döntse el, hogy mely oszlopokra van igazán szüksége.
-
Néha eltávolíthat egy oszlopot, és lecserélheti egy számított mértékre a táblában.
-
Előfordulhat, hogy nincs szüksége a tábla összes sorára. A Táblázat importálása varázslóban szűrheti a sorokat.
-
Általánosságban elmondható, hogy egy oszlop több különálló részre bontása jó módszer az oszlopok egyedi értékeinek számának csökkentésére. Mindegyik rész kis számú egyedi értékkel fog rendelkezni, és az egyesített összeg kisebb lesz, mint az eredeti egyesített oszlop.
-
Sok esetben a jelentésekben szeletelőként használandó különálló részekre is szükség van. Szükség esetén létrehozhat hierarchiákat olyan részekből, mint az Óra, a Perc és a Másodperc.
-
Az oszlopok sokszor több információt tartalmaznak, mint amennyi szükséges. Tegyük fel például, hogy egy oszlop decimális értékeket tárol, de formázást alkalmazott az összes tizedesjegy elrejtésére. A kerekítés nagyon hatékony lehet a numerikus oszlopok méretének csökkentésében.
Most, hogy mindent megtett a munkafüzet méretének csökkentése érdekében, fontolja meg a Munkafüzetméret-optimalizáló futtatását is. Elemzi az Excel-munkafüzetet, és ha lehetséges, tovább tömöríti. Töltse le a Munkafüzetméret-optimalizálót.
Kapcsolódó hivatkozások
Az adatmodell specifikációja és korlátozásai
Power Pivot: Hatékony adatelemzés és adatmodellezés az Excelben









