
표본 집단의 표준 편차를 구합니다. 표준 편차를 통해 값이 평균 값에서 벗어나 있는 정도를 알 수 있습니다. TRUE 및 FALSE와 같은 텍스트 및 논리 값이 계산에 포함됩니다.
구문
STDEVA(value1,value2,...)
Value1,value2,... 는 모집단의 샘플에 해당하는 1~30개 값입니다.
주의
- STDEVA 함수는 인수를 모집단의 표본으로 간주합니다. 데이터가 모집단 전체를 나타내는 경우에는 STDEVPA 함수를 사용하여 표준 편차를 계산해야 합니다.
- TRUE가 포함된 인수는 1로 계산되고 텍스트나 FALSE가 포함된 인수는 0으로 계산됩니다. 계산에 텍스트 또는 논리 값이 포함되지 않아야 하는 경우 STDEV 스프레드시트 함수를 대신 사용합니다.
- 표준 편차는 "비편차" 또는 "n-1" 메서드를 사용하여 계산됩니다.
- STDEVA 함수를 구하는 식은 다음과 같습니다.
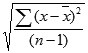
예제
프로덕션 실행 중에 동일한 컴퓨터에서 스탬프된 10가지 도구가 무작위 샘플로 수집되고 호환성이 손상되는 강도로 측정되었다고 가정합니다.
| St1 | St2 | St3 | St4 | St5 | St6 | St7 | St8 | St9 | St10 | 수식 | 설명(결과) |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 1345 | 1301 | 1368 | 1322 | 1310 | 1370 | 1318 | 1350 | 1303 | 1299 | =STDEVA([St1], [St2], [St3], [St4], [St5], [St6], [St7], [St8], [St9], [St10]) | 모든 공구의 분쇄 강도에 대한 표준 편차를 반환합니다(27.46391572). |