
정규 분포를 사용하여 모집단 평균의 신뢰 구간을 반환합니다.
설명
신뢰 간격은 값의 범위입니다. 샘플 평균 x는 이 범위의 중심에 있고 범위는 x ± CONFIDENCE.NORM입니다. 예를 들어 x가 메일을 통해 주문된 제품의 배달 시간 샘플 평균인 경우 x는 신뢰도를 ±. NORM은 모집단의 범위입니다. 임의의 모집단 평균, μ0의 경우, 이 범위에서 표본을 얻을 확률은 x보다 μ0 이상에서 더 크며, 모집단 평균인 μ0의 경우 이 범위가 아니라 x보다 μ0 이상의 표본 평균을 얻을 확률이 알파보다 작습니다. 즉, x, standard_dev 및 크기를 사용하여 모집단이 μ0이라는 가설의 유의 수준 알파에서 두 꼬리 테스트를 구성한다고 가정합니다. 그런 다음 μ0이 신뢰 구간에 있으면 해당 가설을 거부하지 않으며 μ0이 신뢰 구간에 없는 경우 해당 가설을 거부합니다. 신뢰 구간은 다음 패키지가 신뢰 구간에 있는 배달 시간이 소요될 확률 1 - 알파가 있음을 유추할 수 없습니다.
구문
CONFIDENCE.NORM(alpha,standard_dev,size)
CONFIDENCE.NORM 함수 구문에는 다음과 같은 인수가 사용됩니다.
-
alpha 필수 요소입니다. 신뢰도 수준을 계산하는 데 사용되는 중요도 수준입니다. 신뢰 수준이 100*(1 - alpha)%와 같거나, 즉 알파가 0.05이면 신뢰 수준이 95%를 나타냅니다.
-
standard_dev 필수 요소입니다. 데이터 범위에 대한 모집단의 표준 편차로서 그 값을 알고 있다고 가정합니다.
-
크기 필수 요소입니다. 표본 크기입니다.
주의
-
숫자가 아닌 인수가 있으면 CONFIDENCE.NORM에서는 #VALUE! 오류 값이 반환됩니다.
-
alpha ≤ 0 또는 alpha ≥ 1이면 CONFIDENCE.NORM에서는 #NUM! 오류 값이 반환됩니다.
-
standard_dev ≤ 0이면 CONFIDENCE.NORM에서는 #NUM! 오류 값이 반환됩니다.
-
size가 정수가 아니면 소수점 이하는 무시됩니다.
-
size < 1이면 CONFIDENCE.NORM에서는 #NUM! 오류 값이 반환됩니다.
-
alpha가 0.05라고 가정하면 표준 정규 곡선에서 (1 - alpha), 즉 95%에 해당하는 구간의 면적을 계산해야 합니다. 이 값은 ± 1.96입니다. 따라서 신뢰 구간은 다음과 같습니다.
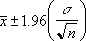
예제
다음 표의 예제 데이터를 복사하여 새 Excel 워크시트의 A1 셀에 붙여 넣습니다. 수식의 결과를 표시하려면 수식을 선택하고 F2 키를 누른 다음 Enter 키를 누릅니다. 필요한 경우 열 너비를 조정하면 데이터를 모두 표시할 수 있습니다.
|
데이터 |
설명 |
|
|
0.05 |
유의 수준입니다. |
|
|
2.5 |
모집단의 표준 편차입니다. |
|
|
50 |
표본 크기입니다. |
|
|
수식 |
설명 |
결과 |
|
=CONFIDENCE.NORM(A2,A3,A4) |
모집단 평균의 신뢰 구간입니다. 다시 말해 통근 시간의 모집단 평균이 30 ± 0.692952분, 즉 29.3분에서 30.7분 사이일 때의 신뢰 구간입니다. |
0.692952 |









