
I Excel 2013 eller nyere kan du opprette datamodeller som inneholder millioner av rader, og deretter utføre kraftig dataanalyse mot disse modellene. Datamodeller kan opprettes med eller uten tillegget Power Pivot for å støtte et hvilket som helst antall pivottabeller, diagrammer og Power View visualiseringer i samme arbeidsbok.
Obs!: Denne artikkelen beskriver datamodeller i Excel 2013. De samme datamodellene og Power Pivot-funksjonene som ble introdusert i Excel 2013, gjelder imidlertid også for Excel 2016. Det er i praksis liten forskjell mellom disse versjonene av Excel.
Selv om du enkelt kan bygge store datamodeller i Excel, er det flere grunner til ikke å gjøre det. For det første er store modeller som inneholder mange tabeller og kolonner, overkill for de fleste analyser, og utgjør en tungvint feltliste. For det andre bruker store modeller opp verdifullt minne, noe som påvirker andre programmer og rapporter som deler de samme systemressursene. I Microsoft 365 til slutt begrenser SharePoint Online og Excel Web App størrelsen på en Excel fil til 10 MB. For arbeidsbokdatamodeller som inneholder millioner av rader, kommer du raskt til 10 MB-grensen. Se Datamodellspesifikasjoner og -grenser.
I denne artikkelen lærer du hvordan du bygger en tett konstruert modell som er enklere å arbeide med og bruker mindre minne. Å ta deg tid til å lære anbefalte fremgangsmåter i effektiv modellutforming vil lønne seg nedover veien for alle modeller du oppretter og bruker, enten du viser den i Excel 2013, Microsoft 365 SharePoint Online, på en Office Online-server eller i SharePoint 2013.
Vurder også å kjøre optimaliseringen for arbeidsbokstørrelse. Den analyserer Excel-arbeidsboken og komprimerer den om mulig ytterligere. Last ned optimaliseringen for arbeidsbokstørrelse.
I denne artikkelen
Komprimeringsforhold og analysemotoren i minnet
Datamodeller Excel bruke analysemotoren i minnet til å lagre data i minnet. Motoren implementerer kraftige komprimeringsteknikker for å redusere lagringskravene og redusere et resultatsett til det er en brøkdel av den opprinnelige størrelsen.
I gjennomsnitt kan du forvente at en datamodell er 7 til 10 ganger mindre enn de samme dataene på opprinnelsespunktet. Hvis du for eksempel importerer 7 MB data fra en SQL Server-database, kan datamodellen i Excel være 1 MB eller mindre. Graden av komprimering som faktisk oppnås, avhenger hovedsakelig av antall unike verdier i hver kolonne. Jo flere unike verdier, jo mer minne kreves for å lagre dem.
Hvorfor snakker vi om komprimering og unike verdier? Siden det å bygge en effektiv modell som minimerer minnebruken, handler alt om komprimeringsmaksimering, og den enkleste måten å gjøre dette på, er å bli kvitt kolonner du egentlig ikke trenger, spesielt hvis disse kolonnene inneholder et stort antall unike verdier.
Obs!: Forskjellene i lagringskravene for individuelle kolonner kan være store. I noen tilfeller er det bedre å ha flere kolonner med et lavt antall unike verdier i stedet for én kolonne med et høyt antall unike verdier. Delen om Datetime-optimaliseringer dekker denne teknikken i detalj.
Ingenting slår en ikke-eksisterende kolonne for lite minnebruk
Den mest minneeffektive kolonnen er den du aldri importerte i utgangspunktet. Hvis du vil bygge en effektiv modell, kan du se på hver kolonne og spørre deg selv om den bidrar til analysen du vil utføre. Hvis den ikke er det, eller du ikke er sikker, kan du la den være ute. Du kan alltid legge til nye kolonner senere hvis du trenger dem.
To eksempler på kolonner som alltid bør utelates
Det første eksemplet er relatert til data som kommer fra et datalager. I et datalager er det vanlig å finne artefakter av ETL-prosesser som laster inn og oppdaterer data på lageret. Kolonner som «opprett dato», «oppdateringsdato» og «ETL-kjøring» opprettes når dataene lastes inn. Ingen av disse kolonnene er nødvendige i modellen og bør ikke velges når du importerer data.
Det andre eksemplet innebærer å utelate primærnøkkelkolonnen når du importerer en faktatabell.
Mange tabeller, inkludert faktatabeller, har primærnøkler. For de fleste tabeller, for eksempel de som inneholder kunde-, ansatt- eller salgsdata, vil du ha tabellens primærnøkkel, slik at du kan bruke den til å opprette relasjoner i modellen.
Faktatabeller er forskjellige. I en faktatabell brukes primærnøkkelen til å identifisere hver rad unikt. Selv om det er nødvendig for normaliseringsformål, er det mindre nyttig i en datamodell der du bare vil ha de kolonnene som brukes til analyse eller til å etablere tabellrelasjoner. Når du importerer fra en faktatabell, må du derfor ikke inkludere primærnøkkelen. Primærnøkler i en faktatabell bruker enorme mengder plass i modellen, men gir likevel ingen fordeler, da de ikke kan brukes til å opprette relasjoner.
Obs!: I datalagre og flerdimensjonale databaser kalles store tabeller som for det meste består av numeriske data, ofte kalt faktatabeller. Faktatabeller omfatter vanligvis forretningsytelse eller transaksjonsdata, for eksempel salgs- og kostnadsdatapunkter som aggregeres og justeres etter organisasjonsenheter, produkter, markedssegmenter, geografiske områder og så videre. Alle kolonnene i en faktatabell som inneholder forretningsdata, eller som kan brukes til å kryssreferansedata som er lagret i andre tabeller, bør inkluderes i modellen for å støtte dataanalyse. Kolonnen du vil utelate, er primærnøkkelkolonnen i faktatabellen, som består av unike verdier som bare finnes i faktatabellen og ingen andre steder. Fordi faktatabeller er så store, er noen av de største forsterkningene i modelleffektivitet avledet fra å ekskludere rader eller kolonner fra faktatabeller.
Slik utelater du unødvendige kolonner
Effektive modeller inneholder bare de kolonnene du faktisk trenger i arbeidsboken. Hvis du vil kontrollere hvilke kolonner som er inkludert i modellen, må du bruke veiviseren for tabellimport i Power Pivot-tillegget til å importere dataene i stedet for dialogboksen Importer data i Excel.
Når du starter veiviseren for tabellimport, velger du hvilke tabeller du vil importere.
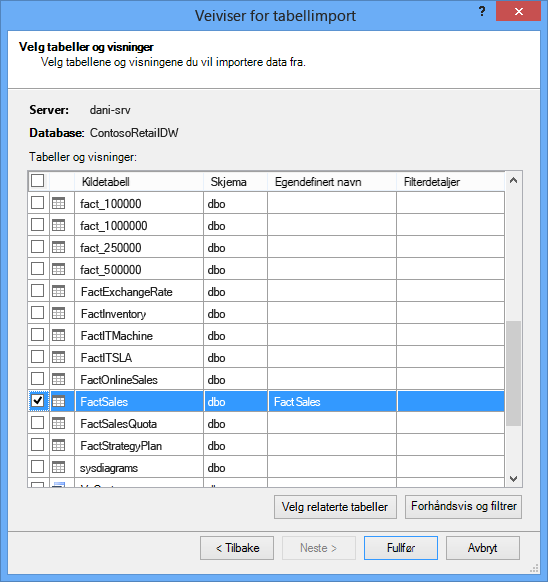
For hver tabell kan du klikke forhåndsvisningsknappen & Filter og velge de delene av tabellen du virkelig trenger. Vi anbefaler at du først fjerner merket for alle kolonnene, og deretter fortsetter for å kontrollere kolonnene du vil bruke, etter å ha vurdert om de er nødvendige for analysen.
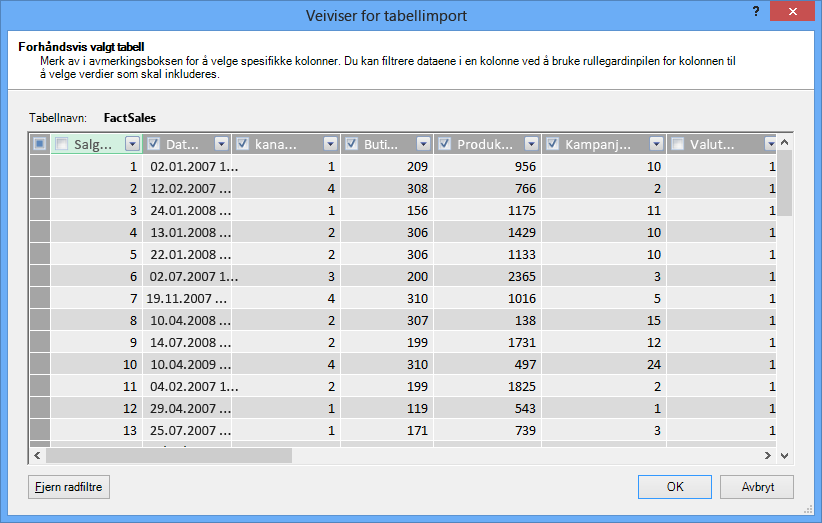
Hva med å filtrere bare de nødvendige radene?
Mange tabeller i bedriftsdatabaser og datalagre inneholder historiske data akkumulert over lange tidsperioder. I tillegg kan det hende at tabellene du er interessert i, inneholder informasjon for områder av virksomheten som ikke er nødvendige for den bestemte analysen.
Ved hjelp av veiviseren for tabellimport kan du filtrere ut historiske eller ikke-relaterte data, og dermed spare mye plass i modellen. I følgende bilde brukes et datofilter til å hente bare rader som inneholder data for gjeldende år, unntatt historiske data som ikke vil være nødvendig.
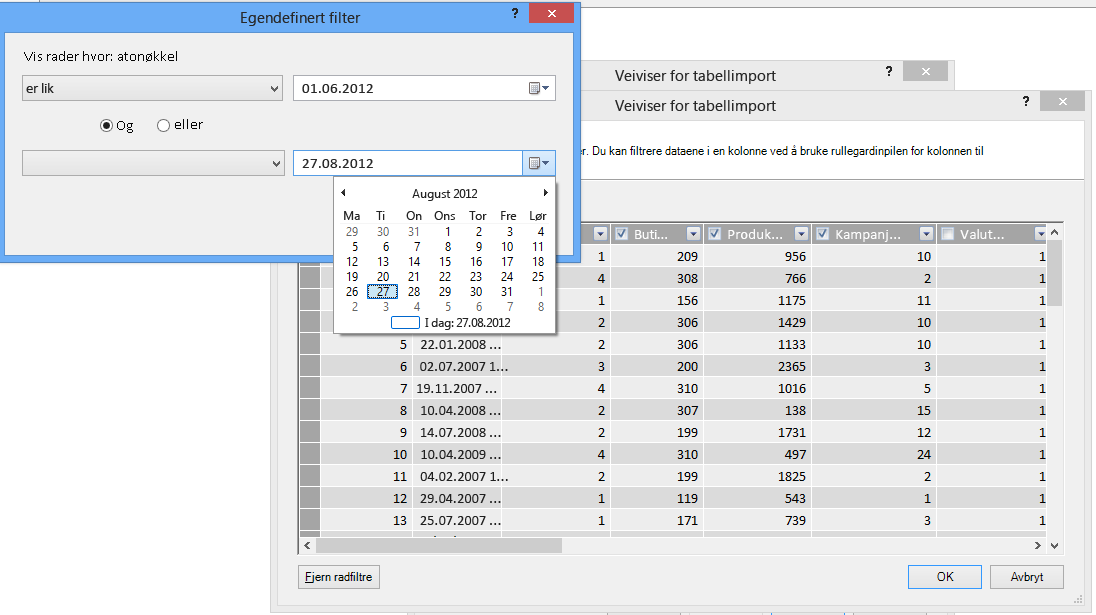
Hva om vi trenger kolonnen; kan vi fortsatt redusere plasskostnadene?
Det finnes noen flere teknikker du kan bruke for å gjøre en kolonne til en bedre komprimeringskandidat. Husk at den eneste egenskapen til kolonnen som påvirker komprimering, er antallet unike verdier. I denne delen lærer du hvordan noen kolonner kan endres for å redusere antall unike verdier.
Endre Datetime-kolonner
I mange tilfeller tar Datetime-kolonner mye plass. Heldigvis finnes det flere måter å redusere lagringskravene for denne datatypen på. Teknikkene varierer avhengig av hvordan du bruker kolonnen, og hvor komfortabelt det er å bygge SQL spørringer.
Datetime-kolonner inkluderer en datodel og et klokkeslett. Når du spør deg selv om du trenger en kolonne, stiller du det samme spørsmålet flere ganger for en Datetime-kolonne:
-
Trenger jeg tidsdelen?
-
Trenger jeg tidsdelen på timenivået? , minutter? , Sekunder? , millisekunder?
-
Har jeg flere Datetime-kolonner fordi jeg vil beregne forskjellen mellom dem, eller bare for å aggregere dataene etter år, måned, kvartal og så videre.
Hvordan du svarer på hvert av disse spørsmålene, bestemmer alternativene for å håndtere Datetime-kolonnen.
Alle disse løsningene krever endring av en SQL spørring. Hvis du vil gjøre det enklere å endre spørringen, bør du filtrere ut minst én kolonne i hver tabell. Ved å filtrere ut en kolonne endrer du spørringsbyggingen fra et forkortet format (SELECT *) til en SELECT-setning som inneholder fullstendige kolonnenavn, som er langt enklere å endre.
La oss ta en titt på spørringene som er opprettet for deg. I dialogboksen Egenskaper for tabell kan du bytte til redigeringsprogrammet for spørring og se gjeldende spørring SQL for hver tabell.
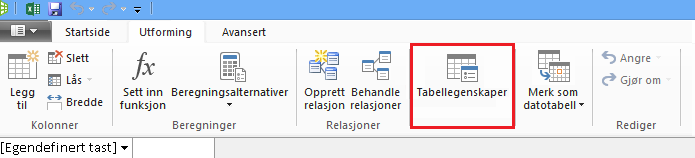
Velg Redigeringsprogram for spørring fra Tabellegenskaper.
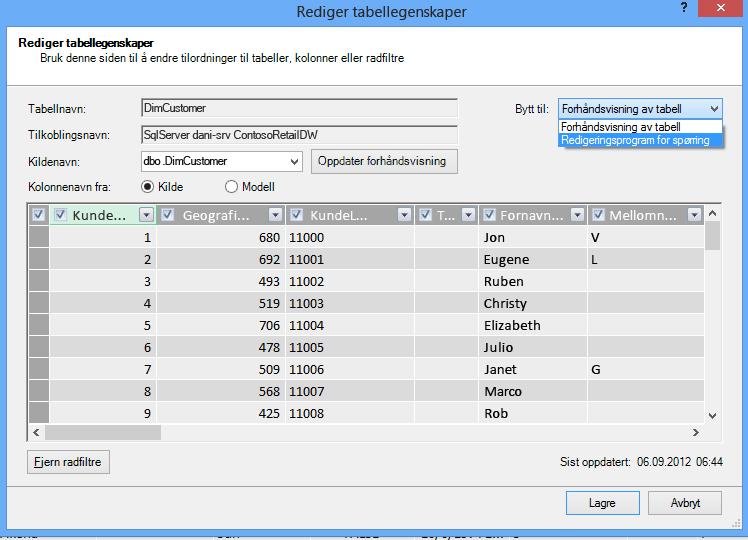
Redigeringsprogrammet for spørring viser SQL som brukes til å fylle ut tabellen. Hvis du filtrerte ut en kolonne under importen, inneholder spørringen fullstendige kolonnenavn:
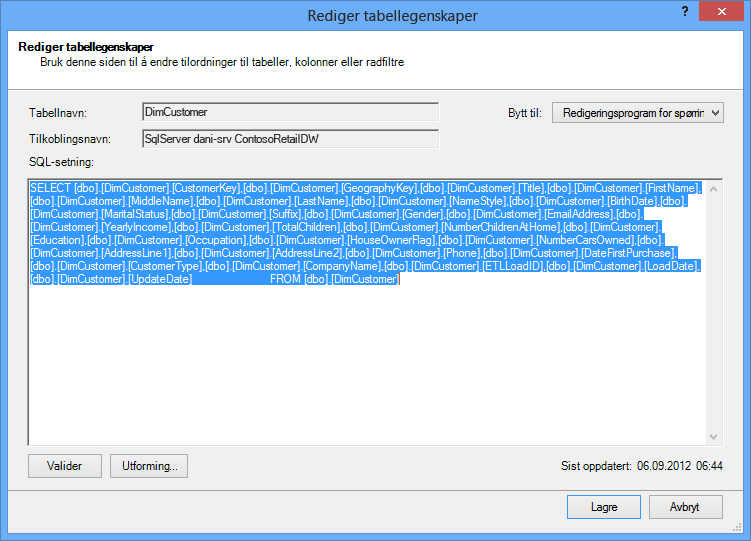
|
Hvis du derimot importerte en tabell i sin helhet, uten å fjerne merket for en kolonne eller bruke et filter, vil du se spørringen som «Velg * fra », som vil være vanskeligere å endre:
|
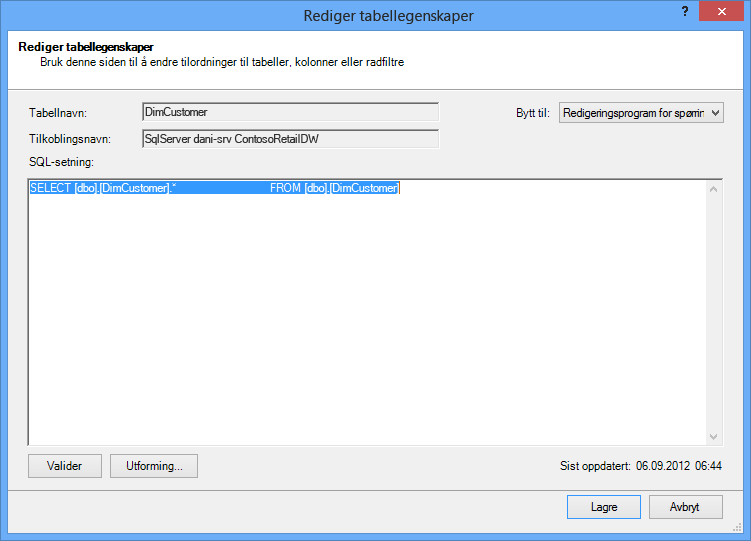
Endre SQL spørringen
Nå som du vet hvordan du finner spørringen, kan du endre den for å redusere størrelsen på modellen ytterligere.
-
Hvis du ikke trenger desimaler for kolonner som inneholder valuta- eller desimaldata, kan du bruke denne syntaksen til å bli kvitt desimalene:
"SELECT ROUND([Decimal_column_name];0)... .”
Hvis du trenger cent, men ikke brøker av cent, erstatter du 0 med 2. Hvis du bruker negative tall, kan du runde av til enheter, tiere, hundrevis og så videre.
-
Hvis du har en Datetime-kolonne kalt dbo. Bigtable. [Dato/klokkeslett] og du ikke trenger Tid-delen, bruker du syntaksen til å bli kvitt klokkeslettet:
"SELECT CAST (dbo. Bigtable. [Dato/klokkeslett] som dato) AS [Dato/klokkeslett]) "
-
Hvis du har en Datetime-kolonne kalt dbo. Bigtable. [Dato/klokkeslett] og du trenger både dato- og klokkeslettdelene, bruker du flere kolonner i SQL spørringen i stedet for den enkle Datetime-kolonnen:
"SELECT CAST (dbo. Bigtable. [Dato/klokkeslett] som dato ) AS [Dato/klokkeslett],
datepart(tt, dbo. Bigtable. [Dato/klokkeslett]) som [Dato/klokkeslett],
datepart(mi, dbo. Bigtable. [Dato/klokkeslett]) som [Dato/klokkeslett minutter],
datepart(ers, dbo. Bigtable. [Dato/klokkeslett]) som [Dato/klokkeslett sekunder],
datepart(ms, dbo. Bigtable. [Dato/klokkeslett]) som [Millisekunder for dato/klokkeslett]"
Bruk så mange kolonner du trenger for å lagre hver del i separate kolonner.
-
Hvis du trenger timer og minutter, og du foretrekker dem sammen som én tidskolonne, kan du bruke syntaksen:
Timefromparts(datepart(tt, dbo. Bigtable. [Dato/klokkeslett]), datepart(mm, dbo. Bigtable. [Dato/klokkeslett])) as [Date Time HourMinute]
-
Hvis du har to datetime-kolonner, for eksempel [Starttid] og [Slutid], og det du virkelig trenger, er tidsforskjellen mellom dem i sekunder som en kolonne kalt [Varighet], fjerner du begge kolonnene fra listen og legger til:
"datediff(ss,[Startdato],[Sluttdato]) som [Varighet]"
Hvis du bruker nøkkelordet ms i stedet for ss, får du varigheten i millisekunder
Bruke DAX-beregnede mål i stedet for kolonner
Hvis du har arbeidet med DAX-uttrykksspråket før, vet du kanskje allerede at beregnede kolonner brukes til å hente nye kolonner basert på en annen kolonne i modellen, mens beregnede mål defineres én gang i modellen, men evalueres bare når de brukes i en pivottabell eller en annen rapport.
Én minnesparingsteknikk er å erstatte vanlige eller beregnede kolonner med beregnede mål. Det klassiske eksemplet er Enhetspris, Antall og Total. Hvis du har alle tre, kan du spare plass ved å beholde bare to og beregne den tredje ved hjelp av DAX.
Hvilke to kolonner bør du beholde?
Behold Antall og Enhetspris i eksemplet ovenfor. Disse to har færre verdier enn totalsummen. Hvis du vil beregne totalsum, legger du til et beregnet mål som:
"TotalSalg:=sumx('Salgstabell','Salgstabell'[Enhetspris]*'Salgstabell'[Antall])"
Beregnede kolonner er som vanlige kolonner i at begge tar opp plass i modellen. Beregnede mål beregnes derimot på et øyeblikk og tar ikke plass.
Konklusjon
I denne artikkelen har vi snakket om flere fremgangsmåter som kan hjelpe deg med å bygge en mer minneeffektiv modell. Måten du kan redusere filstørrelsen og minnekravene for en datamodell på, er å redusere det totale antallet kolonner og rader, og antall unike verdier som vises i hver kolonne. Her er noen teknikker vi dekket:
-
Å fjerne kolonner er selvfølgelig den beste måten å spare plass på. Bestem hvilke kolonner du virkelig trenger.
-
Noen ganger kan du fjerne en kolonne og erstatte den med et beregnet mål i tabellen.
-
Du trenger kanskje ikke alle radene i en tabell. Du kan filtrere ut rader i veiviseren for tabellimport.
-
Generelt sett er det en god måte å redusere antall unike verdier i en kolonne på for å dele opp én enkelt kolonne i flere forskjellige deler. Hver av delene har et lite antall unike verdier, og den kombinerte totalsummen vil være mindre enn den opprinnelige enhetlige kolonnen.
-
I mange tilfeller trenger du også de forskjellige delene som skal brukes som slicere i rapportene. Når det er aktuelt, kan du opprette hierarkier fra deler som Timer, Minutter og Sekunder.
-
Mange ganger inneholder kolonner mer informasjon enn du trenger dem også. Anta for eksempel at en kolonne lagrer desimaler, men at du har brukt formatering til å skjule alle desimalene. Avrunding kan være svært effektivt når det gjelder å redusere størrelsen på en numerisk kolonne.
Nå som du har gjort det du kan for å redusere størrelsen på arbeidsboken, bør du vurdere også å kjøre optimaliseringen for arbeidsbokstørrelse. Den analyserer Excel-arbeidsboken og komprimerer den om mulig ytterligere. Last ned optimaliseringen for arbeidsbokstørrelse.
Beslektede koblinger
Datamodell – spesifikasjoner og grenser









