
Acest articol descrie sintaxa de formulă și utilizarea funcției LINEST în Microsoft Excel.
Descriere
Funcția LINEST calculează statistica pentru o linie utilizând metoda celor mai mici pătrate pentru a calcula o linie dreaptă care descrie cel mai bine datele și returnează o matrice care descrie acea linie. De asemenea, aveți posibilitatea să combinați LINEST cu alte funcții, pentru a calcula statisticile pentru alte tipuri de modele care sunt liniare în parametri necunoscuți, inclusiv seriile polinomiale, logaritmice, exponențiale și de puteri. Deoarece această funcție returnează o matrice de valori, ea trebuie introdusă ca o formulă de matrice. Acest articol conține instrucțiuni împreună cu exemple.
Ecuația pentru linie este:
y = mx + b
- sau -
y = m1x1 + m2x2 + ... + b
dacă există mai multe zone de valori x, unde valorile dependente y sunt o funcție de valorile x independente. Valorile m sunt coeficienți corespunzători fiecărei valori x, iar b este o valoare constantă. De reținut că y, x și m pot fi vectori. Matricea pe care o întoarce funcția LINEST este {mn;mn-1;...;m1;b}. LINEST mai poate întoarce și statistici de regresie adiționale.
Sintaxă
LINEST(valori_y_cunoscute, [valori_x_cunoscute], [const], [statistici])
Sintaxa funcției LINEST are următoarele argumente:
Sintaxă
known_y Obligatoriu. Este este setul de valori y pe care le cunoașteți deja din relația y = mx + b.
- Dacă zona de known_y este într-o singură coloană, fiecare coloană de known_x este interpretată ca o variabilă separată.
- Dacă zona de known_y este conținută într-un singur rând, fiecare rând de known_x este interpretat ca o variabilă separată.
known_x Opțional. Este un set de valori x pe care este posibil să le cunoașteți deja din relația y = mx + b.
- Matricea de known_x poate include unul sau mai multe seturi de variabile. Dacă este utilizată o singură variabilă, known_y și known_x pot fi zone de orice formă, de vreme ce au dimensiuni egale. Dacă sunt utilizate mai multe variabile, known_y trebuie să fie un vector (adică o zonă cu înălțimea de un rând sau cu lățimea de o coloană).
- Dacă known_x este omis, se consideră a fi matricea {1;2;3,...} care este de aceeași mărime cu known_y.
const Opțional. Este o valoare logică ce specifică dacă constanta b va fi forțată la valoarea 0.
- Dacă const este TRUE sau omisă, b este calculat normal.
- Dacă const este FALSE, b este setat la valoarea 0 și valorile m sunt ajustate pentru a respecta ecuația y = mx.
Statistici Opțional. Este o valoare logică ce specifică dacă să întoarcă statistica de regresie adițională.
- Dacă argumentul statistică este TRUE, LINEST întoarce statistica de regresie adițională; Drept urmare, matricea returnată este {mn;mn-1,...,m1;b; sen, sen-1,...,se1, seb; r2, sey; F,df; ssreg,ssresid}.
- Dacă statistică este FALSE sau omis, LINEST întoarce numai coeficienții m și constanta b.
Statisticile de regresie suplimentare sunt după cum urmează:
| Statistica | Descriere |
|---|---|
| se1,se2,...,sen | Valorile de eroare standard pentru coeficienții m1,m2,...,mn. |
| seb | Valoarea de eroare standard pentru constanta b (seb = #N/A când const este FALSE). |
| r2 | Coeficientul de determinare. Compară valorile y estimate și actuale și este cuprins în intervalul de la 0 la 1. Dacă este 1, există o corelație perfectă în eșantion (nu există nicio diferență între valorile y estimate și cele actuale). La cealaltă extremă, în cazul în care coeficientul de determinare este 0, ecuația regresiei nu ajută la estimarea unei valori y. Pentru informații despre cum se calculează2 , consultați "Observații" mai departe la acest subiect. |
| sey | Eroarea standard pentru y estimat. |
| V | Statistica F sau valoarea F observată. Utilizați statistica F pentru a determina dacă relația observată între variabilele dependente și independente are loc din întâmplare. |
| df | Gradele de libertate. Utilizați gradele de libertate pentru a găsi valorile critice F dintr-un tabel statistic. Comparați valorile găsite în tabel cu statistica F returnată de funcția LINEST pentru a determina nivelul de încredere pentru model. Pentru informații despre cum se calculează df, consultați „Observații” mai departe în acest capitol. Exemplul 4de mai jos ilustrează cum se utilizează F și df. |
| ssreg | Suma de regresie a pătratelor. |
| ssresid | Suma reziduală a pătratelor. Pentru informații despre cum se calculează ssreg și ssresid, consultați „Observații" din acest articol. |
Figura următoare arată ordinea în care sunt returnate statisticile de regresie adiționale.

Observații
Descrieți orice dreaptă cu ajutorul pantei și a intersecției cu axa y:
Panta (m):
Pentru a găsi panta unei linii, deseori scrisă ca m, luați două puncte de pe linie, (x1;y1) și (x2;y2); Panta este egală cu (y2 - y1)/(x2 - x1).
Intersecția cu axa Y (b):
Intersecția cu axa Y a unei linii, deseori scrisă ca b, este valoarea lui y în punctul în care linia intersectează axa Y.
Ecuația unei drepte este y = mx + b. Odată ce cunoașteți valorile pentru m și b, aveți posibilitatea să calculați orice punct al liniei înlocuind valorile x sau y în ecuație. La fel de bine se poate utiliza și funcția TREND.Când aveți o singură variabilă independentă x, puteți obține panta și intersecția cu axa y în mod direct, utilizând următoarele formule:
Panta:
=INDEX(LINEST(known_y;known_x);1)
Intersecția cu axa Y:
=INDEX(LINEST(known_y;known_x);2)Acuratețea liniei calculate de funcția LINEST depinde de gradul de împrăștiere din datele dvs. Cu cât sunt mai liniare datele, cu atât modelul liniar LINEST va fi mai neted. LINEST utilizează metoda celor mai mici pătrate pentru a determina cea mai bună aproximare a datelor. Când aveți o singură variabilă independentă x, calculele pentru panta m și intersecția b se bazează pe următoarele formule:
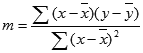
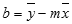
unde x și y sunt mediile pentru eșantioane; adică, x = AVERAGE(valorile cunoscute) și y = AVERAGE(known_y).Funcțiile de potrivire a liniilor și curbelor LINEST și LOGEST pot calcula cea mai bună linie dreaptă sau curbă exponențială care încadrează datele dvs. Cu toate acestea, trebuie să decideți care dintre cele două rezultate se potrivește cel mai bine cu datele dvs. Puteți calcula TREND(known_y,known_x) pentru o linie dreaptă sau GROWTH(known_y, known_x) pentru o curbă exponențială. Aceste funcții, fără argumentul new_x , returnează o matrice de valori y estimate de-a lungul acelei linii sau curbe, la punctele de date efective. Apoi puteți compara valorile estimate cu valorile reale. Se recomandă să le reprezentați grafic pe amândouă, pentru o comparație vizuală.
În analizele de regresie, Excel calculează pentru fiecare punct pătratul diferenței dintre valoarea y estimată în punctul respectiv și valoarea y actuală. Suma pătratelor acestor diferențe este denumită sumă reziduală de pătrate, ssresid. Excel calculează apoi suma totală pătratelor, sstotal. Când argumentul const = TRUE sau este omis, suma totală a pătratelor este suma pătratelor diferențelor dintre valorile y efective și media valorilor y. Când argumentul const = FALSE, suma totală a pătratelor este suma pătratelor valorilor y efective (fără scăderea mediei valorilor y din fiecare valoare y). Apoi, suma de regresie a pătratelor, ssreg, se poate afla din: ssreg = sstotal - ssresid. Cu cât este mai mică suma reziduală a pătratelor în comparație cu suma totală a pătratelor, cu atât este mai mare valoarea coeficientului de determinare, r2, care este un indicator pentru cât de bine este explicată relația dintre variabile de către ecuația rezultată din analiza de regresie. Valoarea lui r2 este egală cu ssreg/sstotal.
În unele cazuri, una sau mai multe dintre coloanele X (presupunând că Y și X sunt în coloane) pot să nu aibă nicio valoare predictivă suplimentară în prezența celorlalte coloane X. Cu alte cuvinte, eliminarea uneia sau mai multor coloane X poate avea ca rezultat valori Y estimate care sunt la fel de precise. În acest caz, aceste coloane X redundante trebuie omise din modelul de regresie. Acest fenomen este denumit "coliniaritate", deoarece orice coloană X redundantă poate fi exprimată ca o sumă de multipli ai coloanelor X neredundante. Funcția LINEST verifică coliniarul și elimină toate coloanele X redundante din modelul de regresie atunci când le identifică. Coloanele X eliminate pot fi recunoscute în rezultatul LINEST ca având 0 coeficienți în plus față de 0 valori se. Dacă una sau mai multe coloane sunt eliminate ca redundante, df este afectat, deoarece df depinde de numărul de coloane X utilizate efectiv în scopuri predictive. Pentru detalii despre calculul lui df, vedeți exemplul 4. Dacă df se modifică deoarece coloanele X redundante sunt eliminate, sunt afectate și valorile din sey și F. Coliniaritatea ar trebui să fie relativ rară în practică. Totuși, un caz în care este mai probabil să apară este atunci când unele coloane X conțin doar valorile 0 și 1 ca indicatori dacă un subiect dintr-un experiment este sau nu membru al unui anumit grup. Dacă const = TRUE sau este omisă, funcția LINEST inserează efectiv o coloană X suplimentară cu toate valorile 1 pentru a modela intersecția. Dacă aveți o coloană cu un 1 pentru fiecare subiect dacă este masculin sau 0 dacă nu și aveți o coloană cu 1 pentru fiecare subiect dacă este feminin sau 0 dacă nu, această din urmă coloană este redundantă, deoarece intrările din ea pot fi obținute scăzând intrarea din coloana "indicator masculin" din intrarea din coloana suplimentară a tuturor valorilor 1 adăugate de funcția LINEST .
Valoarea df se calculează ca mai jos atunci când nicio coloană X nu este eliminată din model datorită coliniarității: dacă există k coloane de known_x și const = TRUE sau este omis, atunci df = n – k – 1. Dacă const = FALSE, df = n - k. În ambele cazuri, fiecare coloană X eliminată datorită coliniarității mărește df cu 1.
Când introduceți o constantă matrice (cum ar fi known_x) ca argument, utilizați punct și virgulă (cum ar fi ) ca argument, utilizați punct și virgulă (;) pentru separarea rândurilor. Caracterele separatoare pot fi diferite, în funcție de setările regionale.
De reținut că valorile y estimate de ecuația de regresie pot să nu fie valide dacă ele se situează în afara intervalului de valori y pe care l-ați utilizat pentru a determina ecuația.
Algoritmul de bază utilizat în funcția LINEST diferă de algoritmul de bază din funcțiile SLOPE și INTERCEPT. Diferențele dintre acești algoritmi pot conduce la rezultate diferite când datele sunt nedeterminate și colineare. De exemplu, dacă punctele de date ale argumentului known_y sunt 0 și punctele de date ale argumentului known_x sunt 1:
- LINEST returnează valoarea 0. Algoritmul funcției LINEST este proiectat să returneze valorile rezonabile pentru datele colineare și, în acest caz, se poate găsi cel puțin un răspuns.
- SLOPE și INTERCEPT returnează un #DIV/0! . Algoritmii funcțiilor SLOPE și INTERCEPT sunt proiectați pentru a căuta un singur răspuns și numai unul, iar în acest caz pot fi mai multe răspunsuri.
În plus față de utilizarea LOGEST pentru a calcula statistici pentru alte tipuri de regresii, aveți posibilitatea să utilizați LINEST pentru a calcula alte tipuri de regresii, introducând funcții ale variabilelor x și y ca serii x și y pentru LINEST. De exemplu, următoarea formulă:
=LINEST(yvalori; xvalori^COLUMN($A:$C))
funcționează atunci când aveți o singură coloană de valori y și o singură coloană de valori x pentru a calcula aproximarea cubică (polinomială de ordinul trei) a formulei:
y = m1*x + m2*x^2 + m3*x^3 + b
Aveți posibilitatea să reglați această formulă pentru a calcula alte tipuri de regresii, însă în unele cazuri este necesară reglarea valorilor de ieșire și a altor statistici.Valoarea F-test returnată de funcția LINEST diferă de valoarea F-test returnată de funcția LINEST. LINEST returnează statistica F, în timp ce FTEST returnează probabilitatea.
Exemple
Exemplul 1 - panta și intersecția cu axa Y
Copiați datele din exemplele din următorul tabel și lipiți-le în celula A1 a noii foi de lucru Excel. Pentru ca formulele să afișeze rezultate, selectați-le, apăsați pe F2, apoi pe Enter. Dacă trebuie, puteți ajusta lățimea coloanei pentru a vedea toate datele.
| Y cunoscut | X cunoscut |
|---|---|
| 1 | 0 |
| 9 | 4 |
| 5 | 2 |
| 7 | 3 |
| Rezultat (pantă) | Rezultat (intersecția cu axa y) |
| 2 | 1 |
| Formulă (formulă matrice în celulele A7:B7) | |
| =LINEST(A2:A5;B2:B5;;FALSE) |
Exemplul 2 - Regresie liniară simplă
Copiați datele din exemplele din următorul tabel și lipiți-le în celula A1 a noii foi de lucru Excel. Pentru ca formulele să afișeze rezultate, selectați-le, apăsați pe F2, apoi pe Enter. Dacă trebuie, puteți ajusta lățimea coloanei pentru a vedea toate datele.
| Lună | Vânzări |
|---|---|
| 1 | 3.100 lei |
| 2 | 4.500 lei |
| 3 | 4.400 lei |
| 4 | 5.400 lei |
| 5 | 7.500 lei |
| 6 | 8.100 lei |
| Formulă | Rezultat |
| =SUM(LINEST(B1:B6; A1:A6)*{9,1}) | 11.000 lei |
| Calculează estimarea vânzărilor pentru luna a noua, pe baza vânzărilor din lunile de la 1 la 6. |
Exemplul 3 - Regresie liniară multiplă
Copiați datele din exemplele din următorul tabel și lipiți-le în celula A1 a noii foi de lucru Excel. Pentru ca formulele să afișeze rezultate, selectați-le, apăsați pe F2, apoi pe Enter. Dacă trebuie, puteți ajusta lățimea coloanei pentru a vedea toate datele.
| Suprafață (x1) | Birouri (x2) | Intrări (x3) | Vârsta (x4) | Valoare estimată (y) |
|---|---|---|---|---|
| 2310 | 2 | 2 | 20 | 142.000 lei |
| 2333 | 2 | 2 | 12 | 144.000 lei |
| 2356 | 3 | 1,5 | 33 | 151.000 lei |
| 2379 | 3 | 2 | 43 | 150.000 lei |
| 2402 | 2 | 3 | 53 | 139.000 lei |
| 2425 | 4 | 2 | 23 | 169.000 lei |
| 2448 | 2 | 1,5 | 99 | 126.000 lei |
| 2471 | 2 | 2 | 34 | 142.900 lei |
| 2494 | 3 | 3 | 23 | 163.000 lei |
| 2517 | 4 | 4 | 55 | 169.000 lei |
| 2540 | 2 | 3 | 22 | 149.000 lei |
| -234,2371645 | ||||
| 13,26801148 | ||||
| 0,996747993 | ||||
| 459,7536742 | ||||
| 1732393319 | ||||
| Formulă (formulă matrice dinamică introdusă în A19) | ||||
| =LINEST(E2:E12;A2:D12;TRUE;TRUE) |
Exemplul 4 - Utilizarea statisticilor F și r2
În exemplul anterior, coeficientul de determinare sau r2, este 0,99675 (vedeți celula A17 din răspunsul pentru LINEST), care indică o relație foarte strânsă între variabilele independente și prețul de vânzare. Aveți posibilitatea să utilizați statistica F pentru a determina dacă aceste rezultate, cu un coeficient r2 atât de mare, au apărut din întâmplare.
Presupuneți pentru moment că de fapt nu există nicio relație între variabile și că relația strânsă demonstrată de analiza statistică se bazează pe faptul că ați ales un eșantion norocos de 11 clădiri. Termenul „Alfa” este utilizat pentru probabilitatea de a trage concluzia eronată că ar exista o relație.
Valorile F și df din rezultatul funcției LINEST pot fi utilizate pentru a evalua probabilitatea apariției întâmplătoare a unei valori F mai mari. F poate fi comparată cu valorile critice din tabelele publicate de distribuție F sau funcția FDIST din Excel poate fi utilizată pentru a calcula probabilitatea ca o valoare F mai mare să apară din întâmplare. Repartiția F corespunzătoare are gradele de libertate v1 și v2. Dacă n este numărul reperelor de date și const = TRUE sau omis, atunci v1 = n – df – 1 și v2 = df. (Dacă const = FALSE, atunci v1 = n – df și v2 = df.) Funcția FDIST , cu sintaxa FDIST(F,v1,v2), va returna probabilitatea ca o valoare F mai mare să apară din întâmplare. În acest exemplu, df = 6 (celula B18) și F = 459,753674 (celula A18).
Presupunând o valoare Alfa de 0,05, v1 = 11 – 6 – 1 = 4 și v2 = 6, nivelul critic F este 4,53. Deoarece F = 459,753674 este mult mai mare decât 4,53, este extrem de puțin probabil ca o valoare F atât de mare să fi apărut din întâmplare. (Cu Alfa = 0,05, ipoteza că nu există nicio relație între known_y și known_x trebuie respinsă atunci când F depășește nivelul critic, 4,53.) Puteți utiliza funcția FDIST în Excel pentru a obține probabilitatea ca o valoare F atât de mare să apară din întâmplare. De exemplu, FDIST(459,753674, 4, 6) = 1,37E-7, o probabilitate extrem de mică. Aveți posibilitatea să concluzionați fie prin găsirea nivelului critic F dintr-un tabel, fie utilizând funcția FDIST , că ecuația regresiei este utilă pentru estimarea valorii stabilite pentru clădirile de birouri din acea zonă. Rețineți că este esențial să utilizați valorile corecte ale v1 și v2 care au fost calculate în paragraful precedent.
Exemplul 5 - Calculul statisticii t
Un alt test ipotetic va determina dacă fiecare coeficient al pantei este util la estimarea valorii unei clădiri de birouri de la Exemplul 3. De exemplu, pentru a testa importanța statistică a coeficientului de vârstă, împărțiți -234,24 (coeficientul pantei vârstei) la 13,268 (eroarea standard estimată pentru coeficienții de vârstă din celula A15). Mai jos este calculată valoarea observată t:
t = m4 ÷ se4 = -234.24 ÷ 13.268 = -17.7
Dacă valoarea absolută a lui t este suficient de mare, se poate concluziona că coeficientul pantei este util pentru estimarea valorii unei clădiri de birouri din Exemplul 3. Tabelul de mai jos arată valorile absolute ale celor 4 valori t observate.
Dacă consultați un tabel dintr-un manual de statistică, veți găsi că t critic, bi-alternativă, cu 6 grade de libertate și Alfa = 0,05 este 2,447. Această valoare critică poate fi de asemenea găsită utilizând funcția TINV din Excel. TINV(0.05;6) = 2,447. Deoarece valoarea absolută a lui t (17,7) este mai mare decât 2,447, vârsta reprezintă o variabilă importantă pentru estimarea valorii stabilite pentru o clădire de birouri. Fiecare dintre celelalte variabile independente poate fi testată pentru semnificația sa statistică în mod asemănător. În continuare se dau valorile t observate pentru fiecare variabilă independentă.
| Variabilă | valoarea t observată |
|---|---|
| Suprafața utilă | 5,1 |
| Număr de birouri | 31,3 |
| Număr de intrări | 4,8 |
| Vârsta | 17,7 |
Aceste variabile au toate valori absolute mai mari decât 2,447; în consecință, toate variabilele utilizate în ecuația de regresie sunt utile pentru estimarea valorii stabilite pentru clădirile de birouri din acea zonă.