
Når du har overført dine data fra Access til SQL Server, har du nu en klient/server-database, som kan være en lokal eller cloud-baseret Azure-hybridløsning. Uanset hvad du vælger, vil Access nu være præsentationslaget, og SQL Server vil være datalaget. Nu er det et godt tidspunkt at genoverveje din løsnings aspekter, især forespørgselsydeevne, sikkerhed og virksomhedskontinuitet, så du kan forbedre og skalere din databaseløsning.
Det kan være overvældende, hvis man som Access-bruger ser dokumentationen til SQL Server og Azure for første gang. Dette kræver en guide, der kan lære dig de vigtigste ting. Når du er færdig med denne rundvisning, er du klar til at udnytte fordelene ved databaseteknologien og begynde på en større rejse.
I denne artikel
|
Databasestyring Forbedr virksomhedskontinuitet Håndtering af problemer i forbindelse med beskyttelse af personlige oplysninger |
Forespørgsler og relaterede emner |
Datatyper |
Sundry |
Forbedr virksomhedskontinuitet
Din Access-løsning skal helst være aktiv hele tiden med minimal afbrydelse, men dine muligheder for at få adgang til en backend-database til Access er begrænset. Det er vigtigt at sikkerhedskopiere din Access-database, hvis du vil beskytte dine data, men det kræver, at dine brugere er offline. Så er der ikke-planlagt nedetid, der skyldes vedligeholdelsesmæssige opgraderinger af hardware/software, netværksnedbrud eller strømsvigt, hardwarefejl, sikkerhedsbrister eller endda cyberangreb. Du kan minimere nedetiden og følgerne for din virksomhed ved at sikkerhedskopiere en SQL Server-database, mens den er i brug. Desuden giver SQL Server også høj tilgængelighed (HA) og strategier for gendannelse efter nedbrud (DR). Disse to kombinerede teknologier kaldes for HADR. Se Virksomhedskontinuitet og databasegendannelse og Skab virksomhedskontinuitet med SQL Server (e-bog) for at få flere oplysninger.
Sikkerhedskopiering, mens databasen er i brug
SQL Server bruger en online-sikkerhedskopieringsproces, der kan udføres, mens databasen kører. Du kan lave en fuld sikkerhedskopiering, en delvis sikkerhedskopiering eller en sikkerhedskopiering af en fil. Ved en sikkerhedskopiering kopieres data og transaktionslogfiler, så gendannelseshandlingen fungerer normalt. Vær opmærksom på forskellene på muligheder for enkel eller fuld gendannelse, og hvordan de påvirker væksten af transaktionslogfiler, især med løsninger i selve virksomheden. Se Gendannelsesmodeller for at få flere oplysninger.
De fleste sikkerhedskopieringer sker med det samme, bortset fra filhåndtering og formindskelse af databasen. Hvis du derimod prøver at oprette eller slette en databasefil, mens en sikkerhedskopiering er i gang, mislykkes handlingen. Få flere oplysninger i Oversigt over sikkerhedskopiering.
HADR
De to mest almindelige teknikker til at opnå høj tilgængelighed og virksomhedskontinuitet er spejling og klyngedannelse. SQL Server integrerer spejlings- og klyngeteknologien med "Always On Failover Cluster Instances" og "Always On Availability Groups".
Spejling er en kontinuitetsløsning på databaseniveau, der understøtter næsten øjeblikkelig failover ved at opretholde en standby-database, en fuld kopi eller en spejling af den aktive database på separat hardware. Det kan fungere i en synkron tilstand (høj sikkerhed), hvor en indgående transaktion allokeres til alle servere på samme tid, eller i en asynkron tilstand (høj ydeevne), hvor en indgående transaktion allokeres til den aktive database og derefter kopieres til spejlingen på et fastlagt tidspunkt. Spejling er en databaseløsning og fungerer kun sammen med databaser, der bruger den fulde gendannelsesmodel.
Klyngedannelse er en løsning på serverniveau, der kombinerer servere til en enkelt datalagerplads, der gøres tilgængelig for brugeren, f. eks. som en enkelt forekomst. Brugerne opretter forbindelse til forekomsten og har aldrig brug for at vide, hvilken server i forekomsten der er aktiv i øjeblikket. Hvis en af serverne svigter eller skal være offline på grund af vedligeholdelse, ændres brugeroplevelsen ikke. Hver server i klyngen overvåges af klyngestyringen ved hjælp af en impuls, så den registrerer, hvornår den aktive server i klyngen skifter til offline og forsøger at skifte problemfrit til den næste server i klyngen, selvom der er en variabel tidsforsinkelse, når der skiftes.
Se AlwaysOn-failoverklyngeforekomster og AlwaysOn-tilgængelighedsgrupper: en løsning med høj tilgængelighed og gendannelse efter nedbrud for at få flere oplysninger.
SQL Server-sikkerhed
Selvom du kan beskytte din Access-database ved hjælp af Trust Center og kryptering af databasen, har SQL Server mere avancerede sikkerhedsfunktioner. Lad os se på tre funktioner, der skiller sig ud for Access-brugeren. Få flere oplysninger i Sikring af SQL Server.
Databasegodkendelse
Der er fire metoder til godkendelse af databaser i SQL Server, hvor du kan angive i en ODBC-forbindelsesstreng. Få flere oplysninger i Link til eller importer data fra en Azure SQL Server-database. Hver metode har sine fordele.
Integreret Windows-godkendelse Brug Windows-legitimationsoplysninger til brugervalidering, sikkerhedsroller og begrænsning af brugernes adgang til funktioner og data. Du kan udnytte legitimationsoplysninger til domænet og nemt administrere brugerrettigheder i dit program. Du kan også angive en værdi for Tjenestehovednavne (SPN'er). Få flere oplysninger i Vælg en godkendelsestilstand.
SQL Server-godkendelse Brugere skal oprette forbindelse med legitimationsoplysninger, der er opsat i databasen, ved at indtaste deres login-ID og adgangskode, første gang de får adgang til databasen i en session. Få flere oplysninger i Vælg en godkendelsestilstand.
Azure Active Directory Integrated-godkendelse Opret forbindelse til Azure SQL Server-databasen ved hjælp af Azure Active Directory. Når du har konfigureret Azure Active Directory-godkendelse, kræves ingen yderligere logon og adgangskode. Få mere at vide under Tilslutning til SQL-Database ved hjælp af Azure Active Directory-godkendelse.
Active Directory-godkendelse af adgangskode Opret forbindelse med legitimationsoplysninger, der er konfigureret i Azure Active Directory, ved at indtaste logonnavn og adgangskode. Få mere at vide under Tilslutning til SQL-Database ved hjælp af Azure Active Directory-godkendelse.
Tip Brug Trusselsregistrering til at modtage beskeder om en unormal databaseaktivitet, der angiver potentielle sikkerhedstrusler mod en Azure SQL Server-database. Få flere oplysninger i Trusselsregistrering i SQL-database.
Programsikkerhed
SQL Server har to sikkerhedsfunktioner på programniveau, som du kan udnytte med Access.
Dynamisk maskering af data Skjul følsomme oplysninger ved at maskere dem for ikke-privilegerede brugere. Du kan f. eks. maskere CPR-numre helt eller delvist.
 En delvis datamaske |
 En komplet datamaske |
Datamasker kan defineres på flere måder, og du kan anvende dem på forskellige datatyper. Datamaskering er politikbaseret på tabel- og kolonneniveau for en bestemt gruppe af brugere og anvendes i realtid ved forespørgsler. Få flere oplysninger i Dynamisk datamaskering.
Sikkerhed på rækkeniveau Du kan styre adgangen til bestemte databaserækker med følsomme oplysninger baseret på brugeregenskaber ved hjælp af sikkerhed på rækkeniveau. Databasesystemet anvender disse begrænsninger for adgang, og det gør sikkerhedssystemet mere pålideligt og solidt.

Der findes to typer sikkerhedsprædikater:
-
Et filterprædikat filtrerer rækker fra en forespørgsel. Filteret er gennemsigtigt, og slutbrugerens kan ikke se, at filtreringen finder sted.
-
Et blokprædikat forhindrer uautoriserede handlinger og udløser en undtagelse, hvis handlingen ikke kan udføres.
Få flere oplysninger i Sikkerhed på rækkeniveau.
Beskyttelse af data med kryptering
Beskyt data, der er inaktive, i transit, og mens de er i brug, uden at påvirke databasens ydeevne. Se SQL Server-kryptering for at få flere oplysninger.
Kryptering i inaktiv tilstand Hvis du vil beskytte personlige data mod offline-medieangreb på det fysiske lager, skal du bruge kryptering i inaktiv tilstand, også kaldet gennemsigtig datakryptering (TDE, Transparent Data Encryption). Det betyder, at dine data er beskyttede, også selvom de fysiske medier bliver stjålet eller bortskaffet forkert. TDE udfører kryptering og dekryptering af databaser, sikkerhedskopiering og transaktionslogfiler i realtid uden behov for ændringer i dine programmer.
Kryptering i transit Du kan kryptere data, der overføres via netværket, for at beskytte mod overvågning og “man-in-the-middle-angreb”. SQL Server understøtter Transport Layer Security (TLS) 1.2, der giver avanceret beskyttelse til kommunikation. Tabeldatastrøm-protokollen (TDS) bruges også til at beskytte kommunikationen på upålidelige netværk.
Kryptering i brug på klienten Hvis du vil beskytte personlige data, mens de er i brug, er "altid krypteret" den foretrukne funktion. Personlige data krypteres og dekrypteres af en driver på klientcomputeren uden at afsløre krypteringsnøgler til databaseprogrammet. Det betyder, at krypterede data kun kan ses af de personer, der er ansvarlige for administration af disse data, og ikke andre brugere med højt privilegeret adgang. Afhængigt af den type kryptering, der er valgt, kan Altid krypteret begrænse visse databasefunktioner, f. eks. søgning, gruppering og indeksering af krypterede kolonner.
Håndtering af problemer i forbindelse med beskyttelse af personlige oplysninger
Beskyttelse af personlige oplysninger er så udbredt, at EU har defineret juridiske krav via Persondataforordningen (GDPR). Heldigvis er en SQL Servers backend velegnet til at overholde disse krav. Implementering af GDPR foregår i en struktur med tre trin.

Trin 1: Vurder og administrer overholdelsesrisiko
GDPR kræver, at du identificerer og opbevarer de personlige oplysninger, du har i tabeller og filer. Disse oplysninger kan være alt fra et navn, et billede, en mailadresse, bankoplysninger, indlæg på sociale netværk, medicinske oplysninger eller endda en IP-adresse.
Et nyt værktøj, SQL Data Discovery and Classification, som er indbygget i SQL Server Management Studio, hjælper dig med at finde, klassificere, navngive og rapportere om følsomme data ved at anvende to metadata-attributter til kolonner:
-
Etiketter Definerer dataenes følsomhed.
-
Typer af oplysninger Giver yderligere granularitet om de datatyper, der er gemt i en kolonne.
En anden registreringsmekanisme, du kan bruge, er fuld tekstsøgning, som omfatter brug af CONTAINS- og FREETEXT-prædikater og funktioner med rækkesætværdier som f. eks CONTAINSTABLE og FREETEXTTABLE til brug sammen med SELECT-udsagnet. Ved hjælp af søgning i hele teksten kan du søge i tabeller for at finde ord, ordkombinationer eller variationer af et ord, som f. eks. synonymer eller bøjningsformer. Se Søgning i hele teksten for at få flere oplysninger.
Trin 2: Beskyttelse af personlige oplysninger
GDPR kræver, at du beskytter personlige oplysninger og begrænser adgangen til dem. Ud over de almindelige fremgangsmåder, du skal bruge til at administrere adgang til dit netværk og dine ressourcer, f.eks. firewall-indstillinger, kan du bruge sikkerhedsfunktioner i SQL Server som hjælp til at styre adgang til data:
-
SQL Server-godkendelse til at administrere brugeridentitet og forhindre uautoriseret adgang.
-
Sikkerhed på rækkeniveau til at begrænse adgangen til rækker i en tabel baseret på relationen mellem brugeren og disse data.
-
Dynamisk datamaskering til at begrænse adgangen til personlige data ved at maskere dem for brugere, der ikke er privilegerede.
-
Kryptering til at sikre, at personlige data beskyttes under overførsel og lagring og er beskyttet mod kompromis, herunder på serversiden.
Få flere oplysninger i SQL Server-sikkerhed.
Trin 3: Reager effektivt på anmodninger
GDPR kræver, at du altid har en historik over behandling af personlige data og gør denne historik tilgængelig for kontrolmyndighederne efter anmodning. I tilfælde af problemer, deriblandt utilsigtet adgang til data, giver beskyttelseskontrolfunktionerne dig mulighed for at reagere hurtigt. Data skal hurtigt gøres tilgængelige, hvis der er behov for rapportering. GDPR kræver f.eks., at brud på sikkerheden i forbindelse med personoplysninger anmeldes til den ansvarlige myndighed “senest 72 timer efter opdagelsen af dette.“
SQL Server 2017 gør rapporteringsopgaver lettere på flere måder:
-
SQL Server-overvågning hjælper dig med at sikre, at der altid er en historik over adgang til databasen og behandlingsaktiviteter. Der udføres en detaljeret kontrol med registrering af databaseaktiviteter, så du bedre kan forstå og identificere potentielle trusler, mistanke om misbrug eller brud på sikkerheden. Du kan hurtigt analysere data.
-
SQL Server-tidstabeller er systemversionsbaserede brugertabeller, der er beregnet til at opretholde en komplet historik over dataændringer. Du kan bruge disse til nem rapportering og tidsbesparende analyse.
-
SQL Vulnerability Assessment hjælper dig med at opdage sikkerheds- og tilladelsestrusler. Når et problem opdages, kan du også analysere database-scanningsrapporter for at finde handlinger, der kan løse problemer.
Få mere at vide i Create a platform of trust (e-bog) og Journey to GDPR Compliance.
Opret øjebliksbilleder af databasen
Et database-øjebliksbillede er en skrivebeskyttet, statisk visning af en SQL Server-database på et tidspunkt. Selvom du kan kopiere en Access-databasefil for effektivt at oprette et database-øjebliksbillede, har Access ikke en indbygget metodologi ligesom SQL Server. Du kan bruge et database-øjebliksbillede til at skrive rapporter ud fra data på tidspunktet for oprettelse af database-øjebliksbilledet. Du kan også bruge et database-øjebliksbillede til at bevare historiske data, f. eks. et for hvert regnskabskvartal, som du bruger til at afslutte rapporter i slutningen af perioden. Vi anbefaler følgende fremgangsmåder:
-
Navngiv øjebliksbilledet Hvert database-øjebliksbillede kræver et entydigt databasenavn. Føj formål og tidsramme til navnet, så det er nemmere at identificere. Hvis du f. eks. vil have vist et øjebliksbillede af AdventureWorks-databasen tre gange om dagen med seks timers mellemrum mellem klokken 6 og klokken 18 ud fra et 24-timers ur, skal du navngive dem AdventureWorks_snapshot_0600, AdventureWorks_snapshot_1200 og AdventureWorks_snapshot_1800.
-
Begræns antallet af øjebliksbilleder Hvert øjebliksbillede af en database bevares, indtil det direkte er blevet fjernet. Da hvert øjebliksbillede stadig vokser, kan det være en god ide at spare diskplads ved at slette et ældre øjebliksbillede, når du har oprettet et nyt øjebliksbillede. Hvis du f. eks. laver daglige rapporter, skal du beholde databasens øjebliksbillede i 24 timer og derefter slippe og erstatte det med et nyt.
-
Opret forbindelse til det rigtige øjebliksbillede Hvis du vil bruge et database-øjebliksbillede, skal en Access-frontend kende den korrekte placering. Når du indsætter et nyt øjebliksbillede i stedet for et eksisterende, skal du omdirigere Access til det nye øjebliksbillede. Føj logik til en Access-frontend for at sikre, at du opretter forbindelse til det rigtige database-øjebliksbillede.
Sådan opretter du et database-øjebliksbillede:
CREATE DATABASE AdventureWorks_dbss1800 ON
( NAME = AdventureWorks_Data, FILENAME =
'C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Data\AdventureWorks_snapshot_0600' )
AS SNAPSHOT OF AdventureWorks;
Få flere oplysninger i Database-øjebliksbilleder (SQL Server).
Samtidighedskontrol
Når mange brugere forsøger at ændre data i en database på samme tid, er der brug for et system med kontrolelementer, så de ændringer, der foretages af en person, ikke påvirker en anden persons ændringer. Dette kaldes samtidighedskontrol, og der er to grundlæggende låsestrategier: pessimistisk og optimistisk. Låsning kan forhindre brugere i at ændre data på en måde, der påvirker andre brugere. Låsning sikrer også databasens integritet, især med forespørgsler, der ellers kan give uventede resultater. Der er vigtige forskelle på, hvordan Access og SQL Server implementerer disse strategier for samtidighedskontrol.
I Access er standard-låsestrategien optimistisk og giver ejerskab over låsen til den første person, der forsøger at skrive til en post. Access viser dialogboksen Skrivekonflikt for den anden person, der forsøger at skrive til den samme post på samme tid. For at løse konflikten kan vedkommende gemme posten, kopiere den til Udklipsholder eller slippe ændringerne.
Du kan også bruge egenskabenRecordLocks til at ændre strategien for samtidighedskontrol. Denne egenskab påvirker formularer, rapporter og forespørgsler og har tre indstillinger:
-
Ingen låse I en formular kan brugerne forsøge at redigere den samme post samtidig, men dialogboksen Skrivekonflikt vises muligvis. I en rapport er poster ikke låst, mens der vises et eksempel på rapporten, eller den udskrives. I forespørgsler er poster ikke låst, mens forespørgslen køres. Sådan implementerer Access optimistisk låsning.
-
Alle poster Alle poster i den underliggende tabel eller forespørgsel er låst, mens formularen er åben i Formularvisning eller Dataarkvisning, når der vises et eksempel på rapporten, eller den udskrives, eller mens forespørgslen køres. Brugerne kan læse posterne under låsningen.
-
Redigeret post Når det gælder formularer og forespørgsler, låses en side med poster, når en bruger starter med at redigere et givent felt i posten, og forbliver låst, indtil brugeren flytter til en anden post. Derfor kan en post kun redigeres af én bruger ad gangen. Sådan implementerer Access pessimistisk låsning.
Få flere oplysninger i Dialogboksen Skrivekonflikt og Egenskaben RecordLocks.
I SQL Server fungerer samtidighedskontrol på denne måde:
-
Pessimistisk Når en bruger udfører en handling, der medfører, at en lås anvendes, kan andre brugere ikke udføre handlinger, der skaber konflikt med låsen, indtil ejeren har deaktiverer den. Denne samtidighedskontrol anvendes hovedsageligt i miljøer, hvor der er en høj grad af datakonflikt.
-
Optimistisk I optimistisk samtidighedskontrol låser brugerne ikke data, når de læser dem. Når en bruger opdaterer data, kontrollerer systemet, om en anden bruger har ændret dataene, efter de blev læst. Hvis en anden bruger opdaterer dataene, opstår der en fejl. Den bruger, der oplever fejlen, vil som regel gå tilbage til transaktionen og starte forfra. Denne samtidighedskontrol anvendes hovedsageligt i miljøer, hvor der er en lav grad af datakonflikt.
Du kan vælge typen af samtidighedskontrol ved at vælge flere transaktions-isolationsniveauer, der definerer niveauet af beskyttelse for transaktionen ud fra ændringer, der er foretaget af andre transaktioner ved hjælp af sætningen SET TRANSACTION:
SET TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED
| READ COMMITTED
| REPEATABLE READ
| SNAPSHOT
| SERIALIZABLE
}|
Isolationsniveau |
Beskrivelse |
|
Læsning ikke bekræftet |
Transaktioner er kun isolerede nok til at sikre, at fysisk ødelagte data ikke læses. |
|
Læsning bekræftet |
Transaktioner kan læse data, der tidligere er læst af en anden transaktion, uden at vente på, at den første transaktion afsluttes. |
|
Gentaget læsning |
Der forekommer læse- og skrivelåsninger på udvalgte data indtil slutningen af transaktionen, men fantomlæsninger kan forekomme. |
|
Øjebliksbillede |
Anvender rækkeversion for at sørge for ensartethed på transaktionsniveau. |
|
Kan serialiseres |
Transaktioner er fuldkommen isolerede fra hinanden. |
Få flere oplysninger i Vejledning til låsning af transaktioner og rækkeversionering.
Forbedr ydeevnen for forespørgsler
Når du har en aktiv Access-gennemkørselsforespørgsel, kan du benytte de avancerede metoder, som SQL Server kan bruge til at få den til at køre mere effektivt.
I modsætning til en Access-database giver SQL Server mulighed for parallelle forespørgsler, der optimerer udførelsen af forespørgslen, og indekseringshandlinger for computere med mere end én mikroprocessor (CPU). Da SQL Server kan udføre en forespørgsels- eller indekseringshandling parallelt ved hjælp af flere systemarbejdertråde, kan handlingen udføres hurtigt og effektivt.
Forespørgsler er en vigtig komponent i forbedringen af den overordnede ydeevne for din databaseløsning. Forkerte forespørgsler kører i det uendelige, oplever timeout og bruger ressourcer som f. eks. CPU'er, hukommelse og netværksbåndbredde. Dette gør kritiske virksomhedsoplysninger mindre tilgængelige. Selv én dårlig forespørgsel kan give alvorlige problemer med din databases ydeevne.
Se Hurtigere forespørgsler med SQL Server (e-bog) for at få flere oplysninger.
Forespørgselsoptimering
Adskillige værktøjer fungerer sammen for at hjælpe dig med at analysere en forespørgsels ydeevne og forbedre den: Forespørgselsoptimering, eksekveringsplaner og forespørgselslager.
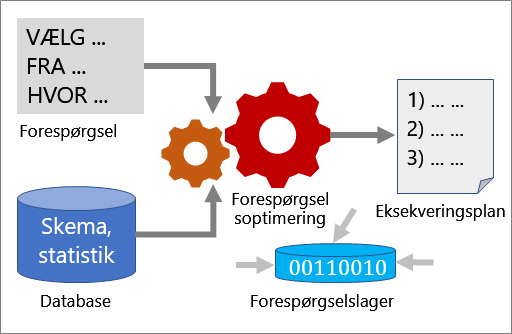
Forespørgselsoptimering
Forespørgselsoptimering er en af de vigtigste komponenter i SQL Server. Brug forespørgselsoptimering til at analysere en forespørgsel og vælge den mest effektive metode til at få adgang til de påkrævede data. Input til forespørgselsoptimering består af forespørgslen, databaseskemaet (tabel- og indeksdefinitioner) og databasestatistik. Forespørgselsoptimeringens output er en eksekveringsplan.
Se SQL Server-forespørgselsoptimering for at få flere oplysninger.
Eksekveringsplan
En eksekveringsplan er en definition, der opdeler kildetabellerne i rækkefølge for adgang og metoder, der bruges til at udtrække data fra hver tabel. Optimering er den proces, hvor du vælger en eksekveringsplan fra mange mulige planer. Hver af de mulige eksekveringsplaner har en tilknyttet omkostning i mængden af anvendte computerressourcer, og forespørgselsoptimering vælger den, der har de laveste anslåede omkostninger.
SQL Server skal også justeres dynamisk for at ændre betingelserne i databasen. Regression i planer for udførelse af forespørgsler kan påvirke ydeevnen betydeligt. Visse ændringer i en database kan forårsage, at en udførelsesplan er enten ineffektiv eller ugyldig, alt efter hvordan databasens nye tilstand er. SQL Server registrerer ændringerne, der ugyldiggør en eksekveringsplan, og markerer planen som ugyldig.
En ny plan skal derefter kompileres igen til den næste forbindelse, der udfører forespørgslen. De betingelser, der ugyldiggør en plan, omfatter:
-
Ændringer i en tabel eller visning, der henvises til i forespørgslen (ALTER TABLE og ALTER VIEW).
-
Ændringer af indekser, der bruges af eksekveringsplanen.
-
Opdateringer i den statistik, der bruges af eksekveringsplanen, genereres enten eksplicit fra en sætning, f. eks. UPDATE STATISTICS eller automatisk.
Få flere oplysninger i Eksekveringsplaner.
Forespørgselslager
Forespørgselslageret giver indsigt i valg og ydeevne for eksekveringsplan. Det strømliner forespørgslens ydeevne ved at hjælpe dig med hurtigt at finde forskelle i ydeevnen, der skyldes ændringer i eksekveringsplanen. Forespørgselslageret indsamler telemetridata, f. eks. en historik over forespørgsler, planer, kørselsstatistik og ventestatistik. Brug ALTER DATABASE-sætningen til at implementere Forespørgselslageret:
ALTER DATABASE AdventureWorks2012 SET QUERY_STORE = ON;
Få flere oplysninger i Overvågning af ydeevnen ved hjælp af Forespørgselslager.
Automatisk rettelse af plan
Den nemmeste metode til at forbedre ydeevnen for forespørgsler er den automatiske rettelse af plan, som er en funktion, der kan benyttes i Azure SQL-databasen. Du skal blot aktivere den og lade den fungere. Den overvåger og analyserer løbende eksekveringsplaner, registrerer problematiske eksekveringsplaner og retter automatisk ydeevneproblemer. Bag kulisserne benytter automatisk rettelse af plan en strategi med fire trin for at lære, tilpasse, bekræfte og gentage.
Få flere oplysninger i Automatisk justering.
Tilpasset behandling af forespørgsler
Du kan også få hurtigere forespørgsler blot ved at opgradere til SQL Server 2017, som har en ny funktion, der kaldes for tilpasset forespørgselsbehandling. SQL Server tilpasser valgmulighederne i forespørgselsplanen baseret på kørslens egenskaber.
Estimering af kardinalitet giver et estimat af antallet af rækker, der behandles ved hvert trin i en eksekveringsplan. Unøjagtige estimeringer kan resultere i langsom responstid for forespørgsler, unødvendigt ressourceforbrug (hukommelse, CPU og IO) samt reduceret dataoverførselshastighed og samtidighed. Tre metoder bruges til at tilpasse til programmets arbejdsbyrde-karakteristika:
-
Batchtilstand-hukommelse giver feedback Dårligere vurdering af kardinalitet kan forårsage, at forespørgsler "spildes til disken" eller bruger for meget hukommelse. SQL Server 2017 tilpasser hukommelsestildelinger ud fra eksekveringsfeedback, fjerner spild til disk og forbedrer samtidigheden for gentagne forespørgsler.
-
Tilpassede deltagelser for batch-tilstand Tilpasset tilknytning vælger dynamisk en bedre intern deltagelsestype (indlejrede sløjfedeltagelser, flettede deltagelser eller hashede deltagelser) under kørslen med udgangspunkt i faktiske inputrækker. En plan kan derfor skifte dynamisk til en bedre strategi for deltagelse under udførelse.
-
Interleavet eksekvering Tabelværdibaserede funktioner med flere sætninger er traditionelt blevet behandlet som en sort boks af forespørgselsbehandlingen. SQL Server 2017 kan forbedre antallet af rækker for at forbedre downstream-handlinger.
Du kan gøre arbejdsbelastninger automatisk berettigede til tilpasset behandling af forespørgsler ved hjælp af et kompatibilitetsniveau på 140 for databasen:
ALTER DATABASE [YourDatabaseName] SET COMPATIBILITY_LEVEL = 140;
Se Intelligent behandling af forespørgsler i SQL-databaser for at få flere oplysninger.
Metoder til at forespørge
I SQL Server er der flere måder at forespørge på, og de har hver deres fordele. Du vil gerne vide, hvad de er, så du kan vælge den rette mulighed til din adgangsløsning. Den bedste metode at oprette dine TSQL-forespørgsler på er at redigere og teste dem interaktivt ved hjælp af SSMS (SQL Server Management Studio) Transact-SQL-editor, som har IntelliSense, der hjælper dig med at vælge de rigtige søgeord og kontrollere, om der er syntaksfejl.
Visninger
I SQL Server er en visning ligesom en virtuel tabel, hvor visningsdataene kommer fra en eller flere tabeller eller andre visninger. Men der refereres til visninger ligesom tabeller i forespørgsler. Visninger kan skjule forespørgslernes kompleksitet og hjælpe med at beskytte data ved at begrænse rækkerne og kolonnerne. Her er et eksempel på en enkel visning:
CREATE VIEW HumanResources.EmployeeHireDate AS
SELECT p.FirstName, p.LastName, e.HireDate
FROM HumanResources.Employee AS e JOIN Person.Person AS p
ON e.BusinessEntityID = p.BusinessEntityID;
Hvis du vil opnå optimal ydeevne og redigere visningsresultaterne, skal du oprette en indekseret visning, som bevares i databasen, på samme måde som en tabel f.eks. har tildelt lagerplads, og kan blive forespurgt ligesom enhver anden tabel. Hvis du vil bruge den i Access, skal du oprette et link til visningen, ligesom når du opretter et link til en tabel. Her er et eksempel på en indekseret visning:
CREATE VIEW Sales.vOrders
WITH SCHEMABINDING
AS
SELECT SUM(UnitPrice*OrderQty*(1.00-UnitPriceDiscount)) AS Revenue,
OrderDate, ProductID, COUNT_BIG(*) AS COUNT
FROM Sales.SalesOrderDetail AS od, Sales.SalesOrderHeader AS o
WHERE od.SalesOrderID = o.SalesOrderID
GROUP BY OrderDate, ProductID;
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON Sales.vOrders (OrderDate, ProductID);
Der er dog begrænsninger. Du kan ikke opdatere data, hvis mere end én basistabel er blevet påvirket, eller hvis visningen indeholder aggregeringsfunktioner eller en DISTINCT-sætning. Hvis SQL Server returnerer en fejlmeddelelse om, at den ikke ved, hvilken post du skal slette, kan det være nødvendigt at tilføje en sletningsaktivering i visningen. Som en sidste ting kan du ikke bruge sætningen ORDER BY, ligesom du kan med en Access-forespørgsel.
Få flere oplysninger i Visninger og Opret indekserede visninger.
Gemte procedurer
En gemt procedure er en gruppe af en eller flere TSQL-sætninger, der tager inputparametre, returnerer outputparametre og angiver succes eller fejl med en statusværdi. De fungerer som et mellemliggende lag mellem Access-frontend og SQL Server-backend. Lagrede procedurer kan være så enkle som en SELECT-sætning eller så kompleks som ethvert program. Her er et eksempel:
CREATE PROCEDURE HumanResources.uspGetEmployees
@LastName nvarchar(50),
@FirstName nvarchar(50)
AS
SET NOCOUNT ON;
SELECT FirstName, LastName, Department
FROM HumanResources.vEmployeeDepartmentHistory
WHERE FirstName = @FirstName AND LastName = @LastName
AND EndDate IS NULL;
Når du bruger en gemt procedure i Access, returnerer den normalt et resultatsæt tilbage til en formular eller en rapport. Den kan dog udføre andre handlinger, som ikke returnerer resultater, f. eks. DDL- eller DML-sætninger. Når du bruger en gennemførselsforespørgsel, skal du konfigurere egenskaben Returnerer poster korrekt.
Få flere oplysninger i Gemte procedurer.
Almindelige tabeludtryk
En række almindelige tabeludtryk (CTE) er ligesom en midlertidig tabel, der genererer et navngivet resultatsæt. Den findes kun til udførelse af en enkelt forespørgsel eller DML-sætning. En CTE er indbygget i den samme kodelinje som den SELECT-sætning eller den DML-sætning, der bruger den, hvorimod oprettelse og brug af en midlertidig tabel eller visning generelt er en proces med to trin. Her er et eksempel:
-- Define the CTE expression name and column list.
WITH Sales_CTE (SalesPersonID, SalesOrderID, SalesYear)
AS
-- Define the CTE query.
(
SELECT SalesPersonID, SalesOrderID, YEAR(OrderDate) AS SalesYear
FROM Sales.SalesOrderHeader
WHERE SalesPersonID IS NOT NULL
)
-- Define the outer query referencing the CTE name.
SELECT SalesPersonID, COUNT(SalesOrderID) AS TotalSales, SalesYear
FROM Sales_CTE
GROUP BY SalesYear, SalesPersonID
ORDER BY SalesPersonID, SalesYear;
En CTE har flere fordele, herunder følgende:
-
Da CTE'er forbigående, behøver du ikke at oprette dem som permanente databaseobjekter ligesom visninger.
-
Du kan referere til den samme CTE mere end én gang i en forespørgsel eller DML-sætning, hvilket gør din kode nemmere at administrere.
-
Du kan bruge forespørgsler, der refererer til et CTE, for at definere en markør.
Få mere at vide i WITH common_table_expression.
Brugerdefinerede funktioner
En brugerdefineret funktion (UDF) kan udføre forespørgsler og beregninger og returnere enten skalarværdier eller dataresultatsæt. De fungerer ligesom funktioner i programmeringssprog, der accepterer parametre, udfører en handling såsom en kompleks beregning og returnerer resultatet af handlingen som en værdi. Her er et eksempel:
CREATE FUNCTION dbo.ISOweek (@DATE datetime)
RETURNS int WITH SCHEMABINDING -- Helps improve performance
WITH EXECUTE AS CALLER
AS
BEGIN
DECLARE @ISOweek int;
SET @ISOweek= DATEPART(wk,@DATE)+1
-DATEPART(wk,CAST(DATEPART(yy,@DATE) as CHAR(4))+'0104');
-- Special cases: Jan 1-3 may belong to the previous year
IF (@ISOweek=0)
SET @ISOweek=dbo.ISOweek(CAST(DATEPART(yy,@DATE)-1
AS CHAR(4))+'12'+ CAST(24+DATEPART(DAY,@DATE) AS CHAR(2)))+1;
-- Special case: Dec 29-31 may belong to the next year
IF ((DATEPART(mm,@DATE)=12) AND
((DATEPART(dd,@DATE)-DATEPART(dw,@DATE))>= 28))
SET @ISOweek=1;
RETURN(@ISOweek);
END;
GO
SET DATEFIRST 1;
SELECT dbo.ISOweek(CONVERT(DATETIME,'12/26/2004',101)) AS 'ISO Week';
En UDF har visse begrænsninger. De kan f. eks. ikke bruge visse ikke-deterministiske systemfunktioner, udføre DML- eller DDL-sætninger eller lave dynamiske SQL-forespørgsler.
Få flere oplysninger i Brugerdefinerede funktioner.
Tilføj nøgler og indeks
Uanset hvilket databasesystem du bruger, er nøgler og indekser uadskillelige.
Nøgler
I SQL Server skal du huske at oprette primære nøgler for hver tabel og fremmede nøgler for hver enkelt relateret tabel. Den tilsvarende funktion i SQL Server til datatypen Access AutoNumber er egenskaben IDENTITY, som kan bruges til at oprette nøgleværdier. Når du har anvendt denne egenskab til en numerisk kolonne, bliver den skrivebeskyttet og vedligeholdes af databasesystemet. Når du indsætter en post i en tabel, der indeholder en IDENTITY-kolonne, øger systemet automatisk værdien for IDENTITY-kolonnen med 1 og starter fra 1, men du kan styre disse værdier med argumenter.
Se OPRET TABEL, IDENTITET (egenskab) for at få flere oplysninger.
Indekser
Som altid er markeringen af indekser en balancegang mellem forespørgselshastighed og opdateringsomkostninger. I Access har du én type indeks, men i SQL Server har du 12. Du kan heldigvis bruge forespørgselsoptimering som hjælp til at vælge det mest effektive indeks. Og i Azure SQL kan du bruge automatisk indeksstyring, som er en funktion til automatisk justering, der anbefaler tilføjelse eller fjernelse af indekser for dig. I modsætning til Access skal du oprette dine egne indekser for fremmede nøgler i SQL Server. Du kan også oprette indekser i en indekseret visning for at forbedre ydeevnen for forespørgsler. Nedesiden for en indekseret visning øges, når du redigerer data i visningens basistabeller, fordi visningen også skal opdateres. Få flere oplysninger i Vejledning til SQL Server-indeksarkitektur og -design og Indekser.
Udfør transaktioner
Det er svært at udføre en online-transaktionsproces (OLTP), når du bruger Access, men det er forholdsvis nemt med SQL Server. En transaktion er en enkelt arbejdsenhed, der bekræfter alle dataændringer, når de er gennemført, men annullerer ændringerne, når de ikke lykkedes. En transaktion skal have fire egenskaber, som ofte kaldes ACID:
-
Atomitet En transaktion skal være en atomisk arbejdsenhed. Enten udføres alle dataændringerne, eller også udføres ingen af dem.
-
Konsekvens Når den er fuldført, skal en transaktion efterligne alle data i en konsekvent tilstand. Det betyder, at alle regler for dataintegritet anvendes.
-
Isolation Ændringer, der er foretaget af samtidige transaktioner, isoleres fra den aktuelle transaktion.
-
Holdbarhed Når en transaktion er fuldført, er ændringerne permanente, selv i tilfælde af systemfejl.
Du kan bruge en transaktion til at sikre garanteret dataintegritet, f. eks. når der hæves penge i en automat, eller en automatisk lønindbetaling. Du kan udføre udtrykkelige, implicitte eller batchbaserede transaktioner. Her er to eksempler på TSQL:
-- Using an explicit transaction
BEGIN TRANSACTION;
DELETE FROM HumanResources.JobCandidate
WHERE JobCandidateID = 13;
COMMIT;
-- the ROLLBACK statement rolls back the INSERT statement, but the created table still exists.
CREATE TABLE ValueTable (id int);
BEGIN TRANSACTION;
INSERT INTO ValueTable VALUES(1);
INSERT INTO ValueTable VALUES(2);
ROLLBACK;
Få flere oplysninger i Transaktioner.
Brug af begrænsninger og udløsere
Alle databaser har metoder til at opretholde dataintegritet.
Betingelser
I Access kan du gennemtvinge referentiel integritet i en tabelrelation via fremmede nøgle-primære nøgleparringer, overlappende opdateringer og sletninger samt valideringsregler. Få flere oplysninger i Vejledning til tabelrelationer og Begræns datainput ved hjælp af valideringsregler.
I SQL Server bruger du UNIQUE- og CHECK-begrænsninger, som er databaseobjekter, der sørger for dataintegritet SQL Server-tabeller. Hvis du vil validere, om en værdi er gyldig i en anden tabel, skal du bruge en begrænsning for en fremmed nøgle. Hvis du vil validere, om en værdi i en kolonne er inden for et bestemt område, skal du bruge en kontrolbegrænsning. Disse objekter er din første forsvarslinje og er udviklet til at fungere effektivt. Få flere oplysninger i Unikke betingelser og Kontrolbegrænsninger.
Udløsere
Access har ikke databaseudløsere. I SQL Server kan du bruge udløsere til at gennemtvinge komplekse regler for dataintegritet og til at køre denne forretningslogik på serveren. En databaseudløser er en gemt procedure, der køres, når bestemte handlinger forekommer i en database. Udløseren er en begivenhed, f. eks. tilføjelse eller sletning af en post i en tabel, der udløses og derefter udfører den gemte procedure. Selvom en Access-database kan sikre referentiel integritet, når en bruger forsøger at opdatere eller slette data, har SQL Server en række avancerede udløsere. Du kan f. eks. programmere en udløser til at slette poster i bulk og sikre dataintegritet. Du kan også føje udløsere til tabeller og visninger.
Se Udløsere – DML, Udløsere – DDL og Sådan designes en T-SQL-udløser for at få flere oplysninger.
Brug beregnede kolonner
I Access kan du oprette en beregnet kolonne ved at føje den til en forespørgsel og opbygge et udtryk, f. eks.:
Extended Price: [Quantity] * [Unit Price]
I SQL Server kaldes den tilsvarende funktion en beregnet kolonne. Dette er en virtuel kolonne, der ikke gemmes fysisk i tabellen, medmindre kolonnen er markeret som PERSISTED. Ligesom en beregnet kolonne bruger en beregnet kolonne data fra andre kolonner i et udtryk. Hvis du vil oprette en beregnet kolonne, skal du føje den til en tabel. Det kunne f.eks. være:
CREATE TABLE dbo.Products
(
ProductID int IDENTITY (1,1) NOT NULL
, QtyAvailable smallint
, UnitPrice money
, InventoryValue AS QtyAvailable * UnitPrice
); Få flere oplysninger i Angiv beregnede kolonner i en tabel.
Giv dine data tidsstempler
Nogle gange tilføjer du et tabelfelt for at registrere et tidsstempel, når der oprettes en post, så du kan gemme dataindtastningen. I Access kan du blot oprette en datokolonne med standardværdien for =Now(). Hvis du vil optage en dato eller et klokkeslæt i SQL server, skal du bruge datatypen datetime2 med standardværdien SYSDATETIME().
Bemærk Undgå modstridende rækkeversioner ved at føje et tidsstempel til dine data. Tidsstemplet for nøgleordet er et synonym for rækkeversionen i SQL Server, men du skal bruge nøgleordet "rowversion". I SQL Server er "rowversion" en datatype, der eksponerer automatisk genererede, entydige binære tal i en database, og anvendes generelt som en mekanisme til versionsstempling af tabelrækker. Men datatypen "rowversion" er blot et trinvist tal, der ikke bevarer en dato eller et klokkeslæt og det er ikke beregnet til at tidsstemple en række.
Få flere oplysninger i rowversion. Få flere oplysninger om brug af "rowversion" til miminering af konflikter i poster i Migrer en Access-database til SQL Server.
Administrer store objekter
I Access kan du administrere ustrukturerede data, f. eks. filer, fotos og billeder, ved hjælp datatypen Vedhæftet fil. I SQL Server-terminologi kaldes ustrukturerede data for en Blob (Binary Large Object eller binært stort objekt), og du kan arbejde med dem på flere måder.
FILESTREAM Anvender datatypen varbinary(max) til at gemme de ustrukturerede data i filsystemet i stedet for databasen. Få flere oplysninger i Access FILESTREAM-data med Transact-SQL.
Filtabel Gemmer blobs i særlige tabeller ved navn FileTables og gør dem kompatible med Windows-programmer, som om de var gemt i filsystemet og uden at foretage ændringer i dine-klientprogrammer. Filtabel kræver brug af FILESTREAM. Få flere oplysninger i FileTables.
Eksternt BLOB-lager (RBS) Gemmer binære store objekter (BLOB'er) i råvarebaserede lagerløsninger i stedet for direkte på-serveren. Dette sparer plads og kræver færre hardwareressourcer. Få flere oplysninger i Binary Large Object-data (Blob).
Arbejd med hierarkiske data
Selvom relationsdatabaser som f. eks. Access er meget fleksible, er arbejde med hierarkiske relationer en undtagelse, og det kræver ofte komplekse SQL-sætninger eller en kompleks kode. Eksempler på hierarkiske data omfatter: en organisationsstruktur, et filsystem, en taksonomi af sproglige udtryk og en graf over links mellem websider. SQL Server har en indbygget hierarchyid-datatype og et sæt hierarkiske funktioner, der gør det nemt at gemme, sende forespørgsler og administrere hierarkiske data.
Se Hierarkiske data og Selvstudium: Brug af datatypen Hierarki-id for at få flere oplysninger.
Manipuler JSON-tekst
JavaScript Object notation (JSON) er en webtjeneste, der bruger tekst, som et menneske kan læse, til at overføre data som attribut-værdipar i asynkron kommunikation mellem browser og server. Det kunne f.eks. være:
{
"firstName": "Mary",
"lastName": "Contrary",
"spouse": null,
"age": 27
}
Access har ikke nogen indbyggede metoder til at administrere JSON-data, men i SQL Server kan du hurtigt gemme, indeksere, forespørge og udtrække JSON-data. Du kan konvertere og gemme JSON-tekst i en tabel eller formatere data som JSON-tekst. Det kan f. eks. være, at du vil formatere forespørgselsresultater som JSON for en webapp eller tilføje JSON-datastrukturer i rækker og kolonner.
Bemærk JSON understøttes ikke i VBA. Du kan også bruge XML i VBA ved hjælp af MSXML-biblioteket.
Få flere oplysninger i JSON-data i SQL Server.
Ressourcer
Nu er det et godt tidspunkt at lære mere om SQL Server og Transact SQL (TSQL). Som du har set, er der mange funktioner som Access, men også funktioner, som Access ikke har. Du kan udforske det næste niveau med en række undervisningsressourcer:
|
Ressource |
Beskrivelse |
|
Videobaseret kursus |
|
|
Selvstudier om SQL Server 2017 |
|
|
Praktisk undervisning til Azure |
|
|
Bliv ekspert |
|
|
Den primære landingsside |
|
|
Hjælpeoplysninger |
|
|
Hjælpeoplysninger |
|
|
En oversigt over skyen |
|
|
En visuel oversigt over de nye funktioner |
|
|
En oversigt over funktioner i versioner |
|
|
Download SQL Server Express 2017 |
|
|
Download eksempeldatabaser |









