
V tomto článku sa popisuje syntax vzorca a používanie funkcie LINEST v Microsoft Exceli.
Popis
Funkcia LINEST vypočítava štatistiky pre určitú čiaru tak, že pomocou metódy najmenších štvorcov vypočítava priebeh priamky, ktorá najlepšie zodpovedá daným údajom, a potom vráti pole popisujúce túto priamku. Funkciu LINEST môžete skombinovať s inými funkciami a vypočítavať tak štatistiky pre iné typy modelov s lineárnymi neznámymi vrátane polynomických, logaritmických, exponenciálnych a mocninových radov. Keďže táto funkcia vráti pole hodnôt, musí byť zadaná ako vzorec poľa. Pokyny k tejto funkcii sa vzťahujú na príklady v tomto článku.
Rovnica pre výpočet tejto priamky je:
y = mx + b
alebo
y = m1x1 + m2x2 + ... + b
ak existuje viacero rozsahov hodnôt x, kde závislé hodnoty y sú funkciou nezávislých hodnôt x. Hodnoty m sú koeficienty zodpovedajúce každej hodnote x a b je konštantná hodnota. Všimnite si, že vektory môžu byť y, x a m. Pole, ktoré vráti funkcia LINEST , je {mn,mn-1,...,m1,b}. Funkcia LINEST môže vrátiť aj ďalšie regresné štatistiky.
Syntax
LINEST(známe_y; [známe_x]; [konštanta]; [štatistika])
Syntax funkcie LINEST obsahuje nasledovné argumenty:
Syntax
-
známe_y Povinný argument. Je to množina známych hodnôt y pre rovnicu y = mx + b.
-
Ak sa rozsah argumentu známe_y nachádza v jednom stĺpci, potom sa každý stĺpec argumentu známe_x považuje za samostatnú premennú.
-
Ak sa rozsah argumentu známe_y nachádza v jedinom riadku, potom sa každý riadok argumentu známe_x považuje za samostatnú premennú.
-
-
známe_x Voliteľný argument. Je to množina známych hodnôt x pre rovnicu y = mx + b.
-
Rozsah pre argument známe_x môže zahŕňať viacero množín premenných. Ak sa použije iba jedna premenná, argumenty známe_y a známe_x môžu byť rozsahy ľubovoľného tvaru, ak majú rovnaké rozmery. Ak sa použijú viaceré premenné, argument známe_y musí byť vektor (t.j. rozsah s výškou jedného riadka alebo šírkou jedného stĺpca).
-
Ak sa argument známe_x vynechá, predpokladá sa, že ide o pole {1;2;3;...} rovnakej veľkosti, akú má aj argument známe_y.
-
-
konštanta Voliteľný argument. Je to logická hodnota, ktorá určuje, či sa má konštanta b rovnať hodnote 0.
-
Ak je hodnota argumentu konštanta TRUE alebo nie je zadaná, konštanta b sa vypočítava normálne.
-
Ak je hodnota argumentu konštanta FALSE, konštanta b = 0 a hodnoty m sa upravia tak, aby platilo, že y = mx.
-
-
štatistika Voliteľný argument. Je to logická hodnota, ktorá určuje, či má funkcia vrátiť aj ďalšie regresné štatistiky.
-
Ak má argument štatistika hodnotu TRUE, funkcia LINEST vráti dodatočnú regresnú štatistiku. výsledkom je, že vrátené pole je {mn,mn-1,...,m1;b; sen,sen-1,...,se1,seb; r 2,sey; F,df; ssreg,ssresid}.
-
Ak je hodnota argumentu štatistika FALSE alebo nie je zadaná, funkcia LINEST vráti iba koeficienty m a konštantu b.
Ďalšie regresné štatistiky sú:
-
|
Štatistika |
Popis |
|---|---|
|
se1;se2;...;sen |
Štandardné chyby pre regresné koeficienty m1;m2;...;mn. |
|
seb |
Štandardná chyba konštanty b (seb = #NEDOSTUPNÝ, ak je hodnota argumentu konštanta FALSE). |
|
r2 |
Určujúci koeficient. Porovnáva odhadované a skutočné hodnoty y a rozsahy v hodnotách od 0 do 1. Ak je hodnota 1, vo vzorke existuje dokonalá korelácia – neexistuje žiadny rozdiel medzi odhadovanou hodnotou y a skutočnou hodnotou y. V druhom extréme, ak je determinačný koeficient 0, regresná rovnica nie je užitočná pri predpovedaní hodnoty y. Informácie o spôsobe výpočtuhodnoty 2 nájdete v časti Poznámky ďalej v tejto téme. |
|
sey |
Štandardná chyba odhadu y. |
|
o |
F-štatistika alebo pozorovaná hodnota F. F-štatistika sa používa na určenie, či sa pozorovaný vzťah medzi závislými a nezávislými premennými vyskytuje náhodne. |
|
df |
Počet stupňov voľnosti. Stupne voľnosti sa používajú na určenie kritických hodnôt F v štatistickej tabuľke. Porovnaním hodnôt z tabuľky s F-štatistikou, ktorú vypočítala funkcia LINEST, môžete určiť hladinu spoľahlivosti modelu. Informácie o výpočte parametra df nájdete v časti Poznámky tejto témy. Použitie argumentov F a df je uvedené v príklade číslo 4. |
|
ssreg |
Regresný súčet štvorcov. |
|
ssresid |
Reziduálny súčet štvorcov. Informácie o spôsobe výpočtu ssreg a ssresid nájdete nižšie v časti Poznámky. |
Nasledujúci príklad uvádza poradie, v ktorom sa vracajú dodatočné regresné štatistiky.

Poznámky
-
Ľubovoľnú priamku môžete jednoznačne určiť pomocou smernice a priesečníka s osou y:
Smernica (m):
Ak chcete nájsť sklon čiary, často napísaný ako m, vziať dva body na trati, (x1,y1) a (x2,y2); smernica sa rovná (y2 - y1)/(x2 - x1).Priesečník y (b):
Priesečník y čiary, často napísaný ako b, je hodnota y v bode, kde čiara pretína os y.Rovnica priamky je y = mx + b. Keď poznáte hodnoty m a b, môžete vypočítať ľubovoľný bod v riadku tak, že do rovnice zapojíte hodnotu y alebo x. Môžete použiť aj funkciu TREND .
-
Ak máte iba jedinú nezávislú premennú x, hodnoty smernice a priesečníka s osou y môžete získať priamo z nasledujúcich vzorcov:
Svah:
=INDEX(LINEST(known_y;known_x);1)Priesečník y:
=INDEX(LINEST(known_y;known_x);2) -
Presnosť priamky vypočítanej funkciou LINEST závisí od miery rozptylu údajov. Čím je linearita údajov väčšia, tým je model funkcie LINEST presnejší. Funkcia LINEST používa na určenie najvhodnejšej závislosti pre údaje metódu najmenších štvorcov. Ak máte iba jednu nezávislú premennú x, hodnoty m a b sa budú počítať podľa nasledovných vzorcov:
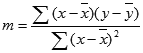
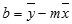
kde x a y sú priemerné hodnoty vzorky, t. j. x =AVERAGE(známe_x) a y = AVERAGE(známe_y).
-
Funkcie LINEST a LOGEST dokážu vypočítať najlepšiu priamku alebo exponenciálnu krivku, ktorá vyhovuje vašim údajom. Musíte sa však rozhodnúť, ktorý z týchto dvoch výsledkov najlepšie vyhovuje vašim údajom. Môžete vypočítať trend (known_y,known_x) pre priamku alebo GROWTH(known_y, known_x) pre exponenciálnu krivku. Tieto funkcie bez argumentu new_x vrátia pole hodnôt y predpovedaných pozdĺž tejto čiary alebo krivky v skutočných údajových bodoch. Potom môžete porovnať predpovedané hodnoty so skutočnými hodnotami. Možno ich budete chcieť zobraziť v grafe pre vizuálne porovnanie.
-
V regresnej analýze Excel vypočíta pre každý bod rozdiel medzi hodnotou y odhadovanou pre daný bod a jej skutočnou hodnotou y. Súčet týchto druhých rozdielov sa nazýva reziduálny súčet štvorcov, ssresid. Excel potom vypočíta celkový súčet štvorcov, sstotal. Ak argument konštanty = TRUE alebo je vynechaný, celkový súčet štvorcov je súčtom druhých rozdielov medzi skutočnými hodnotami y a priemerom hodnôt y. Keď argument konštanty = FALSE, celkový súčet štvorcov je súčtom druhých mocnín skutočných hodnôt y (bez odčítania priemernej hodnoty y z každej jednotlivej hodnoty y). Potom regresný súčet štvorcov, ssreg, možno nájsť z: ssreg = sstotal - ssresid. Čím menší je reziduálny súčet štvorcov, v porovnaní s celkovým súčtom štvorcov, tým väčšia je hodnota koeficientu určenia r2, čo je indikátor toho, ako dobre rovnica vyplývajúca z regresnej analýzy vysvetľuje vzťah medzi premennými. Hodnota r2 sa rovná ssreg/sstotal.
-
V niektorých prípadoch jeden alebo viacero stĺpcov X (predpokladajme, že stĺpce Y a X sú v stĺpcoch) nemusia mať žiadnu ďalšiu prediktívnu hodnotu v prítomnosti ostatných stĺpcov X. Inými slovami, odstránenie jedného alebo viacerých stĺpcov X môže viesť k predpovedaným hodnotám Y, ktoré sú rovnako presné. V takom prípade by sa tieto nadbytočné stĺpce X mali vynechať z regresného modelu. Tento jav sa nazýva kolinearita, pretože akýkoľvek nadbytočný stĺpec X možno vyjadriť ako súčet násobkov stĺpcov x, ktoré nie sú nadbytočné. Funkcia LINEST skontroluje kolinearitu a odstráni všetky nadbytočné stĺpce X z regresného modelu, keď ich identifikuje. Odstránené stĺpce X možno rozpoznať vo výstupe LINEST ako s 0 koeficientmi okrem 0 se hodnôt. Ak sa niektoré stĺpce odstránia ako nadbytočné, bude to mať vplyv na hodnotu df, pretože df závisí od počtu stĺpcov X, ktoré sa skutočne používajú na prediktívne účely. Podrobnosti o výpočte df nájdete v príklade 4. Ak sa df zmení z dôvodu odstránenia nadbytočných stĺpcov X, ovplyvní to aj hodnoty sey a F. Kolinearita by mala byť v praxi relatívne zriedkavá. Jeden prípad, v ktorom je väčšia pravdepodobnosť vzniku, je, že niektoré stĺpce X obsahujú iba 0 a 1 hodnoty ako indikátory toho, či predmet experimentu je alebo nie je členom určitej skupiny. Ak argument const = TRUE alebo je vynechaný, funkcia LINEST efektívne vloží ďalší stĺpec X všetkých 1 hodnôt na modelovanie priesečníka. Ak máte stĺpec s hodnotou 1 pre každý predmet v prípade samca alebo 0, ak nie, a tiež máte stĺpec s hodnotou 1 pre každý predmet, ak je samica, alebo 0, ak nie, tento druhý stĺpec je nadbytočný, pretože jeho položky možno získať odčítaním položky v stĺpci "male indicator" od položky v ďalšom stĺpci všetkých 1 hodnôt pridaných funkciou LINEST .
-
Ak sa z modelu neodstránia žiadne stĺpce X v dôsledku kolinearity, hodnota df sa vypočíta nasledovným spôsobom: Ak existuje počet stĺpcov k s hodnotami známe_x a argument konštanta = TRUE alebo je vynechaný, df = n – k – 1. Ak argument konštanta = FALSE, df = n – k. V oboch prípadoch každý stĺpec X, ktorý bol odstránený z dôvodu kolinearity, zvyšuje hodnotu df o 1.
-
Keď zadávate ako argument konštantu poľa (ako je napríklad známe_x), hodnoty v tom istom riadku oddeľujte čiarkou a jednotlivé riadky oddeľujte bodkočiarkou. Znaky oddeľovača závisia od miestnych nastavení počítača a môžu sa odlišovať.
-
Poznamenávame, že hodnoty y predpovedané regresnou rovnicou nemusia platiť, ak sú mimo oblasti hodnôt y, z ktorých ste rovnicu vytvárali.
-
Algoritmus použitý vo funkcii LINEST je odlišný od algoritmu použitého vo funkciách SLOPE a INTERCEPT. V prípade neurčených a kolineárnych údajov môže rozdiel medzi týmito algoritmami viesť k odlišným výsledkom. Ak napríklad údajové body argumentu známe_y sú 0 a údajové body argumentu známe_x sú 1:
-
Funkcia LINEST vráti hodnotu 0. Algoritmus funkcie LINEST je navrhnutý tak, aby vrátil primerané výsledky pre kolineárne údaje, a v tomto prípade je možné získať najmenej jednu odpoveď.
-
Funkcie SLOPE a INTERCEPT vrátia #DIV/0! Ak je zadané umiestnenie pred prvou alebo za poslednou položkou v poli, výsledkom vzorca bude chybová hodnota #ODKAZ!. Algoritmus funkcií SLOPE a INTERCEPT je navrhnutý tak, aby hľadal iba jednu odpoveď, a v tomto prípade môže existovať viac ako jedna odpoveď.
-
-
Okrem funkcie LOGEST môžete na výpočet štatistiky iných regresných typov použiť aj funkciu LINEST, a to tak, že zadáte funkcie premenných x a y ako rady x a y funkcie LINEST. Napríklad pomocou vzorca:
=LINEST(hodnotyy; hodnotyx^STĹPEC($A:$C))
v prípade, že máte jeden stĺpec hodnôt y a jeden stĺpec hodnôt x, môžete vypočítať kubickú (polynómnu tretieho rádu) aproximáciu vo forme:
y = m1*x + m2*x^2 + m3*x^3 + b
Úpravou tohto vzorca môžete vypočítať iné typy regresií, ale v niektorých prípadoch treba upraviť výstupné hodnoty a iné štatistiky.
-
Hodnota F-testu, ktorú vracia funkcia LINEST, sa odlišuje od hodnoty F-testu, ktorú vracia funkcia FTEST. Funkcia LINEST vracia F-štatistiku, zatiaľ čo funkcia FTEST vracia pravdepodobnosť.
Príklady
Príklad 1 – Smernica a priesečník s osou y
Vzorové údaje skopírujte do nasledujúcej tabuľky a prilepte ich do bunky A1 nového excelového hárka. Ak chcete, aby vzorce zobrazovali výsledky, označte ich, stlačte kláves F2 a potom stlačte kláves Enter. V prípade potreby môžete upraviť šírku stĺpcov, aby sa údaje zobrazovali celé.
|
Známa hodnota y |
Známa hodnota x |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Výsledok (smernica) |
Výsledok (priesečník s osou y) |
|
2 |
1 |
|
Vzorec (vzorec poľa v bunkách A7:B7) |
|
|
=LINEST(A2:A5;B2:B5;;FALSE) |
Príklad 2 – Jednoduchá lineárna regresia
Vzorové údaje skopírujte do nasledujúcej tabuľky a prilepte ich do bunky A1 nového excelového hárka. Ak chcete, aby vzorce zobrazovali výsledky, označte ich, stlačte kláves F2 a potom stlačte kláves Enter. V prípade potreby môžete upraviť šírku stĺpcov, aby sa údaje zobrazovali celé.
|
Mesiac |
Predaj |
|---|---|
|
1 |
3 100 € |
|
2 |
4 500 € |
|
3 |
4 400 € |
|
4 |
5 400 € |
|
5 |
7 500 € |
|
6 |
8 100 € |
|
Vzorec |
Výsledok |
|
=SUM(LINEST(B1:B6; A1:A6)*{9;1}) |
11 000 EUR |
|
Na základe obratu v 1. až 6. mesiaci vypočíta odhadovaný obrat v 9. mesiaci. |
Príklad 3 – Viacnásobná lineárna regresia
Vzorové údaje skopírujte do nasledujúcej tabuľky a prilepte ich do bunky A1 nového excelového hárka. Ak chcete, aby vzorce zobrazovali výsledky, označte ich, stlačte kláves F2 a potom stlačte kláves Enter. V prípade potreby môžete upraviť šírku stĺpcov, aby sa údaje zobrazovali celé.
|
Podlahová plocha (x1) |
Počet kancelárií (x2) |
Počet vchodov (x3) |
Vek (x4) |
Odhadovaná hodnota (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
142 000 EUR |
|
2333 |
2 |
2 |
12 |
144 000 EUR |
|
2356 |
3 |
1,5 |
33 |
151 000 EUR |
|
2379 |
3 |
2 |
43 |
150 000 EUR |
|
2402 |
2 |
3 |
53 |
139 000 EUR |
|
2425 |
4 |
2 |
23 |
169 000 EUR |
|
2448 |
2 |
1,5 |
99 |
126 000 EUR |
|
2471 |
2 |
2 |
34 |
142 900 EUR |
|
2494 |
3 |
3 |
23 |
163 000 EUR |
|
2517 |
4 |
4 |
55 |
169 000 EUR |
|
2540 |
2 |
3 |
22 |
149 000 EUR |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Vzorec (vzorec dynamického poľa zadaný do bunky A19) |
||||
|
=LINEST(E2:E12,A2:D12,TRUE,TRUE) |
Príklad 4 – Používanie štatistík F a r2
V predchádzajúcom príklade je stanovenie koeficientu r2 0,99675 (pozri bunku A17 vo výstupe funkcie LINEST), čo by naznačovalo silný vzťah medzi nezávislými premennými a predajnou cenou. F-štatistika sa môže použiť na určovanie, či nie sú tieto výsledky s takou vysokou hodnotou r2 náhodné.
Predpokladajme, že medzi premennými v skutočnosti neexistuje žiadna závislosť, ale vybrali ste nezvyčajnú vzorku 11 úradných budov, podľa ktorej štatistická analýza naznačuje silnú závislosť. Termín „Alfa“ sa používa na pravdepodobnosť chybného záveru o existencii závislosti.
Hodnoty F a df vo výstupe z funkcie LINEST možno použiť na posúdenie pravdepodobnosti výskytu vyššej hodnoty F náhodou. F možno porovnať s kritickými hodnotami v publikovaných tabuľkách F-rozdelenia alebo funkciu FDIST v Exceli možno použiť na výpočet pravdepodobnosti výskytu väčšej hodnoty F náhodou. Príslušné rozdelenie F má v1 a v2 stupňov voľnosti. Ak n je počet údajových bodov a konštanta = TRUE alebo vynechaný, potom v1 = n – df – 1 a v2 = df. (Ak konštanta = FALSE, potom v1 = n – df a v2 = df.) Funkcia FDIST – so syntaxou FDIST(F,v1,v2) – vráti pravdepodobnosť výskytu vyššej hodnoty F náhodou. V tomto príklade df = 6 (bunka B18) a F = 459,753674 (bunka A18).
Za predpokladu hodnoty alfa 0,05, v1 = 11 – 6 – 1 = 4 a v2 = 6, kritická úroveň F je 4,53. Keďže F = 459,753674 je oveľa vyššia ako 4,53, je veľmi nepravdepodobné, že by sa táto vysoká hodnota F vyskytla náhodou. (Pri alfa = 0,05, hypotéza, že neexistuje žiadny vzťah medzi known_y a known_x sa má odmietnuť, keď F prekročí kritickú úroveň, 4,53.) Funkciu FDIST môžete v Exceli použiť na získanie pravdepodobnosti výskytu tejto vysokej hodnoty F náhodou. Napríklad FDIST(459,753674; 4; 6) = 1,37E-7, čo je mimoriadne malá pravdepodobnosť. Môžete dospieť k záveru, buď vyhľadaním kritickej úrovne F v tabuľke, alebo pomocou funkcie FDIST , že regresná rovnica je užitočná pri predpovedaní hodnote úradných budov v tejto oblasti. Nezabudnite, že je dôležité použiť správne hodnoty v1 a v2, ktoré boli vypočítané v predchádzajúcom odseku.
Príklad 5 – Výpočet t-štatistiky
Iný test štatistickej hypotézy určuje, či sa na odhad hodnoty úradných budov z príkladu číslo 3 vhodná ľubovoľná smernica. Ak napríklad chcete testovať štatistickú významnosť smernice pre „Vek“, vydeľte hodnotu -234,24 (smernica pre vek) číslom 13,268 (odhadovaná štandardná chyba pre smernicu veku v bunke A15). Nasledujúca rovnica udáva pozorovanú hodnotu t:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Ak je absolútna hodnota t dostatočne vysoká, potvrdzuje, že táto smernica je vhodná na určenie odhadovanej hodnoty úradnej budovy v príklade číslo 3. Nasledujúca tabuľka obsahuje absolútne hodnoty štyroch pozorovaných hodnôt t.
Ak sa pozriete do tabuľky v nejakej štatistickej príručke, nájdete v nej, že kritická hodnota t pre obojstranný test so 6 stupňami voľnosti a hodnotou alfa = 0,05 je 2,447. Kritická hodnota sa dá zistiť aj pomocou funkcie TINV v programe Excel. Teda TINV(0,05;6) = 2,447. Keďže absolútna hodnota t (17,7) je väčšia než 2,447, vek bude dôležitou premennou pri odhade hodnoty úradnej budovy. Podobným spôsobom môžete testovať štatistickú významnosť pre každú z nezávislých premenných. Nasledujúca tabuľka uvádza pozorované hodnoty t pre každú nezávislú premennú.
|
Premenná |
Pozorovaná hodnota t |
|---|---|
|
Podlahová plocha |
5,1 |
|
Počet kancelárií |
31,3 |
|
Počet vchodov |
4,8 |
|
Vek |
17,7 |
Všetky tieto hodnoty majú absolútnu hodnotu väčšiu než 2,447 a teda všetky premenné, ktoré sa použili v regresnej rovnici, sú významné pre odhad hodnoty úradných budov v tejto oblasti.









