
Wenn Sie komplexe statistische oder technische Analysen entwickeln müssen, können Sie mit dem AnalysetoolPak Schritte und Zeit sparen. Sie stellen für jede Analyse die Daten und Parameter bereit, und im jeweiligen Tool werden die entsprechenden statistischen oder technischen Makrofunktionen dazu verwendet, die Ergebnisse zu berechnen und in einer Ausgabetabelle anzuzeigen. Von einigen Tools werden zusätzlich zu Ausgabetabellen Diagramme erstellt.
Die Datenanalysefunktionen können immer nur auf jeweils einem Arbeitsblatt verwendet werden. Wenn Sie eine Datenanalyse mit gruppierten Arbeitsblättern ausführen, werden die Ergebnisse auf dem ersten Arbeitsblatt angezeigt, und auf den weiteren Arbeitsblättern werden leere formatierte Tabellen angezeigt. Möchten Sie auf den weiteren Arbeitsblättern Datenanalysen ausführen, führen Sie für jedes Arbeitsblatt eine erneute Berechnung mit dem Analysetool aus.
Die Analyse-Funktionen beinhalten die Tools, die in den folgenden Abschnitten beschrieben sind. Um auf diese Tools zuzugreifen, wählen Sie auf der Registerkarte Daten die Option Datenanalyse aus. Wenn der Befehl Datenanalyse nicht verfügbar ist, müssen Sie das Add-In Analysis ToolPak laden und aktivieren.
Laden und Aktivieren der Analyse-Funktionen
So laden und aktivieren Sie das AnalysetoolPak:
Wechseln Sie in Excel für Mac im Dateimenü zu Extras>Excel-Add-Ins.
In Excel für Windows:
- Wählen Sie Datei, Optionen und dann Add-Ins aus.
- Wählen Sie im Feld Verwaltendie Option Excel-Add-Ins und dann Los aus.
Aktivieren Sie im Feld Add-Ins das Kontrollkästchen AnalysetoolPak , und klicken Sie dann auf OK.
- Wenn Analyse-Funktionen nicht im Feld Verfügbare Add-Ins angezeigt wird, klicken Sie auf Durchsuchen, um danach zu suchen.
- Wenn Sie aufgefordert werden, dass das Analysis ToolPak derzeit nicht auf Ihrem Computer installiert ist, wählen Sie Ja aus, um es zu installieren.
Hinweis
Wenn Sie die VBA-Funktionen (Visual Basic für Applikationen) für die Analyse-Funktionen einbinden möchten, können Sie das Add-In "Analyse-Funktionen - VBA" auf die gleiche Weise wie das Add-In "Analyse-Funktionen" laden. Aktivieren Sie im Feld Verfügbare Add-Ins das Kontrollkästchen Analyse-Funktionen - VBA.
Anova
Die Anova-Analysetools beinhalten unterschiedliche Formen der Varianzanalyse. Welches Tool Sie verwenden sollten, hängt von der Anzahl von Faktoren sowie von der Anzahl von Stichproben ab, die Ihnen zu den Grundgesamtheiten vorliegen, die Sie testen möchten.
Anova: Einfaktorielle Varianzanalyse
Dieses Tool führt eine einfache Analyse der Varianz von Daten für zwei oder mehr Stichproben durch. Die Analyse bietet einen Test der Hypothese, dass jede Stichprobe aus derselben zugrunde liegenden Wahrscheinlichkeitsverteilung gegen die alternative Hypothese gezogen wird, dass die zugrunde liegenden Wahrscheinlichkeitsverteilungen nicht für alle Stichproben identisch sind. Wenn nur zwei Beispiele vorhanden sind, können Sie die Arbeitsblattfunktion T.TEST verwenden. Bei mehr als zwei Stichproben gibt es keine praktische Generalisierung von T.TEST, und stattdessen kann das Single Factor Anova-Modell aufgerufen werden.
Anova: Zweifaktorielle Varianzanalyse mit Messwiederholung
Dieses Analysetool ist von Nutzen, wenn Daten anhand von zwei verschiedenen Dimensionen klassifiziert werden können. In einem Experiment zur Messung der Höhe von Pflanzen können die Pflanzen beispielsweise verschiedene Düngemittelmarken erhalten (z. B. A, B, C), und sie können verschiedenen Temperaturen ausgesetzt werden (z. B. niedrig, hoch). Für jedes der sechs möglichen Paare aus {Düngemittel, Temperatur} liegt die gleiche Anzahl von Beobachtungen der Pflanzenhöhe vor. Mithilfe dieses Anova-Tools kann Folgendes getestet werden:
- Stammt die Höhe der Pflanzen für die verschiedenen Düngemittelmarken aus der gleichen Grundgesamtheit? Temperaturen werden für diese Analyse ignoriert.
- Stammt die Höhe der Pflanzen für die verschiedenen Temperaturniveaus aus der gleichen Grundgesamtheit? Düngemittelmarken werden für diese Analyse ignoriert.
Stammen, nach Berücksichtigung der Auswirkungen der im ersten Stichpunkt gefundenen Unterschiede zwischen den Düngemittelmarken und der im zweiten Stichpunkt gefundenen Temperaturunterschiede, die sechs Stichproben, die alle {Düngemittel, Temperatur}-Wertepaare darstellen, aus derselben Grundgesamtheit? Die alternative Hypothese lautet, dass es abgesehen von den allein auf dem Düngemittel oder allein auf der Temperatur basierenden Unterschieden auch Unterschiede aufgrund bestimmter {Düngemittel, Temperatur}-Paare gibt.

Anova: Zweifaktorielle Varianzanalyse ohne Messwiederholung
Dieses Analysetool ist nützlich, wenn Daten für zwei unterschiedliche Dimensionen, wie im Falle der zweifaktoriellen Varianzanalyse mit Messwiederholung, klassifiziert werden. Für dieses Tool wird allerdings vorausgesetzt, dass für jedes Paar nur eine einzige Beobachtung durchgeführt wird (z. B. jedes {Düngemittel, Temperatur}-Paar im vorangehenden Beispiel).
Korrelation
Sowohl mit der Arbeitsblattfunktion KORREL als auch mit der Arbeitsblattfunktion PEARSON wird der Korrelationskoeffizient berechnet, über den zwei Messwertvariablen zusammenhängen, wenn Messungen zu jeder Variablen für jedes von N Objekten erfasst wurden. (Jede fehlende Beobachtung für ein Subjekt führt dazu, dass dieses Subjekt in der Analyse ignoriert wird.) Das Korrelationsanalysetool ist besonders nützlich, wenn es mehr als zwei Messvariablen für jedes von N Subjekten gibt. Von dem Tool wird eine Ausgabetabelle (eine Korrelationsmatrix) erstellt, in der der Wert von KORREL (oder PEARSON) auf jedes mögliche Paar aus Messwertvariablen angewendet ist.
Der Korrelationskoeffizient ist wie die Kovarianz ein Maß für das Ausmaß, in dem zwei Messvariablen "zusammen variieren". Im Gegensatz zur Kovarianz wird der Korrelationskoeffizient skaliert, sodass sein Wert unabhängig von den Einheiten ist, in denen die beiden Messvariablen ausgedrückt werden. (Wenn die beiden Maßvariablen z. B. Gewicht und Höhe sind, bleibt der Wert des Korrelationskoeffizienten unverändert, wenn das Gewicht von Pfund in Kilogramm konvertiert wird.) Der Wert eines Korrelationskoeffizienten muss zwischen -1 und +1 einschließlich liegen.
Sie können das Analysetool zur Berechnung der Korrelation verwenden, um jedes Paar von Messwertvariablen zu untersuchen und um bestimmen zu können, ob sich die beiden Messwertvariablen tendenziell gleich entwickeln, d. h., ob hohe Werte der einen Variable tendenziell hohen Werten der anderen zugeordnet sind (positive Korrelation), ob niedrige Werte der einen Variable tendenziell hohen Werten der anderen zugeordnet sind (negative Korrelation) oder ob die Werte der beiden Variablen einander nicht zugeordnet sind (Korrelation nahe 0 (Null)).
Kovarianz
Die Tools zur Berechnung der Korrelation und der Kovarianz können beide in derselben Einstellung verwendet werden, wenn N verschiedene Messwertvariablen in einer Gruppe von Einzelwerten beobachtet wurden. Die Tools zur Berechnung der Korrelation und der Kovarianz liefern jeweils eine Ausgabetabelle (eine Matrix) die den Korrelationskoeffizienten bzw. die Kovarianz zwischen jedem Paar von Messwertvariablen zeigt. Der Unterschied liegt darin, dass Korrelationskoeffizienten skaliert werden, sodass sie zwischen -1 und +1 (einschließlich) liegen, während die entsprechenden Kovarianzen nicht skaliert werden. Sowohl der Korrelationskoeffizient als auch die Kovarianz geben an, inwieweit zwei Variablen "gemeinsam variieren".
Das Kovarianztool berechnet den Wert der Arbeitsblattfunktion COVARIANCE. P für jedes Paar von Messvariablen. (Direkte Verwendung von KOVARIANZ. P anstelle des Kovarianztools ist eine sinnvolle Alternative, wenn nur zwei Messvariablen vorhanden sind, d. h. N=2.) Der Eintrag auf der Diagonalen der Ausgabetabelle des Kovarianztools in Zeile i, Spalte i ist die Kovarianz der i-ten Maßvarianz mit sich selbst. Dies ist nur die Auffüllungsvarianz für diese Variable, die von der Arbeitsblattfunktion VAR.P berechnet wird.
Mithilfe des Tools zur Berechnung der Kovarianz können Sie jedes Paar von Messwertvariablen untersuchen, um zu bestimmen, ob die beiden Messwertvariablen tendenziell miteinander verbunden sind, d. h., ob hohe Werte der einen Variable tendenziell den hohen Werten der anderen zugeordnet sind (positive Kovarianz), ob niedrige Werte der einen Variable tendenziell den hohen Werten der anderen zugeordnet sind (negative Kovarianz) oder ob die Werte der beiden Variablen einander nicht zugeordnet sind (Kovarianz nahe 0 (Null)).
Populationskenngrößen
Dieses Analysetool generiert einen Bericht über eindimensionale (univariate) Statistiken für Daten im Eingabebereich. In dem Bericht werden Informationen über die zentrale Tendenz und Streuung der Daten bereitgestellt.
Exponentielles Glätten
Mit diesem Analysetool wird ein Wert vorhergesagt, der auf der Prognose für die vorherige Periode basiert, wobei der in der vorherigen Prognose enthaltene Fehler berücksichtigt wird. In diesem Tool wird die Glättungskonstante a verwendet, deren Größe bestimmt, wie stark die aktuelle Prognose durch Fehler in der vorherigen Prognose beeinflusst wird.
Hinweis
Sinnvolle Glättungskonstanten liegen zwischen 0,2 und 0,3. Diese Werte zeigen an, dass die aktuelle Prognose um 20 % bis 30 % für den Fehler aus der vorherigen Prognose angepasst werden sollte. Größere Konstanten führen zwar zu schnelleren Reaktionen, können allerdings auch zu fehlerhaften Vorhersagen führen. Kleinere Konstanten bewirken möglicherweise, dass die Prognosewerte weit hinter den tatsächlichen zurückliegen.
Zwei-Stichproben F-Test
Mit diesem Analysetool wird ein Zwei-Stichproben F-Test ausgeführt, um die Varianzen zweier Grundgesamtheiten zu vergleichen.
Sie können das F-Test-Tool z. B. für Stichproben der von zwei Mannschaften bei einem Schwimmwettkampf erzielten Zeiten verwenden. Das Tool liefert das Ergebnis eines Tests der Nullhypothese, dass diese beiden Stichproben aus Verteilungen mit gleichen Varianzen stammen, gegenüber der alternativen Hypothese, dass die Varianzen in den zugrunde liegenden Verteilungen nicht gleich sind.
In dem Tool wird der Wert f einer F-Statistik (oder F-Verhältnis) berechnet. Ein f-Wert nahe 1 beweist, dass die Varianzen der Grundgesamtheiten gleich sind. Wenn in der Ausgabetabelle f1 < "P(F <= f) one-tail" die Wahrscheinlichkeit angibt, einen Wert der F-Statistik kleiner als f zu beobachten, wenn die Populationsabweichungen gleich sind, und "F Critical one-tail" gibt den kritischen Wert kleiner als 1 für die ausgewählte Signifikanzstufe Alpha an. Wenn f1 > , gibt "P(F <= f) one-tail" die Wahrscheinlichkeit an, einen Wert der F-Statistik größer als f zu beobachten, wenn die Populationsabweichungen gleich sind, und "F Critical one-tail" gibt den kritischen Wert größer als 1 für Alpha an.
Fourieranalyse
Mit der Fourieranalyse ist es möglich, Probleme in linearen Systemen zu lösen und periodische Daten mithilfe der Schnellen Fouriertransformation (Fast Fourier Transform oder FFT) zu analysieren. Dieses Tool unterstützt auch umgekehrte Transformationen, bei denen die Umkehrung der transformierten Daten die ursprünglichen Daten zurückgibt.

Histogramm
Mit diesem Analysetool können einzelne und kumulierte Häufigkeiten für einen Zellbereich von Daten und Klassen berechnet werden. Das Tool generiert Daten über die Häufigkeit eines Werts in einer Datenmenge.
Für einen Kurs mit 20 Teilnehmern können Sie z. B. die Verteilung der Punkte in den Bewertungskategorien bestimmen. In einer Histogrammtabelle werden die Bewertungsgrenzen und die Punktzahlen zwischen der untersten und der aktuellen Begrenzung dargestellt. Die häufigste Punktzahl gibt den Modalwert für die Daten an.
Tipp
In Excel 2016 können Sie jetzt ein Histogramm oder ein Pareto-Diagramm erstellen.
Gleitender Durchschnitt
Mithilfe dieses Analysetools werden Werte in den Prognosezeitraum projiziert, die auf dem Mittelwert der Variablen für eine bestimmte Anzahl von vorhergehenden Zeiträumen basieren. Der gleitende Durchschnitt stellt Trendinformationen bereit, die aus einem einfachen Durchschnitt aller früheren Daten nicht erkennbar sind. Verwenden Sie dieses Tool z. B. für Verkaufs- und Lagerhaltungsprognosen. Die Prognosewerte basieren auf der folgenden Formel.

Wobei:
- N ist die Anzahl von vorherigen Zeiträumen, die in den gleitenden Durchschnitt einbezogen werden sollen.
- Aj ist der tatsächliche Wert zum Zeitpunkt j
- Fj ist der prognostizierte Wert zum Zeitpunkt j
Zufallszahlengenerierung
Bei diesem Analysetool wird ein Bereich mit unabhängigen Zufallszahlen gefüllt, die einer von mehreren Verteilungen entnommen werden. Sie können die Objekte in einer Grundgesamtheit mit einer Wahrscheinlichkeitsverteilung charakterisieren. Sie können z. B. mithilfe einer Normalverteilung die Grundgesamtheit der Körpergrößen von Personen oder mit einer Bernoulli-Verteilung mit zwei möglichen Ergebnissen die Grundgesamtheit der Ergebnisse beim Werfen einer Münze charakterisieren.
Rang und Quantil
Das Analysetool Rang und Perzentil erzeugt eine Tabelle, die die Ordnungszahl und den Prozentsatz der einzelnen Werte in einem Dataset enthält. Sie können die relative Position von Werten in einem Dataset analysieren. Dieses Tool verwendet die Arbeitsblattfunktionen RANK. EQ und PERCENTRANK. INC. Wenn Sie gebundene Werte berücksichtigen möchten, verwenden Sie rangieren. EQ-Funktion , die verknüpfte Werte so behandelt, dass sie denselben Rang haben, oder die RANK-Funktion verwendet. AVG-Funktion , die den durchschnittlichen Rang für die gebundenen Werte zurückgibt.
Regression
Das Regressionsanalysetool führt lineare Regressionsanalysen nach der Methode der "kleinsten Quadrate" aus, um eine Gerade an eine Reihe von Beobachtungen anzupassen. Sie können analysieren, welchen Einfluss die Werte einer oder mehrerer unabhängiger Variablen auf eine einzelne abhängige Variable haben. So können Sie beispielsweise analysieren, inwieweit bestimmte Faktoren wie Alter, Größe und Gewicht die Leistungsfähigkeit eines Athleten oder einer Athletin beeinflussen. Basierend auf einer Reihe von Leistungsdaten können Sie in der Leistungsmessung jedem dieser drei Faktoren Anteile zuweisen und die Ergebnisse dazu verwenden, die Leistung eines neuen Athleten oder einer neuen Athletin, die noch nicht getestet wurde, vorherzusagen.
Das Regressionstool verwendet die Arbeitsblattfunktion LINEST.
Stichprobenziehung
Von diesem Analysetool wird eine Stichprobe aus einer Grundgesamtheit erstellt, indem der Eingabebereich als Grundgesamtheit angesehen wird. Wenn die Grundgesamtheit zu groß ist, um sie zu verarbeiten oder grafisch darzustellen, können Sie eine repräsentative Stichprobe verwenden. Falls zu erwarten ist, dass die Eingabedaten periodisch sind, können Sie eine Stichprobe erstellen, die nur die Werte aus einem bestimmten Teil eines Zyklus enthält. Enthält der Eingabebereich z. B. Quartalsumsätze, so werden durch das Erstellen einer Stichprobe mit der periodischen Häufigkeit 4 die Werte aus demselben Quartal im Ausgabebereich platziert.
t-Test
Mit den Analysetools für Zwei-Stichproben t-Tests wird ein Test auf Gleichheit der jeder Stichprobe zugrunde liegenden Erwartungswerte der Zufallsvariablen durchgeführt. Die drei Tools basieren auf verschiedenen Annahmen: dass die Varianzen der Grundgesamtheiten gleich sind, dass die Varianzen der Grundgesamtheiten nicht gleich sind und dass die beiden Stichproben Beobachtungen vor und nach der Behandlung derselben Objekte darstellen.
Bei allen drei folgenden Tools wird ein t-Statistik-Wert t berechnet und als t-Statistik in den Ausgabetabellen angezeigt. Abhängig von den Daten kann dieser Wert t negativ oder nicht negativ sein. Wenn t < 0 gleich ist, gibt "P(T <= t) one-tail" die Wahrscheinlichkeit, dass ein Wert der t-Statistik beobachtet wird, der negativer als t ist. Wenn t >=0, gibt "P(T <= t) one-tail" die Wahrscheinlichkeit an, dass ein Wert der t-Statistik beobachtet wird, der positiver als t ist. "Kritischer t-Wert bei einseitigem Test" gibt den maximalen Wert an, sodass die Wahrscheinlichkeit, dass ein Wert der t-Statistik größer oder gleich "Kritischer t-Wert bei einseitigem Test" ist, Alpha entspricht.
"P(T <= t) two-tail" gibt die Wahrscheinlichkeit an, dass ein Wert der t-Statistik beobachtet wird, der im absoluten Wert größer als t ist. "Kritischer P-Wert bei zweiseitigem t-Test" gibt den maximalen Wert an, sodass die Wahrscheinlichkeit eines beobachteten Werts der t-Statistik, dessen Absolutwert größer als "Kritischer P-Wert bei zweiseitigem t-Test" ist, Alpha entspricht.
Zwei-Stichproben t-Test bei abhängigen Stichproben
Sie können einen Paarvergleichstest verwenden, wenn Stichproben zweimal durchgeführt werden, z. B. wenn eine Stichprobengruppe sowohl vor als auch nach einem Experiment getestet wird. Mit diesem Analysetool und der zugehörigen Formel wird ein Studentscher t-Test mit zwei Stichproben ausgeführt, um zu bestimmen, ob vor einer Behandlung durchgeführte Beobachtungen und nach einer Behandlung durchgeführte Beobachtungen aus Verteilungen mit gleichen Erwartungswerten der Zufallsvariablen stammen könnten. Für diese Form des t-Tests wird nicht angenommen, dass die Varianzen der beiden Grundgesamtheiten gleich sind.
Hinweis
Zu den von dieser Funktion generierten Ergebnissen gehört auch die gepoolte Varianz, die ein akkumuliertes Maß für die Abweichung der Daten vom Mittelwert ist. Die gepoolte Varianz wird nach der folgenden Formel berechnet.

Zwei-Stichproben t-Test: Gleicher Varianzen
In diesem Analysetool wird ein t-Test für zwei Stichproben ausgeführt. Bei diesem Test wird davon ausgegangen, dass die beiden Datenmengen aus Verteilungen mit gleichen Varianzen stammen. Er wird als homoskedastischer t-Test bezeichnet. Mithilfe dieses t-Tests können Sie bestimmen, ob die beiden Stichproben wahrscheinlich aus Verteilungen mit gleichen Erwartungswerten der Zufallsvariablen stammen.
Zwei-Stichproben t-Test: Unterschiedlicher Varianzen
In diesem Analysetool wird ein t-Test für zwei Stichproben ausgeführt. Für diesen Test wird davon ausgegangen, dass die beiden Datensätze aus Verteilungen mit ungleichen Varianzen stammen. Er wird als heteroskedastischer t-Test bezeichnet. Wie beim zuvor beschriebenen t-Test mit gleichen Varianzen können Sie mithilfe dieses t-Tests bestimmen, ob die beiden Stichproben wahrscheinlich aus Verteilungen mit gleichen Erwartungswerten der Zufallsvariablen stammen. Verwenden Sie diesen Test, wenn in den beiden Stichproben unterschiedliche Objekte vorliegen. Verwenden Sie den im folgenden Beispiel beschriebenen Paarvergleichstest, wenn eine einzige Objektgruppe vorliegt und die beiden Stichproben Messungen für jedes Objekt vor und nach einer Behandlung darstellen.
Folgende Formel wird zur Bestimmung des Statistikwerts t verwendet.

Die folgende Formel wird verwendet, um die Freiheitsgrade df zu berechnen. Da das Ergebnis der Berechnung in der Regel keine ganze Zahl ist, wird der Wert von df auf die nächste ganze Zahl gerundet, um einen kritischen Wert aus der t-Tabelle zu erhalten. Die Excel-Arbeitsblattfunktion T.TEST verwendet den berechneten df-Wert ohne Rundung, da es möglich ist, einen Wert für T.TEST mit einem nicht integer df zu berechnen. Aufgrund dieser unterschiedlichen Ansätze zur Bestimmung der Freiheitsgrade unterscheiden sich die Ergebnisse von T.TEST und diesem t-Test-Tool im Fall ungleicher Varianzen.
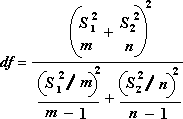
Gaußtest
Das Analysetool z-Test: Two Sample for Means führt einen Z-Test mit zwei Stichproben für Mittel mit bekannten Varianzen durch. Dieses Tool wird verwendet, um die NULL-Hypothese zu testen, dass es keinen Unterschied zwischen zwei Auffüllungsmitteln gegen einseitige oder zweiseitige alternative Hypothesen gibt. Wenn Varianzen nicht bekannt sind, sollte stattdessen die Arbeitsblattfunktion Z.TEST verwendet werden.
Bei der Verwendung des Gaußtesttools sollte besonders auf die richtige Interpretation der Ausgabe geachtet werden. "P(Z <= z) one-tail" ist wirklich P(Z >= ABS(z)), die Wahrscheinlichkeit eines Z-Werts weiter von 0 in der gleichen Richtung wie der beobachtete z-Wert, wenn es keinen Unterschied zwischen den Auffüllungsmitteln gibt. "P(Z <= z) two-tail" ist wirklich P(Z >= ABS(z) oder Z <= -ABS(z)), die Wahrscheinlichkeit eines Z-Werts, der weiter von 0 in beide Richtungen liegt als der beobachtete Z-Wert, wenn es keinen Unterschied zwischen den Grundgesamtheitswerten gibt. Das zweiseitige Ergebnis ist lediglich das mit 2 multiplizierte einseitige Ergebnis. Das Gaußtesttool kann auch für den Fall verwendet werden, wenn die Nullhypothese besagt, dass es einen bestimmten Wert ungleich Null für die Differenz zwischen den Erwartungswerten zweier Zufallsvariablen gibt. Sie können diesen Test z. B. verwenden, um die Unterschiede in der Leistung zweier Kraftfahrzeugtypen zu bestimmen
Benötigen Sie weitere Hilfe?
Sie können jederzeit einen Experten in der Excel Tech Community fragen oder Unterstützung in Communitys erhalten.
Siehe auch
Erstellen eines Histogramms in Excel 2016
Erstellen eines Pareto-Diagramms in Excel 2016
Laden des Analysetools in Excel
ENGINEERING-Funktionen (Referenz)
Übersicht über Formeln in Excel
Suchen und Beheben von Fehlern in Formeln
Excel-Tastenkombinationen und -Funktionstasten