
In dit artikel worden de syntaxis van de formule en het gebruik van de functie LIJNENT in Microsoft Excel beschreven.
Beschrijving
Met de functie LIJNSCH berekent u de grootheden voor een lijn met de methode van de kleinste kwadraten om een rechte lijn te berekenen die het beste past bij uw gegevens, en wordt als resultaat een matrix gegeven die de lijn beschrijft. U kunt de functie LIJNSCH ook combineren met andere functies en zo de statistische gegevens voor andere typen modellen berekenen die lineaire modellen in de onbekende parameters zijn, waaronder machtreeksen en polynomiale, logaritmische en exponentiële reeksen. Omdat deze functie een matrix met waarden als resultaat geeft, moet de functie worden ingevoerd als een matrixformule. Instructies vindt u na de voorbeelden in dit artikel.
De vergelijking voor de lijn luidt als volgt:
y = mx + b
-of-
y = m1x1 + m2x2 + ... + b
als er meerdere bereiken van x-waarden zijn, waarbij de afhankelijke y-waarden een functie zijn van de onafhankelijke x-waarden. De m-waarden zijn coëfficiënten die corresponderen met de x-waarden en b is een constante. Let erop dat y, x en m vectoren kunnen zijn. Het resultaat van de functie LIJNSCH is {mn,mn-1,...,m1,b}. Met de functie LIJNSCH kunt u ook aanvullende regressiegrootheden berekenen.
Syntaxis
LIJNSCH(y-bekend;[x-bekend];[const];[stat])
De syntaxis van de functie LIJNSCH heeft de volgende argumenten:
Syntaxis
-
y-bekend Vereist. De reeks y-waarden die u al kent uit de relatie y = mx + b.
-
Als het bereik van y-bekend één kolom is, wordt elke kolom van x-bekend als een afzonderlijke variabele beschouwd.
-
Als het bereik van y-bekend één rij is, wordt elke rij van x-bekend als een afzonderlijke variabele beschouwd.
-
-
x-bekend Optioneel. Een optionele reeks x-waarden die u wellicht al kent uit de relatie y = mx + b.
-
Het bereik van x-bekend kan een of meer reeksen variabelen bevatten. Als slechts één variabele wordt gebruikt kunnen y-bekend en x-bekend bereiken met een willekeurige vorm zijn, mits deze dezelfde dimensie hebben. Als meerdere variabelen zijn gebruikt, moet y-bekend een vector zijn (dat wil zeggen een bereik van één rij hoog of één kolom breed).
-
Als u x-bekend weglaat, wordt uitgegaan van de matrix {1;2;3;...} met dezelfde afmetingen als y-bekend.
-
-
const Optioneel. Een logische waarde die aangeeft of de constante b gelijkgesteld moet worden aan nul.
-
Als const WAAR is of wordt weggelaten, wordt b op de normale wijze berekend.
-
Als const ONWAAR is, krijgt b de waarde 0 en worden de m-waarden zodanig aangepast dat geldt y = mx.
-
-
stat Optioneel. Een logische waarde die aangeeft of als resultaat ook aanvullende regressiegrootheden moeten worden gegeven.
-
Als statistieken WAAR is, retourneert LINEST de aanvullende regressiestatistieken; als gevolg hiervan is de geretourneerde matrix {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; r2,sey; F,df; ssreg,ssresid}.
-
Als stat ONWAAR is of wordt weggelaten, retourneert LIJNSCH alleen de m-coëfficiënten en de constante b.
In de volgende tabel vindt u een overzicht van de aanvullende regressiegrootheden.
-
|
Regressiegrootheid |
Beschrijving |
|---|---|
|
sa1,sa2,...,san |
De standaardfoutwaarden voor de coëfficiënten m1,m2,...,mn. |
|
sab |
De standaardfoutwaarden voor de constante b (sab = #N/B als const ONWAAR is). |
|
r2 |
Het kwadraat van de correlatiecoëfficiënt. Dit geeft aan hoe de geschatte en de feitelijke y-waarden zich tot elkaar verhouden en drukt deze verhouding uit in een waarde tussen 0 en 1. Als het kwadraat van de correlatiecoëfficiënt 1 bedraagt, is er sprake van perfecte correlatie in de steekproef en is er geen verschil tussen de geschatte y-waarde en de feitelijke y-waarde. Als het kwadraat van de correlatiecoëfficiënt echter 0 is, biedt de regressievergelijking geen goede methode om de y-waarden te voorspellen. Zie 'Opmerkingen' verderop in dit onderwerp voor meer informatie over hoe2 wordt berekend. |
|
Say |
Dit is de standaardfout voor de schatting van de y-waarde. |
|
F |
De toetsingsgrootheid F of de waargenomen F-waarde. Met deze waarde kunt u bepalen in hoeverre de waargenomen relatie tussen de afhankelijke en de onafhankelijke variabelen op toeval berust. |
|
Vg |
De vrijheidsgraden. Aan de hand van de vrijheidsgraden kunt u in een statistische tabel de kritieke F-waarde vinden. Vergelijk de waarden uit de tabel met de F-waarde die het resultaat is van LIJNSCH om het betrouwbaarheidsniveau van het model te bepalen. Zie 'Opmerkingen' verderop in dit onderwerp voor informatie over de wijze waarop vg wordt berekend. In voorbeeld 4 hieronder ziet u hoe F en vg worden gebruikt. |
|
Ksreg |
De regressieve som van de kwadraten. |
|
Ksresid |
De residuele som van kwadraten. Zie 'Opmerkingen' verderop in dit onderwerp voor informatie over de wijze waarop ksreg en ksresid worden berekend. |
In de volgende afbeelding ziet u de volgorde waarin de aanvullende regressiegrootheden worden weergegeven.

Opmerkingen
-
Elke rechte lijn kan worden beschreven aan de hand van een richtingscoëfficiënt en een snijpunt met de y-as.
Helling (m):
Als u de helling van een lijn wilt vinden, vaak geschreven als m, neemt u twee punten op de lijn, (x1,y1) en (x2,y2); de helling is gelijk aan (y2 - y1)/(x2 - x1).Y-snijpunt (b):
De y-snijpunt van een lijn, vaak geschreven als b, is de waarde van y op het punt waar de lijn de y-as kruist.De vergelijking voor een rechte lijn is y = mx + b. Als u de waarden voor m en b kent, kunt u elk punt op die lijn berekenen door de x- of de y-waarde in te vullen. U kunt ook de functie TREND gebruiken.
-
Als er slechts één onafhankelijke x-variabele is, kunt u de richtingscoëfficiënt en het snijpunt met de y-as met de volgende formules berekenen.
Helling:
=INDEX(LINEST(known_y;known_x),1)Y-snijpunt:
=INDEX(LINEST(known_y;known_x),2) -
De nauwkeurigheid van de lijn die u hebt berekend met de functie LIJNSCH is afhankelijk van de mate van spreiding in de gebruikte gegevens. Hoe meer de grafische weergave van uw gegevens een rechte lijn benadert, des te nauwkeuriger is de vergelijking die door LIJNSCH wordt berekend. LIJNSCH maakt gebruik van de 'kleinste kwadraten'-methode voor het berekenen van de lijn die het beste past bij de gegevens. Als er slechts één onafhankelijke x-variabele is, kunt u m en b met de volgende formules berekenen:
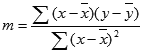
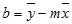
waarbij x en y steekproefgemiddelden zijn, d.w.z. x = GEMIDDELDE(x-bekend) en y = GEMIDDELDE(y-bekend).
-
De lijn- en curve-passende functies LINEST en LOGEST kunnen de beste rechte lijn of exponentiële curve berekenen die bij uw gegevens past. U moet echter beslissen welke van de twee resultaten het beste bij uw gegevens past. U kunt TREND(known_y,known_x) berekenen voor een rechte lijn of GROEI(known_y, known_x) voor een exponentiële curve. Deze functies retourneren, zonder het argument van het new_x , een matrix met y-waarden die langs die lijn of curve zijn voorspeld op uw werkelijke gegevenspunten. Vervolgens kunt u de voorspelde waarden vergelijken met de werkelijke waarden. U kunt ze beide in kaart brengen voor een visuele vergelijking.
-
In regressieanalyse berekent Excel voor elk punt het kwadratische verschil tussen de geschatte y-waarde voor dat punt en de werkelijke y-waarde. De som van deze kwadratische verschillen wordt de resterende som van kwadraten genoemd, ssresid. Excel berekent vervolgens de totale som van kwadraten, sstotaal. Wanneer het argument const = TRUE of wordt weggelaten, is de totale som van kwadraten de som van de kwadratische verschillen tussen de werkelijke y-waarden en het gemiddelde van de y-waarden. Wanneer het argument const = ONWAAR is, is de totale som van kwadraten de som van de kwadraten van de werkelijke y-waarden (zonder de gemiddelde y-waarde af te trekken van elke afzonderlijke y-waarde). Vervolgens kan de regressiesom van kwadraten, ssreg, worden gevonden uit: ssreg = sstotal - ssresid. Hoe kleiner de resterende som van kwadraten is, vergeleken met de totale som van kwadraten, hoe groter de waarde van de bepalingscoëfficiënt, r2, die een indicator is van hoe goed de vergelijking die het resultaat is van de regressieanalyse de relatie tussen de variabelen verklaart. De waarde van r2 is gelijk aan ssreg/sstotaal.
-
In sommige gevallen hebben een of meer van de X-kolommen (ervan uitgaande dat Y's en X's zich in kolommen bevinden) geen extra voorspellende waarde in de aanwezigheid van de andere X-kolommen. Met andere woorden, het elimineren van een of meer X-kolommen kan leiden tot voorspelde Y-waarden die even nauwkeurig zijn. In dat geval moeten deze redundante X-kolommen worden weggelaten uit het regressiemodel. Dit fenomeen wordt 'collineariteit' genoemd, omdat elke redundante X-kolom kan worden uitgedrukt als een som van veelvouden van de niet-redundante X-kolommen. De functie LINEST controleert op collineariteit en verwijdert overbodige X-kolommen uit het regressiemodel wanneer deze worden geïdentificeerd. Verwijderde X-kolommen kunnen in DE LIJNT-uitvoer worden herkend als met 0 coëfficiënten naast 0 se-waarden. Als een of meer kolommen als redundant worden verwijderd, wordt df beïnvloed omdat df afhankelijk is van het aantal X-kolommen dat daadwerkelijk wordt gebruikt voor voorspellende doeleinden. Zie Voorbeeld 4 voor meer informatie over de berekening van df. Als df wordt gewijzigd omdat redundante X-kolommen worden verwijderd, worden de waarden van sey en F ook beïnvloed. Collineariteit zou in de praktijk relatief zeldzaam moeten zijn. Een geval waarin dit echter waarschijnlijker is, is wanneer sommige X-kolommen slechts 0- en 1-waarden bevatten als indicatoren of een onderwerp in een experiment al dan niet lid is van een bepaalde groep. Als const = WAAR of wordt weggelaten, voegt de functie LIJNENT effectief een extra X-kolom van alle 1-waarden in om het snijpunt te modelleren. Als u een kolom hebt met een 1 voor elk onderwerp als dat niet het geval is, of 0 als dat niet het geval is, en u hebt ook een kolom met een 1 voor elk onderwerp als vrouw, of 0 als dat niet het geval is, is deze laatste kolom overbodig omdat vermeldingen erin kunnen worden verkregen door de vermelding in de kolom 'mannelijke indicator' af te trekken van de vermelding in de extra kolom van alle 1 waarden die door de functie LIJNENT zijn toegevoegd.
-
De waarde van vg wordt als volgt berekend wanneer geen X-kolommen uit het model worden verwijderd vanwege collineariteit: als er k kolommen zijn van x-bekend en const = WAAR of is weggelaten, dan vg = n – k – 1. Als const = ONWAAR, dan vg = n - k. In beide gevallen verhoogt elke kolom die vanwege collineariteit is verwijderd vg met 1.
-
Bij het invoeren van een matrixconstante (bijvoorbeeld x-bekend) als argument gebruikt u puntkomma's om waarden in dezelfde rij van elkaar te scheiden en backslashes om rijen van elkaar te scheiden. Afhankelijk van uw landinstelling kunnen er andere scheidingstekens worden gebruikt.
-
Houd er rekening mee dat y-waarden die met een regressievergelijking zijn voorspeld, onjuist kunnen zijn als deze buiten het bereik van de y-waarden vallen dat u hebt gebruikt bij het bepalen van de vergelijking.
-
De onderliggende algoritme van de functies RICHTING en SNIJPUNT is anders dan die van de functie LIJNSCH. Het verschil tussen beide algoritmen kan tot verschillende resultaten leiden voor onbepaalde en collineaire gegevens. Wanneer het argument y-bekend bijvoorbeeld 0 gegevenspunten heeft en x-bekend 1 gegevenspunt, gebeurt het volgende:
-
LIJNSCH retourneert een waarde van 0. De algoritme van de functie LIJNSCH is ontworpen voor het retourneren van redelijke resultaten van collineaire gegevens, en in dit geval kan er ten minste één antwoord worden gevonden.
-
HELLING en SNIJPUNT retourneren een #DIV/0! fout. Het algoritme van de functies SLOPE en INTERCEPT is ontworpen om slechts één antwoord te zoeken, en in dit geval kan er meer dan één antwoord zijn.
-
-
Behalve dat u met de functie LOGSCH statistische gegevens voor andere regressietypen kunt berekenen, kunt u met de functie LIJNSCH een bereik van andere regressietypen berekenen door functies van de x- en y-variabelen als x- en y-reeksen voor LIJNSCH in te voeren. De volgende formule
=LIJNSCH(ywaarden, xwaarden^KOLOM($A:$C))
werkt wanneer u met een enkele kolom van y-waarden en een enkele kolom van x-waarden de kubieke (polynomiale rangorde 3) benadering in de volgende vorm berekent:
y = m1*x + m2*x^2 + m3*x^3 + b
U kunt de formule wijzigen om andere typen regressie te berekenen, maar in sommige gevallen moeten de uitkomstwaarden en andere statistieken worden aangepast.
-
De F-toetswaarde die het resultaat is van de functie LIJNSCH, verschilt van de F-toetswaarde die het resultaat is van de functie F.TOETS. LIJNSCH geeft de F-statistiek als resultaat, terwijl F.TOETS de kans als resultaat geeft.
Voorbeelden
Voorbeeld 1: Richtingscoëfficiënt en snijpunt met y-as
Kopieer de voorbeeldgegevens uit de volgende tabel en plak deze in cel A1 van een nieuw Excel-werkblad. Om resultaten van formules weer te geven, selecteert u deze, drukt u op F2 en drukt u vervolgens op Enter. Indien nodig kunt u de kolombreedten aanpassen als u alle gegevens wilt zien.
|
Y-bekend |
X-bekend |
|---|---|
|
1 |
0 |
|
9 |
4 |
|
5 |
2 |
|
7 |
3 |
|
Resultaat (richtingscoëfficiënt) |
Resultaat (snijpunt met y-as) |
|
2 |
1 |
|
Formule (matrixformule in cellen A7:B7) |
|
|
=LIJNSCH(A2:A5;B2:B5;ONWAAR) |
Voorbeeld 2: Enkelvoudige lineaire regressie
Kopieer de voorbeeldgegevens uit de volgende tabel en plak deze in cel A1 van een nieuw Excel-werkblad. Om resultaten van formules weer te geven, selecteert u deze, drukt u op F2 en drukt u vervolgens op Enter. Indien nodig kunt u de kolombreedten aanpassen als u alle gegevens wilt zien.
|
Maand |
Verkoop |
|---|---|
|
1 |
€ 3.100 |
|
2 |
€ 4.500 |
|
3 |
€ 4.400 |
|
4 |
€ 5.400 |
|
5 |
€ 7.500 |
|
6 |
€ 8.100 |
|
Formule |
Resultaat |
|
=SOM(LIJNSCH(B1:B6, A1:A6)*{9,1}) |
€ 11.000 |
|
Berekening van de verwachte verkopen in maand negen op basis van de verkopen in maand 1 tot en met 6. |
Voorbeeld 3: Meervoudige lineaire regressie
Kopieer de voorbeeldgegevens uit de volgende tabel en plak deze in cel A1 van een nieuw Excel-werkblad. Om resultaten van formules weer te geven, selecteert u deze, drukt u op F2 en drukt u vervolgens op Enter. Desgewenst kunt u de kolombreedte wijzigen om alle gegevens te zien.
|
Vloeroppervlak (x1) |
Kantoren (x2) |
Ingangen (x3) |
Ouderdom (x4) |
Geschatte waarde (y) |
|---|---|---|---|---|
|
2310 |
2 |
2 |
20 |
€ 142.000 |
|
2333 |
2 |
2 |
12 |
€ 144.000 |
|
2356 |
3 |
1,5 |
33 |
€ 151.000 |
|
2379 |
3 |
2 |
43 |
€ 150.000 |
|
2402 |
2 |
3 |
53 |
€ 139.000 |
|
2425 |
4 |
2 |
23 |
€ 169.000 |
|
2448 |
2 |
1,5 |
99 |
€ 126.000 |
|
2471 |
2 |
2 |
34 |
€ 142.900 |
|
2494 |
3 |
3 |
23 |
€ 163.000 |
|
2517 |
4 |
4 |
55 |
€ 169.000 |
|
2540 |
2 |
3 |
22 |
€ 149.000 |
|
-234,2371645 |
||||
|
13,26801148 |
||||
|
0,996747993 |
||||
|
459,7536742 |
||||
|
1732393319 |
||||
|
Formule (dynamische matrixformule ingevoerd in A19) |
||||
|
=LIJNSCH(E2:E12;A2:D12;WAAR;WAAR) |
Voorbeeld 4: de statistieken F en r2 gebruiken
In het voorgaande voorbeeld is de bepalingscoëfficiënt, of r2, 0,99675 (zie cel A17 in de uitvoer voor LINEST), wat een sterke relatie tussen de onafhankelijke variabelen en de verkoopprijs zou aangeven. U kunt de F-statistiek gebruiken om te bepalen of deze resultaten, met zo'n hoge r2-waarde, toevallig zijn opgetreden.
Ga er voor het moment van uit dat er in feite geen verband bestaat tussen de variabelen, maar dat u bij toeval een steekproef hebt getrokken van 11 kantoorgebouwen die tot gevolg heeft dat de statistische analyse een sterk verband aantoont. De term 'alfa' wordt gebruikt voor het risico dat men op verkeerde gronden aanneemt dat er een verband bestaat.
Met de waarden F en vg in de uitvoer van LIJNSCH kunt u bepalen hoe waarschijnlijk het is dat een hogere F-waarde toevallig voorkomt. F kan worden vergeleken met kritische waarden in gepubliceerde F-verdelingstabellen of de functie F.VERDELING van Excel kan worden gebruikt om de kans te berekenen dat een grotere F-waarde toevallig voorkomt. De juiste F-verdeling heeft v1 en v2 vrijheidsgraden. Als n het aantal gegevenspunten is en const = WAAR of is weggelaten, dan v1 = n – vg – 1 en v2 = vg. (Als const = ONWAAR, dan v1 = n – vg en v2 = vg.) De functie F.VERDELING, met de syntaxis F.VERDELING(F,v1,v2), geeft als resultaat de kans dat een hogere F-waarde bij toeval voorkomt. In dit voorbeeld geldt het volgende: vg = 6 (cel B18) en F = 459,753674 (cel A18).
Uitgaande van een Alfa-waarde van 0,05, v1 = 11 – 6 – 1 = 4 en v2 = 6, is het kritische niveau van F 4,53. Aangezien F = 459,753674 veel hoger is dan 4,53, is het zeer onwaarschijnlijk dat zo'n hoge F-waarde toevallig voorkomt. (Met Alfa = 0,05 moet de hypothese dat er geen relatie is tussen y-bekend en x-bekend worden verworpen wanneer F het kritische niveau, 4,53, overschrijdt.) Met de functie F.VERDELING van Excel kunt u de kans berekenen dat zo'n hoge F-waarde toevallig voorkomt. Bijvoorbeeld F.VERDELING(459,753674, 4, 6) = 1,37E-7, een uiterst kleine kans. U mag concluderen, door het kritische niveau van F in een tabel op te zoeken of door gebruik te maken van de functie F.VERDELING, dat de regressievergelijking bruikbaar is bij het voorspellen van de geschatte waarde van kantoorgebouwen in dit gebied. Het is wel van groot belang dat u werkt met de juiste waarden van v1 en v2 die in de vorige alinea zijn berekend.
Voorbeeld 5: De t-waarden berekenen
Met een andere toets van de hypothese kunt u bepalen of elke richtingscoëfficiënt bruikbaar is bij het schatten van de waarde van een kantoorgebouw uit voorbeeld 3. Als u bijvoorbeeld de ouderdomscoëfficiënt wilt toetsen op statistische significantie, deelt u -234,24 (de richtingscoëfficiënt voor ouderdom) door 13,268 (de geschatte standaardfout voor de ouderdomscoëfficiënten in cel A15). Hieruit volgt de waargenomen t-waarde:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Als de absolute waarde van t hoog genoeg is, kan worden geconcludeerd dat de richtingscoëfficiënt bruikbaar is bij het schatten van de waarde van een kantoorgebouw uit voorbeeld 3. In de volgende tabel ziet u de absolute waarden van de 4 waargenomen t-waarden.
Als u er een tabel in een statistisch naslagwerk op naslaat, vindt u dat de kritische t-waarde (gegeven een tweezijdige t-verdeling met 6 vrijheidsgraden en alfa = 0,05) 2,447 bedraagt. Deze kritische waarde kan ook worden gevonden met de functie T.INV van Excel. TINV(0,05;6) = 2,447. Omdat de absolute waarde van t (17,7) groter is dan 2,447, is ouderdom een belangrijke variabele bij het bepalen van de geschatte waarde van een kantoorgebouw. Alle andere variabelen kunnen op dezelfde wijze worden getest voor hun statistische significantie. Hieronder volgen de waargenomen t-waarden van de onafhankelijke variabelen.
|
Variabele |
Waargenomen t-waarde |
|---|---|
|
Vloeroppervlak |
5,1 |
|
Aantal kamers |
31,3 |
|
Aantal ingangen |
4,8 |
|
Ouderdom |
17,7 |
Deze waarden hebben allemaal een absolute waarde die groter is dan 2,447. Hieruit blijkt dat alle variabelen die in de regressievergelijking voorkomen, gebruikt mogen worden voor het voorspellen van de geschatte waarde van kantoorgebouwen in dit gebied.









