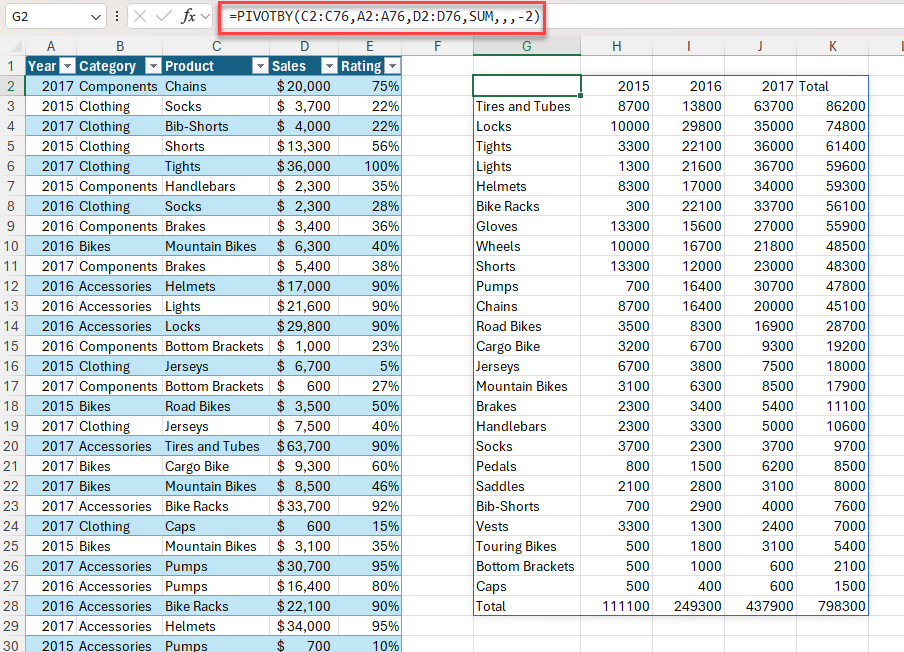
PIVOTBY 함수를 사용하면 수식을 통해 데이터의 요약을 만들 수 있습니다. 두 축을 따라 그룹화하고 연결된 값을 집계할 수 있습니다. instance 판매 데이터 테이블이 있는 경우 주 및 연도별 판매 요약을 생성할 수 있습니다.
참고
비슷한 출력을 생성할 수 있지만 PIVOTBY는 Excel의 피벗 테이블 기능과 직접 관련이 없습니다.
구문
PIVOTBY 함수를 사용하면 지정한 행 및 열 필드를 기반으로 데이터를 그룹화, 집계, 정렬 및 필터링할 수 있습니다.
PIVOTBY 함수의 구문은 다음과 같습니다.
PIVOTBY(row_fields,col_fields,values,function,[field_headers],[row_total_depth],[row_sort_order],[col_total_depth],[col_sort_order],[filter_array],[relative_to])
| 인수 | 설명 |
|---|---|
|
row_fields (필수) |
행을 그룹화하고 행 머리글을 생성하는 데 사용되는 값을 포함하는 열 지향 배열 또는 범위입니다. 배열 또는 범위에 여러 열이 포함될 수 있습니다. 이 경우 출력에는 여러 행 그룹 수준이 있습니다. |
|
col_fields (필수) |
열을 그룹화하고 열 머리글을 생성하는 데 사용되는 값을 포함하는 열 지향 배열 또는 범위입니다. 배열 또는 범위에 여러 열이 포함될 수 있습니다. 이 경우 출력에는 여러 열 그룹 수준이 있습니다. |
|
값 (필수) |
집계할 데이터의 열 지향 배열 또는 범위입니다. 배열 또는 범위에 여러 열이 포함될 수 있습니다. 이 경우 출력에는 여러 집계가 있습니다. |
|
함수 (필수) |
값을 집계하는 방법을 정의하는 람다 함수 또는 eta-reduced 람다(SUM, AVERAGE, COUNT 등)입니다. 람다 벡터를 제공할 수 있습니다. 이 경우 출력에는 여러 집계가 있습니다. 벡터의 방향은 행 또는 열 단위로 배치되는지 여부를 결정합니다. |
| field_headers |
row_fields, col_fields 및 값에 헤더가 있는지 여부와 결과에서 필드 헤더를 반환해야 하는지 여부를 지정하는 숫자입니다. 가능한 값은 다음과 같습니다. 누락: 자동입니다. 0: 아니요 1: 예 및 표시 안 함 2: 아니요만 생성 3: 예 및 표시 참고: 자동으로 데이터에 값 인수를 기반으로 하는 헤더가 포함되어 있다고 가정합니다. 첫 번째 값이 텍스트이고 두 번째 값이 숫자인 경우 데이터에 머리글이 있는 것으로 간주됩니다. 여러 행 또는 열 그룹 수준이 있는 경우 필드 머리글이 표시됩니다. |
| row_total_depth | 행 머리글에 합계가 포함되어야 하는지 여부를 결정합니다. 가능한 값은 다음과 같습니다. 누락: 자동: 총합계 및 가능한 경우 부분합. 0: 합계 없음 1: 총합계 2: 그랜드 및 부분합 -1: 총합계 1위 -2: 상단의 그랜드 및 부분합 참고: 부분합의 경우 row_fields 2개 이상의 열이 있어야 합니다. 2보다 큰 숫자는 충분한 열이 row_field 제공되면 지원됩니다. |
| row_sort_order | 열을 정렬하는 방법을 나타내는 숫자입니다. 숫자는 row_fields 열과 값의 열에 해당합니다. 숫자가 음수이면 행이 내림차순/역순으로 정렬됩니다. row_fields 기준으로 정렬할 때 숫자 벡터를 제공할 수 있습니다. |
| col_total_depth | 열 머리글에 합계가 포함되어야 하는지 여부를 결정합니다. 가능한 값은 다음과 같습니다. 누락: 자동: 총합계 및 가능한 경우 부분합. 0: 합계 없음 1: 총합계 2: 그랜드 및 부분합 -1: 총합계 1위 -2: 상단의 그랜드 및 부분합 참고: 부분합의 경우 col_fields 2개 이상의 열이 있어야 합니다. 열이 충분한 col_field 2보다 큰 숫자는 지원됩니다. |
| col_sort_order | 행을 정렬하는 방법을 나타내는 숫자입니다. 숫자는 col_fields 열과 값의 열에 해당합니다. 숫자가 음수이면 행이 내림차순/역순으로 정렬됩니다. col_fields 기준으로 정렬할 때 숫자 벡터를 제공할 수 있습니다. |
| filter_array | 해당 데이터 행을 고려해야 하는지 여부를 나타내는 부울의 열 지향 1D 배열입니다. 참고: 배열의 길이는 row_fields 및 col_fields 제공된 배열의 길이와 일치해야 합니다. |
| relative_to | 두 개의 인수가 필요한 집계 함수를 사용하는 경우 relative_to 집계 함수의 두 번째 인수에 제공되는 값을 제어합니다. 일반적으로 PERCENTOF가 작동하도록 제공된 경우에 사용됩니다. 가능한 값은 다음과 같습니다. 0: 열 합계(기본값) 1: 행 합계 2: 총합계 3: 부모 Col Total 4: 부모 행 합계 참고: 이 인수는 함수 에 두 개의 인수가 필요한 경우에만 영향을 줍니다. 함수에 사용자 지정 람다 함수를 제공하는 경우 LAMBDA(하위 집합, totalset,SUM(하위 집합)/SUM(totalset) 패턴을 따라야 합니다. |
예제
예제 1: PIVOTBY를 사용하여 제품 및 연도별 총 매출 요약을 생성합니다.
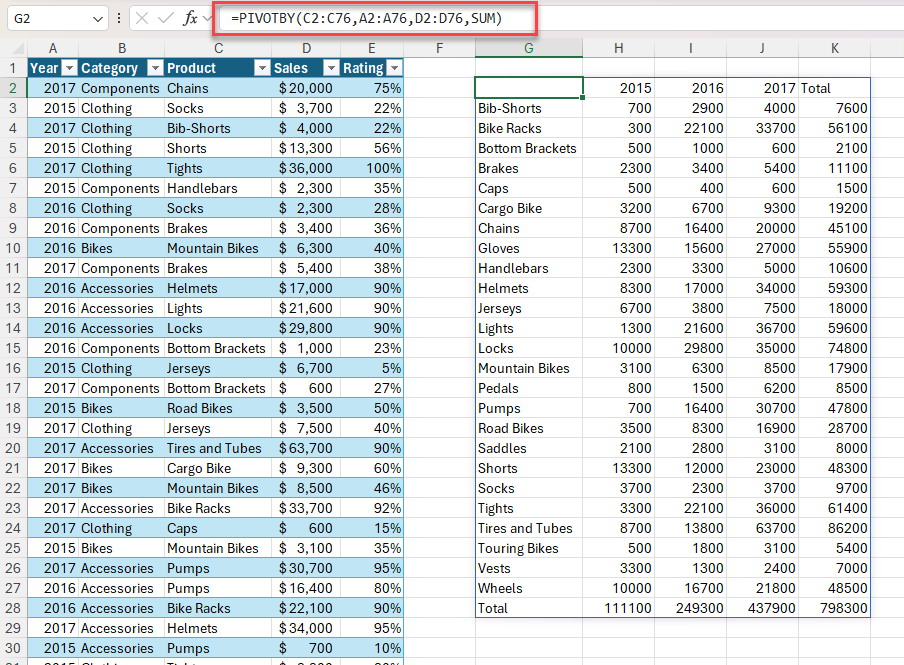
예제 2: PIVOTBY를 사용하여 제품 및 연도별 총 매출 요약을 생성합니다. 판매별로 내림차순을 정렬합니다.