
Šiame straipsnyje aprašoma formulės sintaksė ir funkcijos LINEST naudojimas programoje "Microsoft Excel".
Aprašas
Funkcija LINEST skaičiuoja tiesės statistiką naudodama mažiausiųjų kvadratų metodą, skirtą geriausiai jūsų duomenis atitinkančiai tiesei apskaičiuoti, ir tada grąžina masyvą, aprašantį liniją. Funkciją LINEST galite derinti su kitomis funkcijomis, jei norite skaičiuoti kitų tipų modelių, kurių nežinomi parametrai yra tiesiniai, statistiką, įskaitant polinomines, logaritmines, eksponentines ir laipsnines sekas. Ši funkcija grąžina reikšmių masyvą, todėl ji turi būti įvedama kaip masyvo formulė. Nurodymai pateikti šio straipsnio pavyzdžiais.
Tiesės lygtis yra:
y = mx + b
Arba
y = m1x1 + m2x2 + ... + b
jeigu yra keli x reikšmių diapazonai, kur priklausoma y reikšmė yra nepriklausomų x reikšmių funkcija. M reikšmės yra kiekvieną x reikšmę atitinkantys koeficientai, o b yra konstanta. Atkreipkite dėmesį, kad y, x ir m gali būti vektoriai. Masyvas, kurį grąžina funkcija LINEST, yra {mn,mn-1,...,m1,b}. LINEST taip pat gali grąžinti papildomus regresinės statistikos duomenis.
Sintaksė
LINEST(žinomi_y, [žinomi_x], [konst], [statistika])
Funkcijos LINEST sintaksė turi tokius argumentus:
Sintaksė
known_y Būtina. Susijęs su jau žinomų y reikšmių aibe y = mx + b.
- Jei known_y diapazonas yra viename stulpelyje, kiekvienas known_x stulpelis laikomas atskiru kintamuoju.
- Jei known_y diapazonas yra vienoje eilutėje, kiekviena known_x eilutė interpretuojama kaip atskiras kintamasis.
known_x Pasirinktinai. Nebūtinai susiję su jau žinomų x reikšmių aibe y = mx + b.
- known_x diapazonas gali apimti vieną ar kelis kintamųjų rinkinius. Jei naudojamas tik vienas kintamasis, known_y ir known_x gali būti bet kokios formos diapazonai, jei tik jų dimensijos sutampa. Jei naudojama daugiau nei vienas kintamasis, known_y turi būti vektorius (t. y. diapazonas, kurio aukštis – viena eilutė arba plotis – vienas stulpelis).
- Jei known_x nenurodoma, laikoma, kad masyvas {1,2,3,...} yra tokio paties dydžio kaip ir known_y.
konst Pasirinktinai. Loginė reikšmė, nurodanti, ar konstanta b turi būti lygi 0.
- Jei konstanta yra TRUE arba praleista, b skaičiuojama normaliai.
- Jei konstanta yra FALSE, b prilyginama 0, o m reikšmės koreguojamos taip, kad atitiktų lygybę y = mx.
Statistika Pasirinktinai. Loginė reikšmė, nurodanti, ar reikia grąžinti papildomus regresinės statistikos duomenis.
- Jei statistika yra TRUE, LINEST pateikia papildomus regresinės statistikos duomenis; Todėl grąžintas masyvas yra {mn,mn-1,...,m1,b; sen,sen-1,...,se1,seb; R2, Sey; F, df; ksreg,ksliek}.
- Jei statistika yra FALSE arba praleista, LINEST grąžina tik m koeficientus ir konstantą b.
Papildomos regresinės statistikos duomenys yra šie.
| Statistikos duomuo | Aprašymas |
|---|---|
| sp1;sp2;...;spn | Standartinės paklaidos koeficientų m1,m2,...,mn reikšmės. |
| spb | Konstantos b standartinė klaidos reikšmė (seb = #N/A, kai konstanta yra FALSE). |
| R2 | Determinacijos koeficientas. Lygina apskaičiuotąsias ir tikrąsias y reikšmes ir yra nuo 0 iki 1. Jei jis yra 1, pavyzdyje egzistuoja ideali koreliacija – nėra jokio skirtumo tarp apskaičiuotosios ir tikrosios y reikšmės. Kitas kraštutinumas – jei determinacijos koeficientas yra 0, regresinė lygtis nėra naudinga prognozuojant y reikšmę. Plačiau apie tai, kaip skaičiuojamas2 , rasite šios temos skyriuje "Pastabos". |
| spy | Y įverčio standartinė paklaida. |
| F | F statistika arba F stebima reikšmė. Naudokite F statistiką norėdami nustatyti, ar stebimas ryšys tarp priklausomų ir nepriklausomų kintamųjų yra atsitiktinis. |
| ll | Laisvės laipsniai. Laisvės laipsniais galite rasti F kritines reikšmes statistinėje lentelėje. Lyginkite lentelėje esančias reikšmes su funkcijos LINEST grąžinama F statistika, norėdami nustatyti modelio pasikliautinumo lygmenį. Plačiau apie tai, kaip skaičiuojamas ll, rasite šios temos skyriuje „Pastabos“. Toliau pateikiamame 4 pavyzdyje demonstruojamas F ir ll naudojimas. |
| ksreg | Regresijos kvadratų suma. |
| ksliek | Liekamoji kvadratų suma. Plačiau apie tai, kaip skaičiuojami ksreg ir ksliek, rasite šios temos skyriuje „Pastabos“. |
Ši iliustracija rodo tvarką, kuria grąžinami papildomi regresinės statistikos duomenys.

Pastabos
Bet kokią tiesę galite aprašyti krypties koeficientu ir y postūmiu:
Nuolydis (m):
Norėdami rasti tiesės nuolydį, dažnai rašomą kaip m, paimkite du tiesės taškus (x1,y1) ir (x2,y2); Nuolydis lygus (y2 - y1)/(x2 - x1).
Y poslinkis (b):
tiesės y postūmis, dažnai žymimas b, yra y reikšmė taške, kuriame tiesė kerta y ašį.
Tiesės lygtis yra y = mx + b. Jei žinotei reikšmes m ir b, galite apskaičiuoti bet kokį tiesėje esantį tašką, į šią lygtį įrašydami y arba x reikšmę. Taip pat galite naudoti funkciją TREND.Jei turite tik vieną nepriklausomą kintamąjį x, galite gauti krypties koeficiento ir y postūmio reikšmes tiesiogiai naudodami šias formules:
Nuolydis:
=INDEX(LINEST(known_y,known_x);1)
Y postūmis:
=INDEX(LINEST(known_y,known_x);2)Funkcijos LINEST apskaičiuotos tiesės tikslumas priklauso nuo jūsų duomenų sklaidos koeficiento. Kuo tiesiškesni duomenys, tuo tikslesnis LINEST modelis. Funkcija LINEST geriausiai jūsų duomenis atitinkantį variantą parenka naudodama mažiausiųjų kvadratų metodą. Jei turite tik vieną nepriklausomą kintamąjį x, m ir b skaičiavimas pagrįstas šiomis formulėmis:
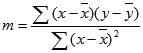
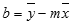
kur x ir y yra pavyzdžių vidurkiai; tai yra x = AVERAGE(žinomi x) ir y = AVERAGE(known_y).Linijų ir kreivių derinimo funkcijos LINEST ir LOGEST gali apskaičiuoti geriausiai jūsų duomenis atitinkančią tiesę arba eksponentinę kreivę. Tačiau turite nuspręsti, kuris iš dviejų rezultatų geriausiai atitinka jūsų duomenis. Galite suskaičiuoti tiesės funkciją TREND(known_y, known_x), o eksponentinę kreivę – GROWTH(known_y, known_x). Šios funkcijos be new_x argumento pateikia y reikšmių masyvą, numatytą išilgai tos tiesės ar kreivės faktiniuose duomenų taškuose. Tada galite palyginti prognozuojamas reikšmes su faktinėmis reikšmėmis. Galite nubraižyti jų abiejų diagramas, kad galėtumėte vizualiai palyginti.
Regresinėje analizėje programa „Excel“ kiekvienam taškui randa skirtumo tarp to taško apskaičiuotos y reikšmės ir realios y reikšmės kvadratą. Šių skirtumų kvadratų suma vadinama liekamąja kvadratų suma ksliek. Tuomet programa „Excel“ apskaičiuoja bendrą kvadratų sumą ksbendra. Kai konstantos argumentas = TRUE arba praleistas, bendra kvadratų suma yra kvadratu pakeltų skirtumų tarp tikrųjų y reikšmių ir vidutinių y reikšmių suma. Kai konstantos argumentas = FALSE, bendra kvadratų suma yra kvadratu pakeltų tikrųjų y reikšmių (neatimant vidutinės y reikšmės iš kiekvienos y reikšmės) suma. Tuomet gali būti randama regresijos kvadratų suma ksreg: ksreg = ksbendra - ksliek. Kuo mažesnė liekamoji kvadratų suma, palyginti su bendra kvadratų suma, tuo didesnė determinacijos koeficiento r2 reikšmė, kuri rodo, kiek gerai iš regresinės analizės gauta lygtis paaiškina sąryšius tarp kintamųjų. r2 reikšmė lygi ksreg/ksbendra.
Kai kuriais atvejais vienas ar keli X stulpeliai (tarkime, kad Y ir X yra stulpeliuose) gali neturėti papildomos prognozės reikšmės, jei yra kiti X stulpeliai. Kitaip tariant, pašalinus vieną ar daugiau X stulpelių, gali būti gautos vienodai tikslios prognozuojamos Y reikšmės. Tokiu atveju šie pertekliniai X stulpeliai neturėtų būti įtraukti į regresijos modelį. Šis reiškinys vadinamas "kolinearumu", nes bet koks perteklinis X stulpelis gali būti išreikštas kaip neperteklinių X stulpelių kartotinių elementų suma. Funkcija LINEST tikrina kolinearumą ir pašalina visus nereikalingus X stulpelius iš regresijos modelio, kai juos identifikuoja. Pašalinti X stulpeliai gali būti atpažįstami kaip turintys 0 koeficientų kartu su 0 se reikšmėmis. Jei vienas ar keli stulpeliai pašalinami kaip pertekliniai, paveikiama ll, nes df priklauso nuo X stulpelių skaičiaus, kuris iš tikrųjų naudojamas prognozavimo tikslais. Išsamesnės informacijos apie df skaičiavimą žr. 4 pavyzdyje. Jei lls pakeičiamas pašalinus perteklinius X stulpelius, paveikiamos ir sey bei F reikšmės. Kolinearumas praktikoje turėtų būti gana retas. Tačiau labiau tikėtina, kad tai įvyks, kai kai kuriuose X stulpeliuose yra tik 0 ir 1 reikšmės, rodančios, ar eksperimente dalyvaujantis asmuo yra tam tikros grupės narys, ar ne. Jei konstanta = TRUE arba yra praleista, funkcija LINEST efektyviai įterpia papildomą X stulpelį, kuriame yra visos 1 reikšmės, kad modeliuotų sankirtą. Jei turite stulpelį, kuriame kiekvienam subjektui yra 1, jei vyras, arba 0, jei ne, ir taip pat yra stulpelis, kuriame kiekvienam subjektui yra 1, jei moteris, arba 0, jei ne, pastarasis stulpelis yra perteklinis, nes įrašus jame galima gauti atėmus įrašą stulpelyje "vyriškas indikatorius" iš įrašo papildomame stulpelyje, kuriame yra visos reikšmės 1, pridėtos funkcijos LINEST .
Kai X stulpeliai nepašalinami iš modelio dėl kolinearumo, ll reikšmė apskaičiuojama taip: jei yra k stulpelių known_x ir konstanta = TRUE arba nenurodyta, df = n – k – 1. Jei konstanta = FALSE, ll = n - k. Abiem atvejais kiekvienas X stulpelis, kuris buvo pašalintas dėl kolinearumo, padidina ll reikšmę vienetu.
Įvesdami masyvo konstantą (pvz., known_x) kaip argumentą, atskirkite toje pačioje eilutėje esančias reikšmes kableliais, o eilutes – kabliataškiais. Skyriklio simboliai gali skirtis, atsižvelgiant į regiono parametrus.
Atkreipkite dėmesį, kad regresijos lygties prognozuojamos y reikšmės gali negalioti, jei jos yra už y reikšmių diapazono, naudoto lyčiai apibrėžti.
Esantis algoritmas, kuris naudojamas funkcijoje LINEST, skiriasi nuo funkcijose SLOPE ir INTERCEPT naudojamo algoritmo. Dėl šių algoritmų skirtumo, kai duomenys neapibrėžti ir linijiški, rezultatai gali skirtis. Pavyzdžiui, jei known_y argumento duomenų taškai lygūs 0, o known_x argumento duomenų taškai lygūs 1:
- Funkcijos LINEST grąžinama reikšmė lygi 0. Funkcijos LINEST algoritmas skirtas tinkamiems linijiškų duomenų rezultatams grąžinti ir tokiu atveju galima rasti mažiausiai vieną atsakymą.
- SLOPE ir INTERCEPT grąžina #DIV/0! klaidą. Funkcijų SLOPE ir INTERCEPT algoritmas skirtas ieškoti tik vieno atsakymo, o šiuo atveju gali būti daugiau nei vienas atsakymas.
Be to, kad funkciją LOGEST naudojate kitų regresijų tipų statistikai skaičiuoti, galite naudoti funkciją LINEST kitų regresijų tipų diapazonui skaičiuoti įvesdami x ir y kintamųjų funkcijas kaip funkcijos LINEST x ir y sekas. Pavyzdžiui ši formulė:
=LINEST(yreikšmės, xreikšmės^STULPELIS($A:$C))
veikia, kai norite skaičiuoti vieno y reikšmių stulpelio ir vieno x reikšmių stulpelio kubinę formos (trečios eilės polinomo) aproksimaciją:
y = m1*x + m2*x^2 + m3*x^3 + b
Galite keisti šią formulę kitiems regresijos tipams skaičiuoti, bet kai kuriais atvejais reikia derinti išvesties reikšmes ir kitus statistinius duomenis.F testo reikšmė, kurią grąžina funkcija LINEST, skiriasi nuo F testo reikšmės grąžinamos funkcijos FTEST. LINEST grąžina F statistiką, o funkcija FTEST grąžina tikimybę.
Pavyzdžiai
1 pavyzdyje: krypties koeficientas ir y poslinkis
Iš pateiktosios lentelės nusikopijuokite pavyzdinius duomenis ir įklijuokite į naujos „Excel“ darbaknygės langelį A1. Kad formulės rodytų rezultatus, jas pažymėkite, paspauskite F2 ir spauskite Enter. Jeigu reikia, pakoreguokite langelių plotį, kad matytųsi visi duomenys.
| Žinomi y | Žinomi x |
|---|---|
| 1 | 0 |
| 9 | 4 |
| 5 | 2 |
| 7 | 3 |
| Rezultatas (nuokrypis) | Rezultatas (y ašis) |
| 2 | 1 |
| Formulė (masyvas diapazone A7:B7) | |
| =LINEST(A2:A5,B2:B5,,FALSE) |
2 pavyzdyje: paprasta tiesinė regresija
Iš pateiktosios lentelės nusikopijuokite pavyzdinius duomenis ir įklijuokite į naujos „Excel“ darbaknygės langelį A1. Kad formulės rodytų rezultatus, jas pažymėkite, paspauskite F2 ir spauskite Enter. Jeigu reikia, pakoreguokite langelių plotį, kad matytųsi visi duomenys.
| Mėnuo | Pardavimas |
|---|---|
| 1 | 3 100 EUR |
| 2 | 4 500 EUR |
| 3 | 4 400 EUR |
| 4 | 5 400 EUR |
| 5 | 7 500 EUR |
| 6 | 8 100 EUR |
| Formulė | Rezultatas |
| =SUM(LINEST(B1:B6, A1:A6)*{9,1}) | 11 000 EUR |
| Apskaičiuoja devintojo mėnesio pardavimo įvertį, remiantis pardavimo laikotarpiu nuo 1 iki 6 mėnesio. |
3 pavyzdyje: daugybinė tiesinė regresija
Iš pateiktosios lentelės nusikopijuokite pavyzdinius duomenis ir įklijuokite į naujos „Excel“ darbaknygės langelį A1. Kad formulės rodytų rezultatus, jas pažymėkite, paspauskite F2 ir spauskite Enter. Jeigu reikia, pakoreguokite langelių plotį, kad matytųsi visi duomenys.
| Grindų plotas (x1) | Biurai (x2) | Įėjimai (x3) | Amžius (x4) | Įkainotoji vertė (y) |
|---|---|---|---|---|
| 2310 | 2 | 2 | 20 | 142 000 EUR |
| 2333 | 2 | 2 | 12 | 144 000 EUR |
| 2356 | 3 | 1.5 | 33 | 151 000 EUR |
| 2379 | 3 | 2 | 43 | 150 000 EUR |
| 2402 | 2 | 3 | 53 | 139 000 EUR |
| 2425 | 4 | 2 | 23 | 169 000 EUR |
| 2448 | 2 | 1.5 | 99 | 126 000 EUR |
| 2471 | 2 | 2 | 34 | 142 900 EUR |
| 2494 | 3 | 3 | 23 | 163 000 EUR |
| 2517 | 4 | 4 | 55 | 169 000 EUR |
| 2540 | 2 | 3 | 22 | 149 000 EUR |
| -234.2371645 | ||||
| 13.26801148 | ||||
| 0.996747993 | ||||
| 459.7536742 | ||||
| 1732393319 | ||||
| Formulė (dinaminio masyvo formulė įvesta į A19) | ||||
| =LINEST(E2:E12,A2:D12,TRUE,TRUE) |
4 pavyzdyje: f ir r2 statistinių duomenų naudojimas
Ankstesniame pavyzdyje determinacijos koeficientas r2 yra 0,99675 (žr. langelį A17 funkcijos LINEST išvestyje), o tai rodo stiprų sąryšį tarp nepriklausomų kintamųjų ir pardavimo kainos. Naudodami F statistiką galite nustatyti, ar rezultatai su tokia aukšta r2 reikšme gauti atsitiktinai.
Tarkime, iš tiesų tarp kintamųjų nėra ryšio, bet jūs pasirinkote mažai tikėtiną imtį iš 11 biuro pastatų, kuriems statistinė analizė rodo stiprų sąryšį. Terminas „Alfa“ vartojamas klaidingos išvados apie tokį sąryšį tikimybei apibūdinti.
Funkcijos LINEST išvesties F ir ll reikšmės gali būti naudojamos įvertinti didesnės F reikšmės atsitiktinumo tikimybę. F galima palyginti su kritinėmis reikšmėmis publikuotose F pasiskirstymo lentelėse arba naudojant funkciją FDIST programoje "Excel" galima apskaičiuoti didesnės F reikšmės atsitiktinumo tikimybę. Atitinkamas F skirstinys turi v1 ir v2 laisvės laipsnį. Jei n yra duomenų reikšmių skaičius ir konstanta = TRUE arba praleista, tada v1 = n – df – 1 ir v2 = df. (Jei konstanta = FALSE, tada v1 = n – df ir v2 = df.) Funkcija FDIST – su sintakse FDIST(F,v1,v2) – grąžins didesnės F reikšmės atsitiktinumo tikimybę. Šiame pavyzdyje df = 6 (langelis B18) ir F = 459,753674 (langelis A18).
Imant Alfa reikšmę 0,05, v1 = 11 – 6 – 1 = 4 ir v2 = 6, kritinis F lygis yra 4,53. Kadangi F = 459,753674 yra daug didesnis už 4,53, labai mažai tikėtina, kad tokia didelė F reikšmė pasirodė atsitiktinai. (Kai Alfa = 0,05, hipotezė, kad nėra jokio ryšio tarp known_y ir known_x , turi būti atmesta, kai F viršija kritinį lygį 4,53). Galite naudoti programos "Excel" funkciją FDIST apskaičiuoti tikimybei, kad tokia didelė F reikšmė buvo atsitiktinė. Pvz., FDIST(459,753674; 4; 6) = 1,37E-7, labai maža tikimybė. Naudodami kritinę F reikšmę lentelėje arba funkciją FDIST galite daryti išvadą, kad regresijos lygtis yra naudinga numatant įkainotąją pastatų vertę šioje vietovėje. Nepamirškite, kad labai svarbu naudoti teisingas prieš tai apskaičiuotas v1 ir v2 reikšmes.
5 pavyzdyje: t statistikos skaičiavimas
Kitu hipotezės tikrinimu bus nustatoma, kuris krypties koeficientas yra naudingas apskaičiuojant įkainotąją biuro pastato vertę 3 pavyzdyje. Pavyzdžiui, norėdami patikrinti amžiaus koeficiento statistinį reikšmingumą, padalykite -234,24 (amžiaus krypties koeficientas) iš 13,268 (amžiaus koeficientų apskaičiuotoji standartinė paklaida, esanti langelyje A15). Tai yra t stebimoji vertė:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Jei absoliuti t vertė yra pakankamai didelė, galima daryti išvadą, kad nuolydžio koeficientas yra naudingas apskaičiuojant įkainotąją biuro pastato vertę 3 pavyzdyje. Šioje lentelėje pateikiami 4 t stebimųjų reikšmių moduliai.
Jei pasižiūrėsite į lentelę statistikos vadovėlyje, pamatysite, kad t kritinė, dviejų pabaigų, su 6 laisvumo laipsniais, o Alfa = 0,05 yra 2,447. Šią kritinę reikšmę taip pat galite rasti naudodami programos "Excel" funkciją TINTRA. TINV (0,05;6) = 2,447. Kadangi absoliučioji t reikšmė (17,7) yra didesnė už 2,447, amžius yra svarbus kintamasis, apskaičiuojant įkainotąją biuro pastato vertę. Kiekvieno kito nepriklausomo kintamojo statistinis reikšmingumas gali būti patikrintas panašiu būdu. Toliau pateikiamos t stebimosios reikšmės kiekvienam iš nepriklausomų kintamųjų.
| Kintamasis | t stebimoji reikšmė |
|---|---|
| Grindų plotas | 5,1 |
| Biurų skaičius | 31,3 |
| Įėjimų skaičius | 4,8 |
| Amžius | 17,7 |
Šių reikšmių absoliučioji reikšmė yra didesnė nei 2,447; taigi visi regresijos lygtyje panaudoti kintamieji yra naudingi nuspėjant įkainotąją biuro pastatų vertę šioje vietovėje.