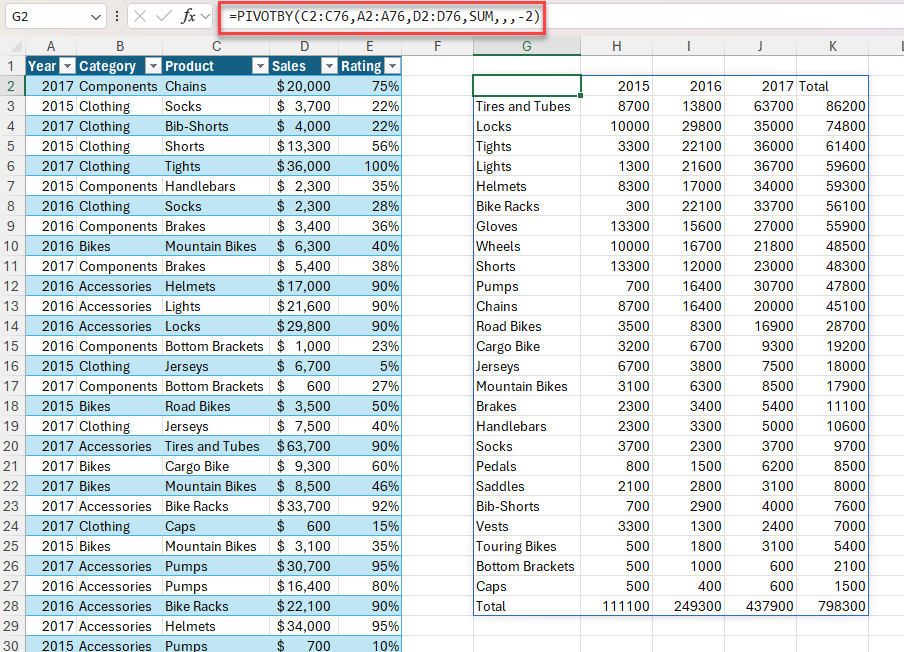
Funcția PIVOTBY vă permite să creați un rezumat al datelor cu ajutorul unei formule. Acceptă gruparea pe două axe și agregarea valorilor asociate. De exemplu, dacă aveți un tabel cu date de vânzări, puteți genera un rezumat al vânzărilor după județ și an.
Notă
Deși poate produce rezultate similare, PIVOTBY nu este asociat direct cu caracteristica PivotTable din Excel.
Sintaxă
Funcția PIVOTBY vă permite să grupați, să agregați, să sortați și să filtrați date pe baza câmpurilor de rând și coloană pe care le specificați.
Sintaxa funcției PIVOTBY este:
PIVOTBY(row_fields,col_fields,valori,funcție,[field_headers],[row_total_depth],[row_sort_order],[col_total_depth],[col_sort_order],[filter_array],[relative_to])
| Argument | Descriere |
|---|---|
|
row_fields (obligatoriu) |
O matrice sau o zonă orientată pe coloane care conține valorile utilizate pentru a grupa rândurile și a genera anteturi de rând. Matricea sau zona poate conține mai multe coloane. Dacă da, rezultatul va avea mai multe niveluri de grup de rânduri. |
|
col_fields (obligatoriu) |
O matrice sau o zonă orientată pe coloane care conține valorile utilizate pentru gruparea coloanelor și generarea anteturilor de coloană. Matricea sau zona poate conține mai multe coloane. Dacă da, rezultatul va avea mai multe niveluri de grup de coloane. |
|
valori (obligatoriu) |
O matrice orientată pe coloane sau o zonă de date de agregat. Matricea sau zona poate conține mai multe coloane. Dacă da, rezultatul va avea mai multe agregări. |
|
funcție (obligatoriu) |
O funcție lambda sau funcția lambda (SUM, AVERAGE, COUNT etc.) redusă eta, care definește modul de agregare a valorilor. Poate fi furnizat un vector de lambda. Dacă da, rezultatul va avea mai multe agregări. Orientarea vectorului va determina dacă sunt așezate pe rânduri sau pe coloane. |
| field_headers | Este un număr care specifică dacă row_fields, col_fields și valorile au anteturi și dacă anteturile de câmp trebuie returnate în rezultate. Valorile posibile sunt: Lipsește: Automat. 0: Nu 1: Da și Nu se afișează 2: Nu, dar generați 3: Da și afișați Notă: Automat presupune că datele conțin anteturi bazate pe argumentul valori. Dacă prima valoare este text și a 2-a valoare este un număr, atunci se consideră că datele au anteturi. Anteturile câmpurilor sunt afișate dacă există mai multe niveluri de grup de rânduri sau coloane. |
| row_total_depth | Determină dacă anteturile de rând trebuie să conțină totaluri. Valorile posibile sunt: Lipsă: Automat: totaluri generale și, dacă este posibil, subtotaluri. 0: Fără totaluri 1: Totalurile generale 2: Totaluri generale și subtotaluri -1: Totalurile generale în partea de sus -2: Totaluri generale și subtotaluri în partea de sus Notă: Pentru subtotaluri, row_fields trebuie să aibă cel puțin 2 coloane. Numerele mai mari decât 2 sunt acceptate, cu condiția row_field să aibă suficiente coloane. |
| row_sort_order | Un număr care indică modul în care ar trebui sortate coloanele. Numerele corespund cu coloanele din row_fields urmate de coloanele din valori. Dacă numărul este negativ, rândurile sunt sortate în ordine descendentă/inversă. Se poate furniza un vector de numere atunci când sortați doar pe baza row_fields. |
| col_total_depth | Determină dacă anteturile de coloană trebuie să conțină totaluri. Valorile posibile sunt: Lipsă: Automat: totaluri generale și, dacă este posibil, subtotaluri. 0: Fără totaluri 1: Totalurile generale 2: Totaluri generale și subtotaluri -1: Totalurile generale în partea de sus -2: Totaluri generale și subtotaluri în partea de sus Notă: Pentru subtotaluri, col_fields trebuie să aibă cel puțin 2 coloane. Numerele mai mari decât 2 sunt acceptate, cu condiția col_field să aibă suficiente coloane. |
| col_sort_order | Un număr care indică modul în care ar trebui sortate rândurile. Numerele corespund coloanelor din col_fields urmate de coloanele din valori. Dacă numărul este negativ, rândurile sunt sortate în ordine descendentă/inversă. Se poate furniza un vector de numere atunci când sortați doar pe baza col_fields. |
| filter_array | O matrice 1D orientată pe coloane de valori booleene care indică dacă rândul corespondent de date ar trebui luat în considerare. Notă: Lungimea matricei trebuie să se potrivească cu lungimea celor furnizate pentru row_fields și col_fields. |
| relative_to | Atunci când utilizați o funcție de agregare care necesită două argumente, relative_to controlează ce valori sunt furnizate pentru al doilea argument al funcției de agregare. Aceasta este utilizată de obicei atunci când se furnizează PERCENTOF pentru a funcționa. Valorile posibile sunt: 0: Totaluri pe coloane (implicit) 1: Totaluri rând 2: Totalurile generale 3: Total coloane părinte 4: Total rând părinte Notă: Acest argument are impact doar dacă funcția necesită două argumente. Dacă furnizați o funcție lambda particularizată pentru a funcționa, aceasta ar trebui să urmeze acest model: LAMBDA(subset,totalset,SUM(subset)/SUM(totalset)) |
Exemple
Exemplul 1: utilizați PIVOTBY pentru a genera un rezumat al vânzărilor totale după produs și an.

Exemplul 2: utilizați PIVOTBY pentru a genera un rezumat al vânzărilor totale după produs și an. Sortați descrescător după vânzări.