Функція PIVOTBY дає змогу створити зведення даних за допомогою формули. Він підтримує групування за двома віссю та агрегування пов'язаних значень. Наприклад, якщо у вас є таблиця даних про збут, можна створити зведення обсягів збуту за областю та роком.
Примітка.
Хоча вона може створювати схожі результати, функція PIVOTBY безпосередньо не пов'язана з функцією зведеної таблиці Excel.
Синтаксис
Функція PIVOTBY дає змогу групувати, агрегувати, сортувати та фільтрувати дані на основі вказаних полів рядків і стовпців.
Синтаксис функції PIVOTBY:
PIVOTBY(row_fields;col_fields;значення;функція;[field_headers];[row_total_depth],[row_sort_order],[col_total_depth],[col_sort_order],[filter_array],[relative_to])
| Аргумент | Опис |
|---|---|
|
row_fields (обов’язковий) |
Стовпчастий масив або діапазон зі значеннями, які використовуються для групування рядків і створення заголовків рядків. Масив або діапазон можуть містити кілька стовпців. У такому разі результат матиме кілька рівнів груп рядків. |
|
col_fields (обов’язковий) |
Стовпчастий масив або діапазон зі значеннями, які використовуються для групування стовпців і створення заголовків стовпців. Масив або діапазон можуть містити кілька стовпців. У такому разі результат матиме кілька рівнів груп стовпців. |
|
Значення (обов’язковий) |
Стовпчастий масив або діапазон даних, які потрібно агрегувати. Масив або діапазон можуть містити кілька стовпців. У такому разі результат матиме кілька агрегацій. |
|
функція (обов’язковий) |
Функція лямбда або лямбда зі зменшенням ета (SUM, AVERAGE, COUNT тощо), яка визначає, як агрегувати значення. Можна вибрати вектор лямбда. У такому разі результат матиме кілька агрегацій. Орієнтація вектора визначить, чи вони викладені рядками або стовпчастими. |
| field_headers | Число, яке визначає, чи мають заголовки row_fields, col_fields та значення , а також чи слід повертати заголовки полів у результатах. Можливі значення: Бракує: автоматично. 0: Ні 1. Так і не показувати 2: Ні, але генерувати 3. Так і показати Примітка: Автоматично припускає, що дані містять заголовки на основі аргументу значення. Якщо 1-е значення – це текст, а 2-е – число, то дані мають заголовки. Заголовки полів відображаються, якщо є кілька рівнів груп рядків або стовпців. |
| row_total_depth | Визначає, чи мають заголовки рядків містити підсумки. Можливі значення: Бракує: автоматично: загальні підсумки та проміжні підсумки(за можливості). 0: немає підсумків 1: Загальні підсумки 2. Загальні та проміжні підсумки -1: Загальні підсумки на початку -2: Загальні та проміжні підсумки вгорі Примітка: Для проміжних підсумків row_fields має містити принаймні 2 стовпці. Числа, більші за 2, підтримуються , якщо row_field містить достатню кількість стовпців. |
| row_sort_order | Число, яке вказує на те, як слід сортувати стовпці. Числа відповідають стовпцям у row_fields а потім стовпцям у значеннях. Якщо число від'ємне, рядки сортуються за спаданням або зворотним порядком. Вектор чисел можна використовувати під час сортування лише за row_fields. |
| col_total_depth | Визначає, чи мають заголовки стовпців містити підсумки. Можливі значення: Бракує: автоматично: загальні підсумки та проміжні підсумки(за можливості). 0: немає підсумків 1: Загальні підсумки 2. Загальні та проміжні підсумки -1: Загальні підсумки на початку -2: Загальні та проміжні підсумки вгорі Примітка: Для проміжних підсумків col_fields має містити принаймні 2 стовпці. Числа, більші за 2, підтримуються , col_field містить достатню кількість стовпців. |
| col_sort_order | Число, яке вказує на те, як слід сортувати рядки. Числа відповідають стовпцям у col_fields а потім – стовпцям у значеннях. Якщо число від'ємне, рядки сортуються за спаданням або зворотним порядком. Вектор чисел можна задати під час сортування лише за col_fields. |
| filter_array | Стовпчастий 1D-масив логічних значень, який вказує на те, чи слід враховувати відповідний рядок даних. Примітка: Довжина масиву має відповідати довжині, передбаченій для row_fields та col_fields. |
| relative_to | Використовуючи функцію агрегації, для якої потрібні два аргументи, relative_to керує значеннями, які надаються для 2-го аргументу функції агрегації. Зазвичай він використовується, коли функція PERCENTOF постачається для роботи. Можливі значення: 0: Підсумки стовпців (за замовчуванням) 1: Підсумки рядків 2: Загальні підсумки 3. Загальна кількість батьківських стовпців 4: Підсумки за батьківським рядком Примітка: Цей аргумент впливає лише на те, що функція вимагає двох аргументів. Якщо для роботи додано спеціальну функцію lambda, вона має виконуватися за такою схемою: LAMBDA(підмножина;набір підсумків;SUM(підмножина)/SUM(набір підсумків)) |
Приклади
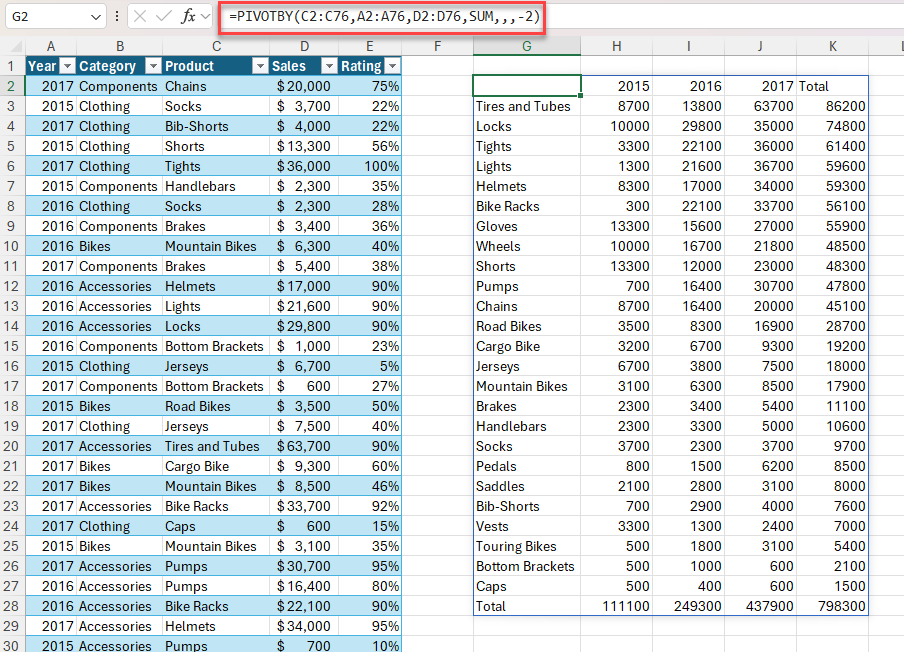
Приклад 1. Використання функції PIVOTBY для створення зведення загального обсягу збуту за продуктами та роками.
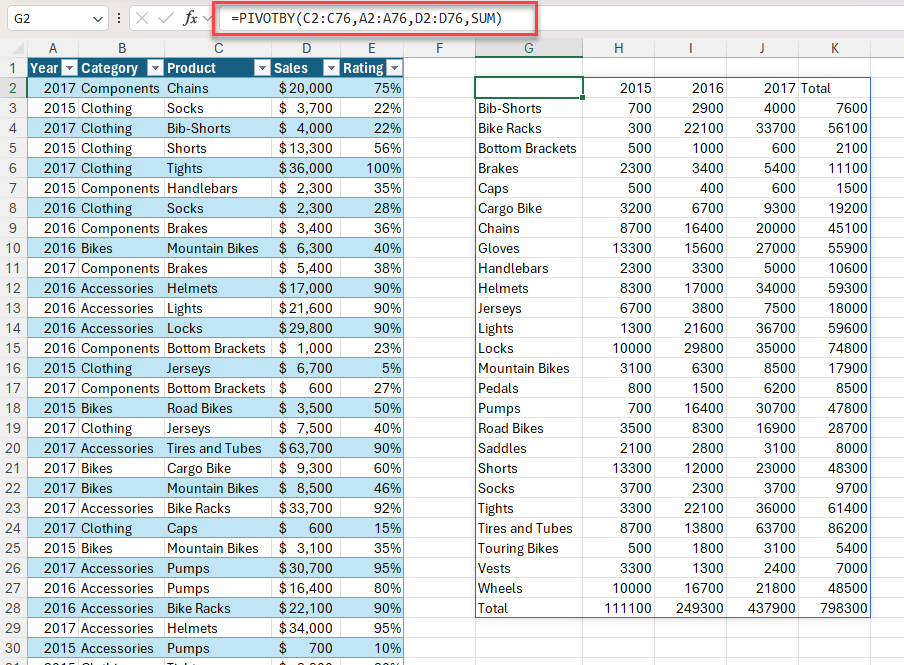
Приклад 2. Використання функції PIVOTBY для створення зведення загального обсягу збуту за продуктами та роками. Сортування за спаданням за обсягами збуту.