
Tento článek popisuje syntaxi vzorce a použití funkce LINREGRESE v Microsoft Excelu.
Popis
Funkce LINREGRESE vypočítá pomocí metody nejmenších čtverců statistické hodnoty pro přímku, která nejlépe odpovídá uvedeným datům, a vrátí matici s parametry přímky. Funkci LINREGRESE lze také použít společně s dalšími funkcemi, které vypočtou statistické hodnoty pro další typy lineárních modelů s neznámými parametry, včetně polynomických, logaritmických, exponenciálních nebo mocninných řad. Vzhledem k tomu, že tato funkce vrací matici hodnot, musí být zadána jako maticový vzorec. Pokyny jsou uvedeny u příkladů v tomto článku.
Tato přímka je definována následujícím vztahem:
y = mx + b
– nebo –
y = m1x1 + m2x2 + ... + b
pokud existuje více oblastí x, kde závislé hodnoty y jsou funkcí nezávislých hodnot x. Hodnoty m jsou koeficienty odpovídající každé z hodnot x, b je konstanta. Všimněte si, že y, x a m mohou být vektory. Matice, která je výsledkem funkce LINREGRESE, má tvar {mn;mn-1;...;m1;b}. Funkce LINREGRESE může také vracet další regresní statistiky.
Syntaxe
LINREGRESE(pole_y;[pole_x];[b];[stat])
Syntaxe funkce LINREGRESE má následující argumenty:
Syntaxe
known_y Povinné. Sada hodnot y odvozených ze vztahu y = mx + b.
- Pokud je oblast known_y v jediném sloupci, je každý sloupec known_x interpretován jako samostatná proměnná.
- Pokud je oblast known_y obsažená v jediném řádku, je každý řádek known_x interpretován jako samostatná proměnná.
known_x Volitelné. Sada hodnot x, které již mohou být známé ze vztahu y = mx + b.
- Rozsah known_x může obsahovat jednu nebo více sad proměnných. Pokud použijete jen jednu proměnnou, known_y a known_x mohou být rozsahy libovolného tvaru, musí mít pouze shodné rozměry. Pokud použijete více než jednu proměnnou, known_y musí být vektor (tj. oblast o výšce jednoho řádku nebo šířce jednoho sloupce).
- Není-li uveden known_x , předpokládá se, že jde o matici {1\2\3,...} o stejné velikosti jako u known_y.
const Volitelné. Jedná se o logickou hodnotu, která určuje, zda se má parametr b (absolutní člen) počítat nebo zda se má rovnat nule.
- Pokud má argument b hodnotu PRAVDA nebo není uveden, počítá se konstanta b běžným způsobem.
- Je-li hodnota argumentu b NEPRAVDA, za parametr b se automaticky dosadí 0 a teoretický vztah se zredukuje na argument y = mx.
statistiky Volitelné. Jedná se o logickou hodnotu, která určuje, zda chcete zjistit další regresní statistiky.
- Pokud je stat PRAVDA, vrátí funkce LINREGRESE další regresní statistiky. Výsledkem je, že výsledná matice je {mn;mn-1,...,m1;b; sen,sen-1,...,se1,seb; R2,Sey; F,df; ssreg,ssresid}.
- Je-li hodnota stat NEPRAVDA nebo není-li uvedena, vrátí funkce LINREGRESE pouze koeficienty m a konstantu b.
Dodatečné regresní statistiky jsou:
| Statistika | Popis |
|---|---|
| se1,se2,...,sen | Standardní chyby pro koeficienty m1,m2,...,mn. |
| seb | Standardní chyba pro konstantu b (seb = #N/A, pokud argument b je NEPRAVDA). |
| Pravidlo2 | Koeficient determinace. Porovnává skutečné hodnoty y a jejich odhady, nabývá hodnot od 0 do 1. Pokud je roven 1, existuje v tomto vzorku dokonalá korelace, tj. mezi odhadem a skutečnými hodnotami y není žádný rozdíl. Pokud je koeficient determinace roven nule, znamená to, že regresní rovnice nedokáže předpovídat hodnoty y. Informace o výpočtu2 naleznete v části Poznámky tohoto tématu. |
| sey | Standardní chyba odhadu y. |
| F | F-statistika nebo pozorovaná hodnota F. Pomocí F statistiky můžete určit, zda vztah mezi závislými a nezávislými proměnnými není nahodilý. |
| df | Stupně volnosti. Pomocí stupňů volnosti lze nalézt kritické hodnoty F ve statistické tabulce. Porovnáním hodnot z tabulky s F-statistikou, kterou vrátí funkce LINREGRESE, lze určit úroveň spolehlivosti modelu. Informace o výpočtu hodnoty df naleznete v části Poznámky tohoto tématu. Příklad4 ukazuje použití hodnot F a df. |
| ssreg | Regresní součet čtverců. |
| ssresid | Reziduální součet čtverců. Informace o výpočtu hodnot ssreg a ssresid naleznete v části Poznámky tohoto tématu. |
Následující příklad uvádí pořadí, ve kterém se vracejí dodatečné regresní statistiky.

Poznámky
Libovolnou přímku lze popsat pomocí sklonu a průsečíku s osou y:
Sklon (m):
Chcete-li najít sklon přímky, často psáno jako m, vezměte dva body na přímce, (x1,y1) a (x2,y2); Sklon je roven (y2 - y1)/(x2 - x1).
Průsečík s osou y (b):
Průsečík přímky s osou y, často uváděný jako b, je hodnota y v bodě, kde přímka protíná osu y.
Rovnice přímky je y = mx + b. Jakmile znáte hodnoty m a b, můžete vypočítat libovolný bod této přímky tak, že do rovnice dosadíte hodnotu x nebo y. Lze též použít funkci LINTREND.Máte-li pouze jedinou nezávislou proměnnou x, můžete hodnoty sklonu a průsečíku s osou y získat přímo z následujících vzorců:
Sklon:
=INDEX(LINREGRESE(known_y;known_x;1)
Průsečík s osou y:
=INDEX(LINREGRESE(known_y;known_x);2)Přesnost přímky vypočtené funkcí LINREGRESE závisí na tom, jak je daná množina dat rozptýlená. Čím více jsou data lineární, tím je regresní model funkce LINREGRESE přesnější. Funkce LINREGRESE používá metodu nejmenších čtverců, aby se regrese co nejvíce přiblížila daným datům. Máte-li pouze jedinou nezávislou proměnnou x, budou se m a b počítat podle následujících vzorců:
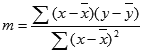
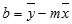
kde x a y jsou výběrové střední hodnoty; To znamená, že x = PRŮMĚR (známá znaky x) a y = průměr (known_y).Funkce LINREGRESE a LOGLINREGRESE pro přizpůsobení křivky dokážou vypočítat nejlepší přímou nebo exponenciální křivku, která odpovídá datům. Musíte se ale rozhodnout, který z těchto dvou výsledků nejlépe odpovídá vašim datům. Pro přímku lze vypočítat funkci LINTREND(known_y;known_x) nebo pro exponenciální křivku hodnotu LOGLINTREND(known_y;known_x). Tyto funkce bez argumentu new_x vrátí matici hodnot y předpovězenou podél této přímky nebo křivky ve skutečných datových bodech. Předpovídané hodnoty pak můžete porovnat se skutečnými hodnotami. Pro vizuální porovnání je můžete použít v grafu oba.
U regresní analýzy počítá aplikace Excel pro každý bod druhou mocninu rozdílu mezi skutečnou hodnotou y v tomto bodě a hodnotou odhadnutou. Součet těchto kvadratických odchylek se nazývá reziduální součet čtverců ssresid. Aplikace Excel pak vypočítá celkový součet čtverců, sstotal. Pokud je argument b = PRAVDA nebo vynechán, rovná se celkový součet čtverců součtu kvadratických odchylek mezi skutečnými hodnotami y a průměrem hodnot y. Pokud argument b = NEPRAVDA, je celkový součet čtverců součtem čtverců skutečných hodnot y (bez odečtení průměrných hodnot y od každé jednotlivé hodnoty y). Regresní součet čtverců ssreg lze vypočítat jako ssreg = sstotal - ssredid. Čím menší je reziduální součet čtverců vzhledem k celkovému součtu čtverců, tím větší je hodnota koeficientu determinace, r2, který je indikátorem toho, nakolik spolehlivě rovnice získaná regresní analýzou vysvětluje vztahy mezi proměnnými. Hodnota r2 se rovná ssreg/sstotal.
V některých případech jeden nebo více sloupců X (předpokládejme, že Y a X jsou ve sloupcích) nemusí mít žádnou další prediktivní hodnotu, pokud existují ostatní sloupce X. Jinými slovy, odstranění jednoho nebo více sloupců X může vést k předpovědím hodnot Y, které budou stejně přesné. V takovém případě by tyto nadbytečné sloupce X měly být z regresního modelu vynechány. Tento jev se nazývá "kolinearita", protože libovolný redundantní sloupec X lze vyjádřit jako součet násobků neredundantních sloupců X. Funkce LINREGRESE kontroluje kolinearitu a odebere z regresního modelu všechny nadbytečné sloupce X, jakmile je identifikuje. Odebrané sloupce X mohou být ve výstupu funkce LINREGRESE rozpoznány jako sloupce s koeficienty 0 a 0 SE. Pokud se jeden nebo více sloupců odebere jako nadbytečné, je funkce df ovlivněna, protože závisí na počtu sloupců X skutečně použitých pro prediktivní účely. Podrobnosti o výpočtu df naleznete v příkladu 4. Pokud se změní df, protože byly odstraněny nadbytečné sloupce X, ovlivní to také hodnoty sey a F. Collinearita by měla být v praxi poměrně vzácná. Jedním z případů, kdy je pravděpodobnější, že k tomu dojde, je situace, kdy některé sloupce X obsahují pouze hodnoty 0 a 1 jako indikátory toho, zda subjekt v experimentu je nebo není členem určité skupiny. Pokud argument b = PRAVDA nebo je vynechán, funkce LINREGRESE efektivně vloží další sloupec X se všemi 1 hodnotami pro modelování průsečíku. Máte-li sloupec s hodnotou 1 pro každý subjekt v případě muže nebo 0 v opačném případě a máte také sloupec s hodnotou 1 pro každý subjekt v případě ženy nebo s hodnotou 0 v případě ženy, je tento druhý sloupec nadbytečný, protože položky v něm lze získat odečtením položky ve sloupci "indikátor muže" od položky přidané funkcí LINREGRESE v dalším sloupci pro všechny hodnoty 1 sečtené funkcí LINREGRESE .
Pokud nejsou z modelu odebrány žádné sloupce X z důvodu kolinearity, vypočítá se hodnota df následujícím způsobem: pokud existuje k sloupců known_x a b = PRAVDA nebo je vynechána, df = n – k – 1. Jestliže argument b = NEPRAVDA, pak df = n - k. V obou případech zvyšuje každý sloupec X odebraný z důvodu kolinearity hodnotu df o 1.
Zadáváte-li jako argument maticovou konstantu (například konstantu known_x), oddělujte hodnoty v řádku středníky a jednotlivé řádky symboly svislé čáry (|). Oddělovače se mohou lišit podle místního nastavení.
Všimněte si, že hodnoty y, předpovídané pomocí regresní rovnice, nemusí platit, pokud jsou mimo oblast hodnot y, pomocí kterých jste rovnici vytvářeli.
Algoritmus použitý u funkce LINREGRESE se odlišuje od algoritmu použitého u funkcí INTERCEPT a SLOPE. U neurčitých dat ležících na stejné přímce může rozdíl mezi těmito algoritmy vést k odlišným výsledkům. Pokud jsou třeba datové body argumentu known_y rovné 0 a datové body argumentu known_x rovné 1, jsou výsledky následující:
- Funkce LINREGRESE vrátí hodnotu 0. Algoritmus funkce LINREGRESE vrací přijatelné výsledky pro data ležící na stejné přímce, přičemž v tomto případě lze nalézt alespoň jeden výsledek.
- Funkce SLOPE a INTERCEPT vrátí #DIV/0! . Algoritmus funkcí SLOPE a INTERCEPT hledá pouze jeden výsledek, přičemž v tomto případě může být výsledků několik.
Kromě výpočtu statistických údajů pro ostatní typy regresí pomocí funkce LOGLINREGRESE můžete pomocí funkce LINREGRESE vypočítat oblast dalších typů regrese. Stačí jako řady x a y funkce LINREGRESE zadat funkce proměnných x a y. Například následující vzorec:
=LINREGRESE(hodnoty_y;hodnoty_x^SLOUPEC($A:$C))
funguje, pokud máte jeden sloupec s hodnotami y a jeden sloupec s hodnotami x, které počítají kubickou aproximaci (polynom 3. stupně) ve tvaru:
y = m1*x + m2*x^2 + m3*x^3 + b
Tento vzorec lze upravit a počítat jiné typy regrese. V některých případech však vyžaduje úpravu výstupních hodnot a dalších statistických údajů.Hodnota F-testu vrácená funkcí LINREGRESE se liší od hodnoty F-testu vrácené funkcí FTEST. Funkce LINREGRESE vrátí F-statistiku, zatímco funkce FTEST vrátí pravděpodobnost.
Příklady
Příklad 1 – Sklon a průsečík s osou Y
Zkopírujte vzorová data z následující tabulky a vložte je do buňky A1 v novém listu Excelu. Aby vzorce zobrazily výsledky, vyberte je, stiskněte F2 a potom stiskněte Enter. Pokud potřebujete, můžete přizpůsobit šířky sloupců a zobrazit si všechna data.
| Známé y | Známé x |
|---|---|
| 1 | 0 |
| 9 | 4 |
| 5 | 2 |
| 7 | 3 |
| Výsledek (směrnice) | Výsledek (průsečík s osou y) |
| 2 | 1 |
| Vzorec (maticový vzorec v buňkách A7:B7) | |
| =LINREGRESE(A2:A5;B2:B5;;NEPRAVDA) |
Příklad 2 – Prostá lineární regrese
Zkopírujte vzorová data v následující tabulce a vložte je do buňky A1 nového excelového sešitu. Aby vzorce zobrazily výsledky, vyberte je, stiskněte F2 a potom stiskněte Enter. Pokud potřebujete, můžete přizpůsobit šířky sloupců a zobrazit si všechna data.
| Měsíc: | Prodej |
|---|---|
| 1 | 3 100 Kč |
| 2 | 4 500 Kč |
| 3 | 4 400 Kč |
| 4 | 5 400 Kč |
| 5 | 7 500 Kč |
| 6 | 8 100 Kč |
| Vzorec | Výsledek |
| =SUMA(LINREGRESE(B1:B6; A1:A6)*{9,1}) | 110 000 Kč |
| Na základě prodejů v prvním až šestém měsíci vypočítá odhad prodeje v devátém měsíci. |
Příklad 3 – Vícenásobná lineární regrese
Zkopírujte vzorová data z následující tabulky a vložte je do buňky A1 v novém listu Excelu. Aby vzorce zobrazily výsledky, vyberte je, stiskněte F2 a potom stiskněte Enter. Pokud je to třeba, můžete si přizpůsobit šířku sloupců, abyste viděli všechna data.
| Podlahová plocha (x1) | Počet kanceláří (x2) | Počet vchodů (x3) | Stáří (x4) | Odhadní cena (y) |
|---|---|---|---|---|
| 2310 | 2 | 2 | 20 | $142 000 |
| 2333 | 2 | 2 | 12 | $144 000 |
| 2356 | 3 | 1,5 | 33 | $151 000 |
| 2379 | 3 | 2 | 43 | $150 000 |
| 2402 | 2 | 3 | 53 | $139 000 |
| 2425 | 4 | 2 | 23 | $169 000 |
| 2448 | 2 | 1,5 | 99 | $126 000 |
| 2471 | 2 | 2 | 34 | $142 900 |
| 2494 | 3 | 3 | 23 | $163 000 |
| 2517 | 4 | 4 | 55 | $169 000 |
| 2540 | 2 | 3 | 22 | $149 000 |
| -234,2371645 | ||||
| 13,26801148 | ||||
| 0,996747993 | ||||
| 459,7536742 | ||||
| 1732393319 | ||||
| Vzorec (dynamický maticový vzorec zadaný v A19) | ||||
| =LINREGRESE(E2:E12;A2:D12;PRAVDA;PRAVDA) |
Příklad 4 – Použití statistik F a r2
V předchozím příkladě je koeficient determinace, neboli r2, roven 0,99675 (viz buňku A17 ve výstupu funkce LINREGRESE), což může naznačovat silnou závislost mezi nezávisle proměnnými a prodejní cenou. Pomocí F statistiky můžete rozhodnout, zda tyto výsledky, s tak vysokou hodnotou r2, nejsou nahodilé.
Předpokládejme nyní, že mezi proměnnými ve skutečnosti žádná závislost neexistuje, ale vybrali jste neobvyklý vzorek 11 úředních budov, podle nějž statistická analýza naznačuje silnou závislost. Označení „Alfa“ se používá pro pravděpodobnost chybného závěru o existenci závislosti.
Pomocí hodnot F a df ve výstupu funkce LINREGRESE lze vyhodnotit pravděpodobnost, že je vyšší hodnota F náhodná. Hodnotu F lze porovnat s kritickými hodnotami v publikovaných tabulkách F-distribuce nebo lze pomocí funkce FDIST aplikace Excel vypočítat pravděpodobnost, že je vyšší hodnota F náhodná. Příslušná distribuce F obsahuje stupně volnosti v1 a v2. Pokud n je počet datových hodnot a argument b = PRAVDA nebo chybí, pak v1 = n – df – 1 a v2 = df. (Jestliže argument b = NEPRAVDA, pak v1 = n – df a v2 = df.) Funkce FDIST se syntaxí FDIST(F,v1,v2) vrátí pravděpodobnost, že je vyšší hodnota F náhodná. V příkladu 4 platí, že df = 6 (buňka B18) a F = 459,753674 (buňka A18).
Za předpokladu, že Alfa má hodnotu 0,05, v1 = 11 – 6 – 1 = 4 a v2 = 6, je kritická hodnota F 4,53. Protože F = 459,753674 je mnohem vyšší než 4,53, je mimořádně nepravděpodobné, že je takto vysoká hodnota F náhodná. (Při hodnotě Alfa = 0,05 je třeba hypotézu, že mezi known_y a known_x není žádný vztah, zamítnout, pokud F překročí kritickou úroveň, 4,53.) Pomocí funkce FDIST v Excelu můžete zjistit pravděpodobnost, že je takto vysoká hodnota F náhodná. Například FDIST(459,753674; 4; 6) = 1,37E-7 je mimořádně nízká pravděpodobnost. Po vyhledání kritické hodnoty F v tabulce nebo použití funkce FDIST aplikace Excel lze usoudit, že regresní rovnice umožňuje předpovídat odhadní hodnotu úřední budovy v této oblasti. Nezapomeňte, že je nezbytné použít správné hodnoty stupňů volnosti v1 a v2 vypočítané v předchozím odstavci.
Příklad 5 – Výpočet T-statistiky
Jiný test statistické hypotézy určuje, zda se pro odhad hodnoty úředních budov z Příkladu 3 hodí každý z koeficientů sklonu. Chcete-li například testovat statistickou významnost koeficientu stáří, vydělte -234,24 (sklon pro koeficient stáří) číslem 13,268 (odhad standardní chyby pro koeficient stáří v buňce A15). Následující rovnost udává pozorovanou hodnotu t:
t = m4 ÷ se4 = -234,24 ÷ 13,268 = -17,7
Pokud je absolutní hodnota t dostatečně vysoká, vyplývá z toho, že směrnice umožňuje předpovídat odhadní hodnotu úřední budovy v Příkladu 3. Následující tabulka obsahuje absolutní pozorované hodnoty t pro čtyři proměnné.
Pokud nahlédnete do tabulky v nějaké statistické příručce, najdete v ní, že kritická hodnota t pro dvoustranný test, 6 stupňů volnosti a alfa = 0,05 je 2,447. Tuto kritickou hodnotu lze také zjistit pomocí funkce TINV aplikace Excel. TINV(0,05;6) = 2,447. Jelikož absolutní hodnota t, 17,7, je větší než 2,447, je stáří při odhadu hodnoty úřední budovy důležitou proměnnou. U každé z nezávisle proměnných lze testovat její statistickou významnost podobným způsobem. Následující tabulka uvádí pozorované hodnoty t pro každou z nezávisle proměnných:
| Proměnná | Pozorovaná hodnota t |
|---|---|
| Podlahová plocha | 5,1 |
| Počet kanceláří | 31,3 |
| Počet vchodů | 4,8 |
| Stáří | 17,7 |
Všechny tyto hodnoty mají absolutní hodnotu větší než 2,447, a proto všechny proměnné použité v regresní rovnici jsou významné pro odhad hodnoty úředních budov v této oblasti.