A função GROUPBY permite que você crie um resumo de seus dados por meio de uma fórmula. Ele dá suporte ao agrupamento ao longo de um eixo e agregação dos valores associados. Por exemplo, se você tiver uma tabela de dados de vendas, poderá gerar um resumo das vendas por ano.
Sintaxe
A função GROUPBY permite agrupar, agregar, classificar e filtrar dados com base nos campos especificados.
A sintaxe da função GROUPBY é:
GROUPBY(row_fields,values,function,[field_headers],[total_depth],[sort_order],[filter_array],[field_relationship])
| Argumento | Descrição |
|---|---|
|
row_fields (obrigatório) |
Uma matriz ou intervalo orientado para colunas que contém os valores usados para agrupar linhas e gerar cabeçalhos de linha. A matriz ou o intervalo podem conter várias colunas. Nesse caso, a saída terá vários níveis de grupo de linhas. |
|
Valores (obrigatório) |
Uma matriz ou intervalo orientado para colunas dos dados a serem agregados. A matriz ou o intervalo podem conter várias colunas. Nesse caso, a saída terá várias agregações. |
|
função (obrigatório) |
Uma lambda explícita ou eta reduzida (SUM, PERCENTOF, AVERAGE, COUNT etc.) que é usada para agregar valores. Um vetor de lambdas pode ser fornecido. Nesse caso, a saída terá várias agregações. A orientação do vetor determinará se eles são definidos em linha ou em coluna. |
| field_headers | Um número que especifica se o row_fields e os valores têm cabeçalhos e se os cabeçalhos de campo devem ser retornados nos resultados. Os valores possíveis são: Ausente: automático (padrão) 0: Não 1: Sim e não mostrar 2: Não, mas gerar 3: Sim e mostrar Nota: Assume automaticamente que os dados contêm cabeçalhos com base no argumento de valores. Se o 1º valor for texto e o 2º valor for um número, os dados deverão ter cabeçalhos. Os cabeçalhos de campos são mostrados se houver vários níveis de linha ou grupo de colunas. |
| total_depth | Determina se os cabeçalhos de linha devem conter totais. Os valores possíveis são: Ausente: automático: totais grandes e, sempre que possível, subtotais (padrão) 0: Sem totais 1: Totais gerais 2: Grand e Subtotals -1: Grandes totais no topo -2: Grand e Subtotals no topo Nota: Para subtotais, os campos devem ter pelo menos duas colunas. Há suporte para números maiores que 2, desde que o campo tenha colunas suficientes. |
| sort_order | Um número que indica como as linhas devem ser classificadas. Os números correspondem às colunas em row_fields seguidas pelas colunas em valores. Se o número for negativo, as linhas serão classificadas em ordem descendente/reversa. Um vetor de números pode ser fornecido ao classificar com base apenas em row_fields. |
| filter_array | Uma matriz 1D orientada à coluna de boolianos que indica se a linha de dados correspondente deve ser considerada. Nota: O comprimento da matriz deve corresponder ao comprimento dos fornecidos para row_fields. |
| field_relationship | Especifica os campos de relação quando várias colunas são fornecidas para row_fields. Os valores possíveis são: 0: Hierarquia (padrão) 1: Tabela Com uma relação de campo Hierarquia (0), a classificação de colunas de campo posteriores leva em conta a hierarquia de colunas anteriores. Com uma relação de campo tabela (1), a classificação de cada coluna de campo é feita de forma independente. Não há suporte para subtotais, pois eles dependem dos dados que têm uma hierarquia. |
Exemplos
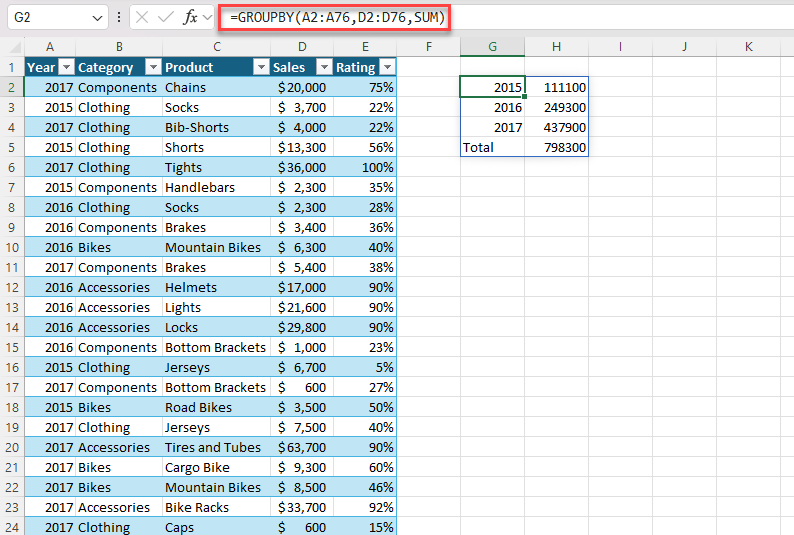
Exemplo 1: use GROUPBY para gerar um resumo do total de vendas por ano.
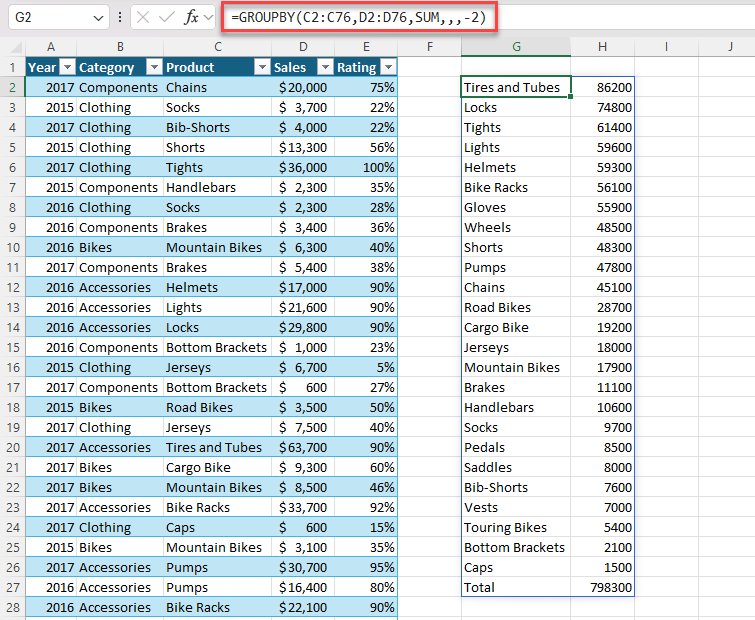
Exemplo 2: use GROUPBY para gerar um resumo do total de vendas por produto. Classificação decrescente por vendas.