Funkcja PIVOTBY umożliwia utworzenie podsumowania danych za pośrednictwem formuły. Obsługuje grupowanie wzdłuż dwóch osi i agregowanie skojarzonych wartości. Na przykład jeśli masz tabelę danych sprzedaży, możesz wygenerować podsumowanie sprzedaży według stanu i roku.
Uwaga
Mimo że może generować podobne dane wyjściowe, funkcja PIVOTBY nie jest bezpośrednio powiązana z funkcją tabeli przestawnej programu Excel.
Składnia
Funkcja PIVOTBY umożliwia grupowanie, agregowanie, sortowanie i filtrowanie danych na podstawie określonych pól wierszy i kolumn.
Składnia funkcji PIVOTBY to:
PRZESTAWNY(row_fields;col_fields;wartości;funkcja;[field_headers];[row_total_depth];[row_sort_order];[col_total_depth];[col_sort_order];[filter_array];[relative_to])
| Argument | Opis |
|---|---|
|
row_fields (wymagane) |
Tablica lub zakres zorientowany na kolumnę zawierający wartości używane do grupowanie wierszy i generowanie nagłówków wierszy. Tablica lub zakres może zawierać wiele kolumn. Jeśli tak, dane wyjściowe będą miały wiele poziomów grup wierszy. |
|
col_fields (wymagane) |
Tablica lub zakres zorientowany na kolumnę zawierający wartości używane do grupowanie kolumn i generowanie nagłówków kolumn. Tablica lub zakres może zawierać wiele kolumn. Jeśli tak, dane wyjściowe będą miały wiele poziomów grup kolumn. |
|
Wartości (wymagane) |
Tablica lub zakres danych zorientowanych na kolumnę, które mają zostać zagregowane. Tablica lub zakres może zawierać wiele kolumn. Jeśli tak, dane wyjściowe będą miały wiele agregacji. |
|
funkcja (wymagane) |
Funkcja lambda lub lambda zmniejszona przez eta (SUMA, ŚREDNIA, ILE.LICZB itp.), która definiuje sposób agregowania wartości. Można dostarczyć wektora lambdas. Jeśli tak, dane wyjściowe będą miały wiele agregacji. Orientacja wektora będzie określać, czy są one rozmieszczone wiersz- lub kolumny mądry. |
| field_headers | Liczba określająca, czy row_fields, col_fields i wartości mają nagłówki oraz czy nagłówki pól mają być zwracane w wynikach. Możliwe wartości to: Brak: Automatycznie. 0: Nie 1: Tak i nie pokazuj 2: Nie, ale wygeneruj 3: Tak i pokaż Uwaga: Funkcja automatyczna zakłada, że dane zawierają nagłówki na podstawie argumentu wartości. Jeśli pierwszą wartością jest tekst, a druga to liczba, zakłada się, że dane mają nagłówki. Nagłówki pól są wyświetlane, jeśli istnieje wiele poziomów grup wierszy lub kolumn. |
| row_total_depth | Określa, czy nagłówki wierszy powinny zawierać sumy. Możliwe wartości to: Brak: Automatycznie: sumy końcowe i, jeśli to możliwe, sumy częściowe. 0: Brak sum 1: Sumy końcowe 2: Sumy końcowe i częściowe -1: Sumy końcowe u góry -2: Sumy końcowe i sumy częściowe u góry Uwaga: W przypadku sum częściowych row_fields musi mieć co najmniej 2 kolumny. Liczby większe niż 2 są obsługiwane , row_field ma wystarczającą liczbę kolumn. |
| row_sort_order | Liczba wskazująca sposób sortowania kolumn. Liczby odpowiadają kolumnom w row_fields a następnie kolumnom w wartościach. Jeśli liczba jest ujemna, wiersze są sortowane w kolejności malejącej/odwrotnej. Wektor liczb może być podany podczas sortowania na podstawie tylko row_fields. |
| col_total_depth | Określa, czy nagłówki kolumn powinny zawierać sumy. Możliwe wartości to: Brak: Automatycznie: sumy końcowe i, jeśli to możliwe, sumy częściowe. 0: Brak sum 1: Sumy końcowe 2: Sumy końcowe i częściowe -1: Sumy końcowe u góry -2: Sumy końcowe i sumy częściowe u góry Uwaga: W przypadku sum częściowych col_fields musi mieć co najmniej 2 kolumny. Liczby większe niż 2 są obsługiwane col_field ma wystarczającą liczbę kolumn. |
| col_sort_order | Liczba wskazująca sposób sortowania wierszy. Liczby odpowiadają kolumnom w col_fields a następnie kolumnom w wartościach. Jeśli liczba jest ujemna, wiersze są sortowane w kolejności malejącej/odwrotnej. Wektor liczb może być podany podczas sortowania na podstawie tylko col_fields. |
| filter_array | Kolumnowa tablica wartości logicznych 1D wskazująca, czy należy rozważyć odpowiadający im wiersz danych. Uwaga: Długość tablicy musi być zgodna z długością tablicy podaną do row_fields i col_fields. |
| relative_to | W przypadku korzystania z funkcji agregacji wymagającej dwóch argumentów relative_to określa, które wartości są podawane drugiemu argumentowi funkcji agregacji. Jest to zazwyczaj używane, gdy funkcja PERCENTOF jest dostarczana do funkcji. Możliwe wartości to: 0: Sumy kolumn (domyślne) 1. Sumy wierszy 2: Sumy końcowe 3: Suma nadrzędna płk 4. Suma wiersza nadrzędnego Uwaga: Ten argument ma wpływ tylko wtedy, gdy funkcja wymaga dwóch argumentów. W przypadku wprowadzenia do funkcji niestandardowej funkcji lambda należy zastosować ten wzorzec: LAMBDA(podzbiór;suma;SUMA(podzbiór)/SUMA(zestaw sum)) |
Przykłady
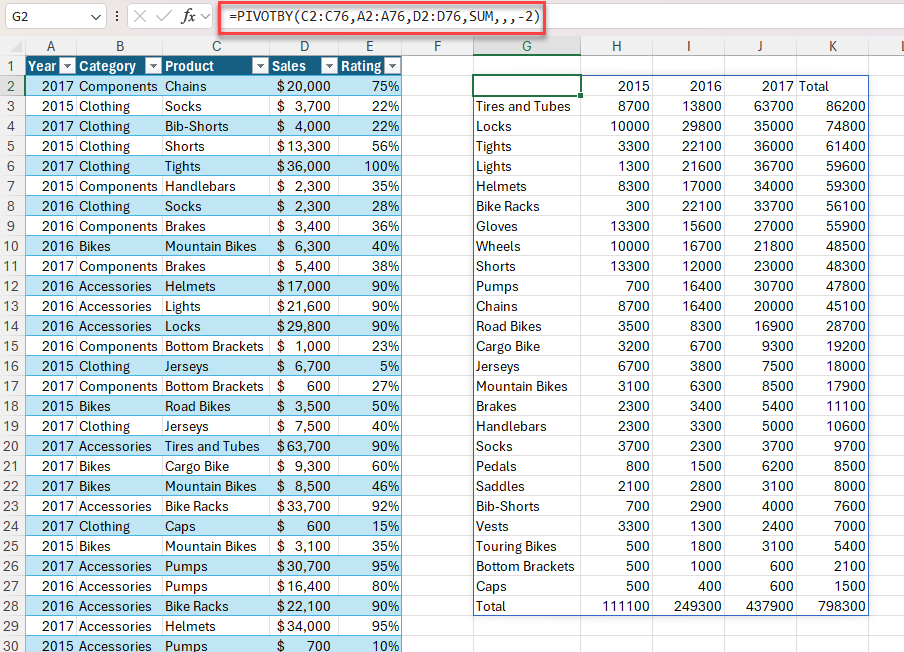
Przykład 1. Użycie funkcji PIVOTBY w celu wygenerowania podsumowania całkowitej sprzedaży według produktu i roku.
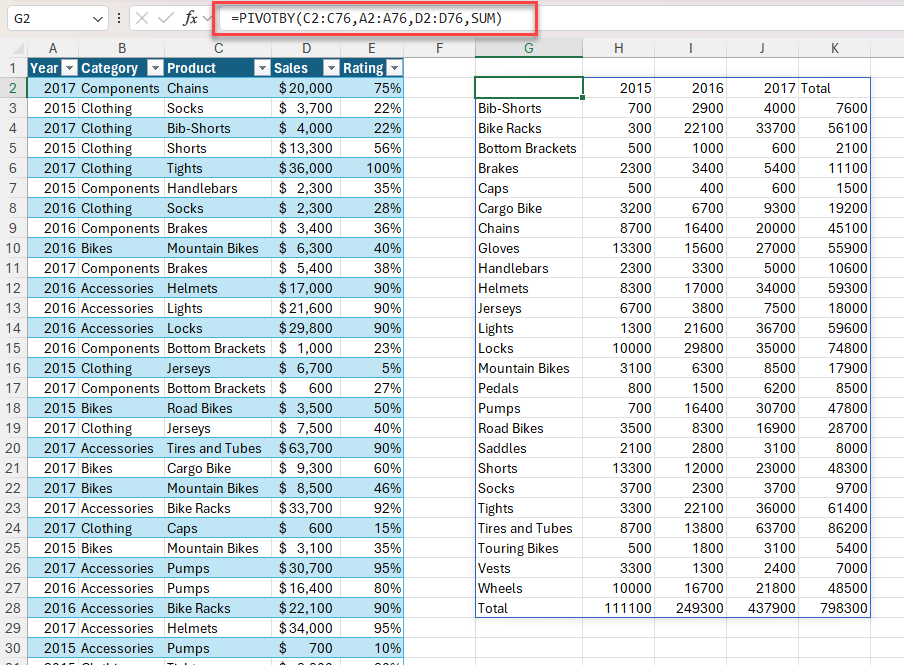
Przykład 2. Użycie funkcji PIVOTBY w celu wygenerowania podsumowania całkowitej sprzedaży według produktu i roku. Sortuj malejąco według sprzedaży.